首先思考一个问题:hadoop分布式集群的主要工作在什么地方?
HDFS分布式文件存储的集群,分布式文件存储要保持文件的一致性,这个是一个重点,那么怎么搭建才能保持一致性呢,这个问题前辈们已经给出了解决方案,总结为一张图
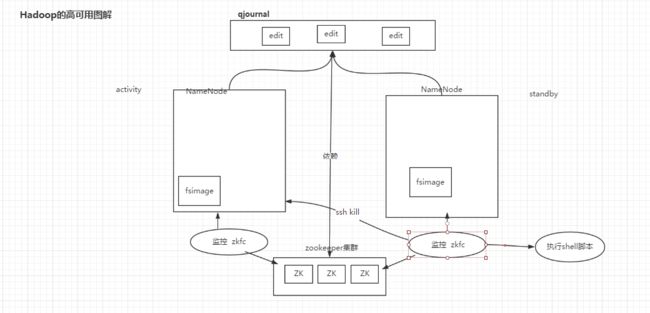
解释一下上图:
1,两个NameNode只有一个提供服务两一个处于休眠
2,当提供服务的节点发生异常的时候,通过监控zkfc,修改zookeeper的临时节点,另一个监控zkfc,感知到之后,就会发出ssh kill指令将异常的NameNode杀掉,若在杀掉的过程工出现超时或者其他异常,会执行一个脚本(这个脚本是我们自己的脚本,是为了可靠的将异常服务杀掉)后,启动standby的节点,启动之后状态位activity
3,若手动将异常节点启动,则是一个standyby,很好理解,先来后到嘛,哈哈···
理解了之后,继续开车
我是这么规划的,没有服务器就用虚拟机来代替,电脑性能有限,考虑一番之后用7台虚拟centos来搭这个集群,也可以是10台,考虑到内存吃紧,7台,说明过程就行了
1,my02 namenode zkfc
2,my03 namenode zkfc
3,my04 resourceManager
4,my05 resourceManger
5,my06 zookeeper journalnode datanode nodemanager
6,my07 zookeeper journalnode datanode nodemanager
7,my08 zookeeper journalnode datanode nodemanager
这样分布是有原因的,就是datanode要和nodemanager在一个服务器上,这是遵循的数据本地性,这个原则spark也不例外,就是计算,数据在一起
开始!
1,解压hadoop
2,vi hadoop_env.sh
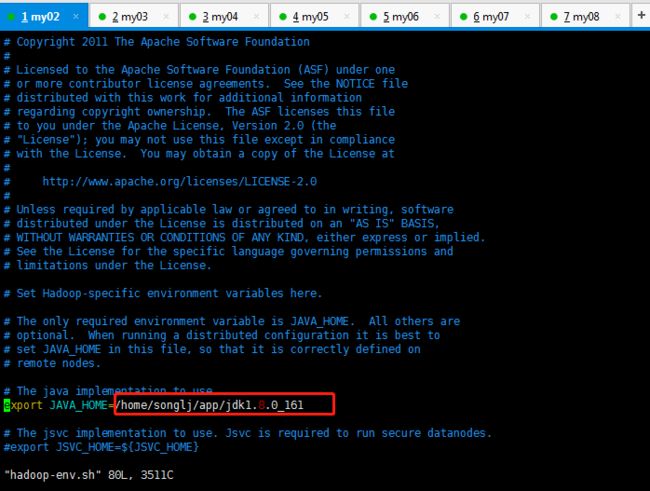
修改core-site.xml
fs.defaultFS
hdfs://ns/
hadoop.tmp.dir
/home/songlj/app/hadoop-2.4.1/tmp
ha.zookeeper.quorum
my06:2181,my07:2181,my08:2181
修改hdfs-site.xml
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
my02:9000
dfs.namenode.http-address.ns.nn1
my02:50070
dfs.namenode.rpc-address.ns.nn2
my03:9000
dfs.namenode.http-address.ns.nn2
my03:50070
dfs.namenode.shared.edits.dir
qjournal://my06:8485;my07:8485;my08:8485/ns
dfs.journalnode.edits.dir
/home/songlj/app/hadoop-2.4.1/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/songlj/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
修改mapreduce mapred-site.xml
mapreduce.framework.name
yarn
修改yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
my04
yarn.resourcemanager.hostname.rm2
my05
yarn.resourcemanager.zk-address
my06:2181,my07:2181,my08:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
3,配置各个节点之间的无秘登录
ssh-keygen -t rsa
197 ssh-copy-id my02
198 ssh my01
199 ssh my02
200 ssh-copy-id my03
201 ssh-copy-id my04
202 ssh-copy-id my05
203 ssh-copy-id my06
204 ssh-copy-id my07
205 ssh-copy-id my08
4,修改hdfs的slave文件vi slaves
my06
my07
my08
~
5,拷贝到各个服务器上
scp -r hadoop-2.4.1/ my03:/home/songlj/app
244 scp -r hadoop-2.4.1/ my04:/home/songlj/app
245 scp -r hadoop-2.4.1/ my05:/home/songlj/app
246 scp -r hadoop-2.4.1/ my06:/home/songlj/app
247 scp -r hadoop-2.4.1/ my07:/home/songlj/app
248 scp -r hadoop-2.4.1/ my08:/home/songlj/app
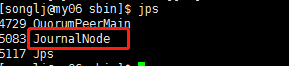
6,在06,07,08上启动journalnode
./hadoop-daemon.sh start journalnode
成功标志
7,格式化nameNode
./hadoop namenode -format
8,拷贝到my03
scp -r tmp/ my03:/home/songlj/app/hadoop-2.4.1/
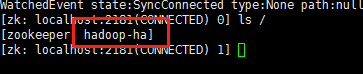
9,格式化zkfc
[songlj@my02 bin]$ hdfs zkfc -formatZK
会在zk下建节点
10,启动hdfs
重点,容易忽视一定要先启动zk,因为zkfc需要注册到zk上去,这个容易忽视导致zkfc起不来,启动zk,看上一篇
[songlj@my02 ~]$ start-dfs.sh
11,my04启动yarn
start-yarn.sh
12,启动my05的resourcemanager
到app/hadoop-2.4.1/sbin下执行
./yarn-daemon.sh start resourcemanager
13,关闭防火墙
sudo service iptables stop
287 sudo service iptables status
14,启动关闭
sudo chkconfig iptables off
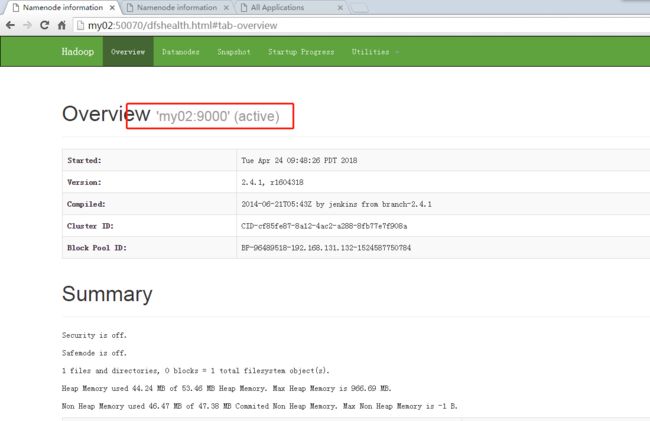
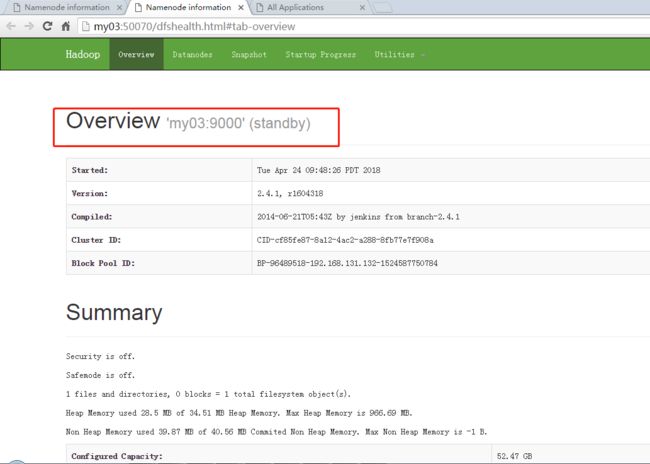
看效果: