本机环境
- MacOS
- Python 2.7.15 :: Anaconda custom (64-bit)
- mysql
- pymsql
- sqlalchemy
- pandas
- datagrip(数据库可视化)
- pycharm/CodeRunner (二者都可以编写python脚本)
1. Mac安装MySQL数据库
1.1下载的.dmg镜像
官网地址: https://dev.mysql.com/downloads/mysql/
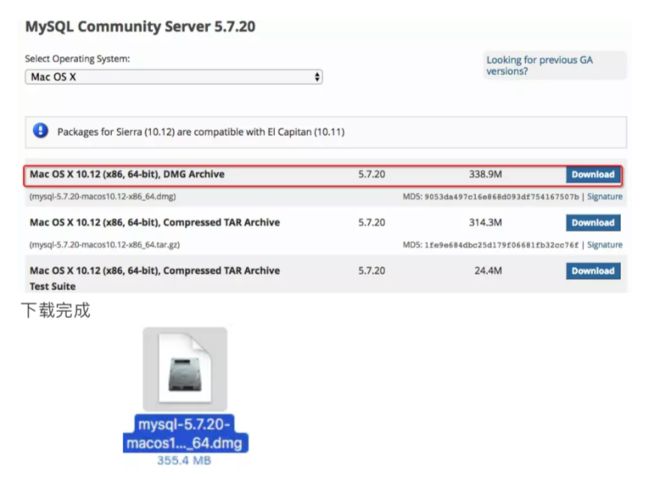
1.2 运行安装镜像文件
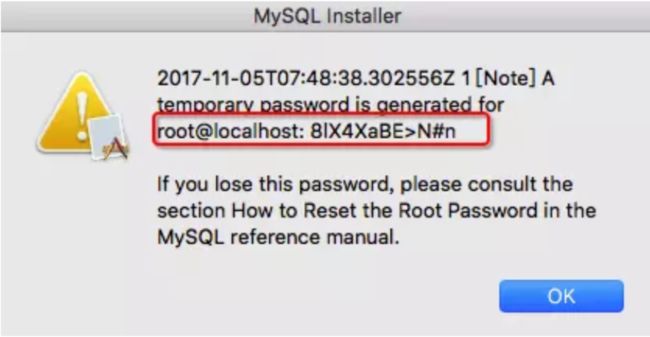
- 双击 一路直接 安装 安装完成会弹框 !!!!需要记住默认密码 8lX4XaBE>N#n
1.3 开启mysql服务
- 打开系统设置,查看安装好的MySQL 开启服务

提示默认的安装路径: /usr/local
1.4 执行终端输入命令
mysql -u root -p
提示命令找不到,需要配置环境变量
使用vim编辑器,编辑~/.bash_profile,添加PATH=$PATH:/usr/local/mysql/bin并保存。再执行命令source ~/.bash_profile立即生效。
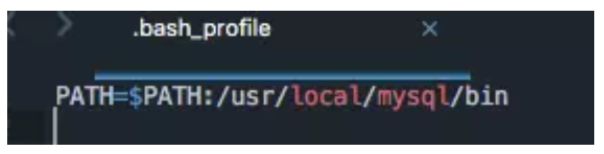
接下来就可以登录了。
由于默认生成的密码比较复杂,下面修改root默认的密码
# 登录进数据库(mysql -u root -p),输入命令
SET PASSWORD = PASSWORD('新密码');
2. Mac数据库可视化工具
- DataGrip(学生账号可以免费使用) / Navicat For MySQL(两者都可以选择)**
3. 终端操作数据库(如果已经有可视化工具,此部分可以忽略)
#连接数据库
mysql -u root -p
#查看已有的数据库 一定要有;
show databases;
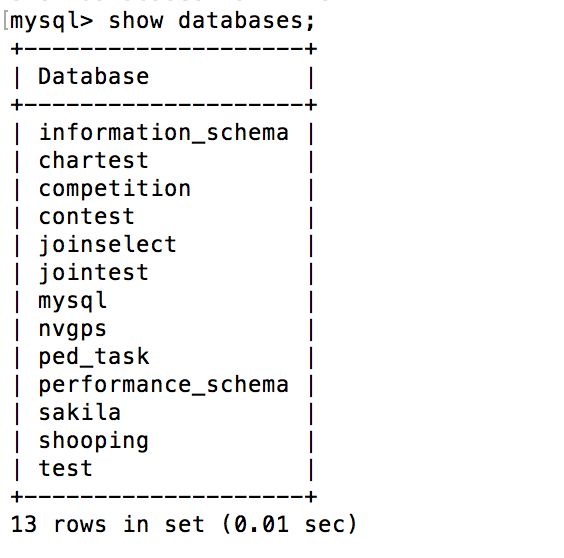
#选择使用哪一个数据库
use competition;
# 查看数据库表
show tables;

具体终端操作数据库更多可参看:http://www.runoob.com/mysql/mysql-tutorial.html
4. 连接以及操作数据库
4.1 anaconda创建环境
注:基于anaconda的python环境,使用conda创建一个个独立的虚拟环境(可以创建多个)对于在这个环境安装的一些包,其实不会影响其他环境(有的时候不同的项目对于相同的python模块需要不同的版本,使用conda创建不同的虚拟环境就可以解决这个问题)。也可以不进行创建直接进入到安装包的步骤即可,对于更多conda虚拟环境相关的操作,请参考:https://blog.csdn.net/ITLearnHall/article/details/81708148
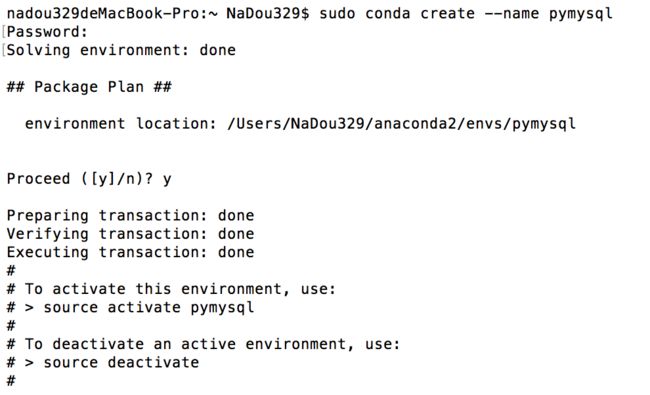
# 其中pymsql任意即可,只是自己创建的一个环境名称--pymysql
# your_env_name(即虚拟环境的名称)文件可以在Anaconda安装目录envs文件下找到
sudo conda create --name pymysql
4.2 anaconda激活环境
source activate pymysql

4.3 安装python包文件
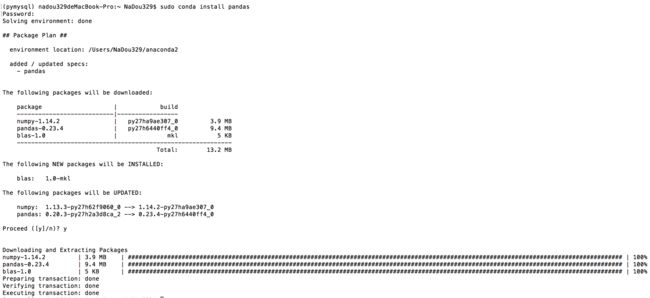
- 安装pandas模块
sudo conda install pandas
- 安装SQLAlchemy模块(提供了SQL工具包及对象关系映射(ORM)工具,SQLAlchemy模块提供了create_engine()函数用来初始化数据库连接)
sudo conda install sqlalchemy
- 安装pymysql模块(连接数据库)
sudo conda install pymysql

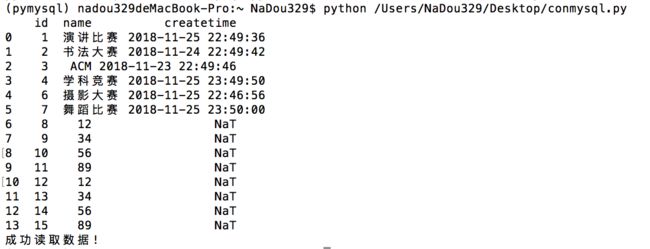
读取数据库内容:新建conmysql.py文件->运行python脚本
先对运行python进行说明:直接查看“6.运行”先行了解。
5. 读写MySQL数据表数据
5.1 pandas中读取MySQL数据库
下面将介绍一个简单的例子来展示如何在pandas中实现对MySQL数据库的读取:
# 导入必要模块
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:123456, 端口:3306,数据库:competition
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/competition')
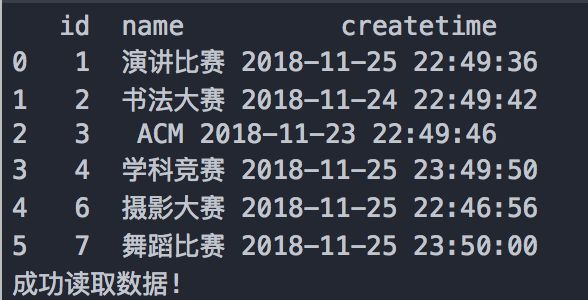
# 查询语句,选出c_user表中的所有数据
sql = "select * from c_type;"
# read_sql_query的两个参数: sql语句, 数据库连接
df = pd.read_sql_query(sql, engine)
# 输出c_type表的查询结果
print(df)
print('成功读取数据!')
read_sql_query()中可以接受SQL语句,包括增删改查。但是DELETE语句不会返回值(但是会在数据库中执行),UPDATE,SELECT等会返回结果.
5.2 数据写入数据库
DataFrame.to_sql(name, con, flavor='sqlite', schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
例如:data.to_sql('c_type',engine,if_exists='append',index = False),把数据写入c_type表中。
if_exists='replace',如果数据库中有c_type表,则替换。
if_exists='append',如果数据库中有c_type表,则在表后面添加。
if_exists='fail',如果数据库中有c_type表,则在写入失败。
chunksize,如果data的数据量太大,数据库无法响应可能会报错,这时候就可以设置chunksize,比如chunksize = 1000,data就会一次1000的循环写入数据库。
# 新建pandas中的DataFrame, 只有name列
df = pd.DataFrame({'name':[12,34,56,89]})
# 将新建的DataFrame储存到MySQL中的c_type数据表,不储存index列,if_exists有三个参数{‘fail’, ‘replace’, ‘append’}, 默认‘fail’;数据量很大的话可以设置chunksize。因为c_type已经存在所以会直接向c_type数据表中插入数据
df.to_sql('c_type', engine, index= False,if_exists='append')
# 新建pandas中的DataFrame, 只有id,name列
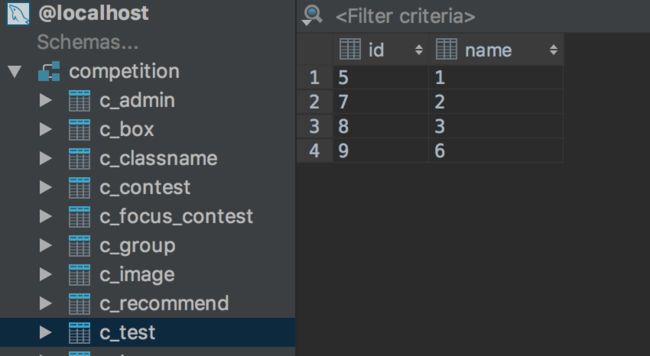
df = pd.DataFrame({'id':[5,7,8,9],'name':[1,2,3,6]})
# 将新建的DataFrame储存为MySQL中的数据表,不储存index列
df.to_sql('c_test', engine, index= False)
查看数据库,可以看到新建了数据表c_test,并插入了数据
5.3 CSV文件写入到MySQL中
# 导入必要模块
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/competition')
# 读取本地CSV文件
df = pd.read_csv("/Users/NaDou329/Desktop/classname.csv", sep=',')
# 将新建的DataFrame储存为MySQL中的数据表,不储存index列
df.to_sql('c_csv', engine, index= False)
print("成功!")

注:对于pandas更多操作数据请参考文档:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html?highlight=sql#pandas.DataFrame.to_sql

6. 运行
6.1 终端运行
如果没有在虚拟环境安装相关的python模块,而是直接安装的方式,直接在终端运行conmysql.py脚本即可
# 脚本名称conmysql.py
#python后面跟的是脚本所在位置,使用这种方法可以直接在终端输入python,然后把文件拖拽到终端里面即可后去脚本位置,最后回车即可
python conmysql.py
如果创建了虚拟环境,直接在激活虚拟环境后,在终端同样python conmysql.py即可
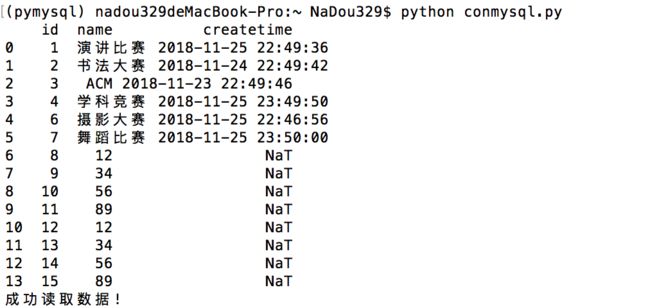
上面是我的python脚本在我的home下,如果我把它放在桌面:
6.2 pycharm运行(可以选择切换到相应的python环境)