本文部分资料摘自我曾经读过的文章,具体是谁写的,我也记不清了。这里我只做一个备忘。
如果想要深入了解Redis,建议直接去看Redis的官网。https://redis.io/documentation 需要一点英文基础。当然也可以采用google 自动翻译。
如果想要用,查看命令,建议参见http://doc.redisfans.com/ 手册足够使用。
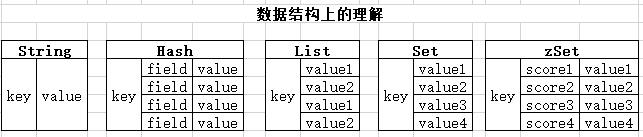






Redis 本身是c语言开发,支持高并发的内存存储数据库,其主要支持五种可便于大家使用的数据结构:
String-字符串
Hash-哈希表
List-链表
Set-集合
SortedSet-有序集合(zSet)
Redis 本身是K-V(Key-Value)结构的,所以大家在看资料的时候,一切可以用在Key上的命令是针对上述数据结构均有效的,请避免将Key与String混淆理解。
[我们在用的Redis版本为3.2.3]
针对Key的命令:
DEL ${key} 删除一个key对应的数据,时间复杂度是O(M) M是key下的元素个数,注:需要注意,如果redis内的key的结构很大,内存占用也很大,需要使用一些特殊策略进行删除,否则可能会引发Server的阻塞。
EXISTS ${key} 判断key是否存在,时间复杂度是O(1),存在返回1,不存在返回0,因为Redis本身是单线程的,exists & get等命令未经特殊处理均为分批执行的,可能存在一定时间差,因此不推荐先exists再get的操作
EXPIRE ${key} ${second} 设置一个key的过期时间,过期后对应的key将被删除。时间复杂度为O(1)。设置成功返回1,设置失败返回0(不存在的key)。Redis自身服务无法保证精确过期,但是可以精确在1ms之内,想要修改一个key的过期时间,重新设置一次EXPIRE即可覆盖,增加值元素,修改值元素内容均无法修改过期时间。如果想移除对应的过期时间可以通过PERSIST ${key}命令实现,这样对应的key就是永不过期了。 当然,对于一些特定时间过期的,可以使用EXPIREAT ${key} ${timestamp} timestamp为秒为单位的unix时间戳,时间复杂度,返回值特性等均与EXPIRE一样。其中EXPIRE,EXPIREAT均以秒为单位,若想更加精确的数据可以使用,PEXPIER,PEXPIREAT 这两个命令的单位为毫秒。
(以前我们经常会面试一些候选人一个问题,如果我们期望一个订单在30min没有支付成功就要自动“关单”,这个功能如何完成,很多人都想到了用EXPIRE的过期特性,但是也说不出其如何使用,有些稍微看过一些Redis资料的人,也能说出来,可以配置Redis的配置来实现Rediskey过期自动通知,不过,这些说出这个答案的人基本都是为了用Redis而用Redis,并没有考虑到Redis内过期删除策略,以及其事件发布订阅策略)
(Redis过期策略主要由三个:
1、被动删除:实际上Redis内的数据没有删除,而是在操作或者获取这个key的时候,发现这个key已经过期,则直接标记其删除
2、主动删除:Redis每秒进行10次主动删除策略(可自定义,Redis作者建议不超过100),每次获取100个有过期时间的key,然后删除其已经过期的key,若删除掉的key超过了25个,则再获取删除一次。存储空间爽了一点点,CPU也还能够扛得住
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* CPU max % for keys collection */
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
3、存储空间超过了最大限制
)
(Redis过期事件配置方式:
详情可参考:https://blog.csdn.net/zhu_tianwei/article/details/80169900
可在配置文件中配置:notify-keyspace-events “Kx”
K键空间通知,所有通知以 keyspace@ 为前缀,针对Key [如果开启的是某一专项或某几专项的事件,建议使用这个,更方便观测key]
------举例:删除sampleKey ,则进行publish __keyspace@0__:sampleKey del
E键事件通知,所有通知以 keyevent@ 为前缀,针对event
------举例:删除 sampleKey ,则进行publish __keyevent@0__:del sampleKey
gDEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知
$字符串命令的通知
l列表命令的通知
s集合命令的通知
h哈希命令的通知
z有序集合命令的通知
x过期事件:每当有过期键被删除时发送
e驱逐(evict)事件:每当有键因为 maxmemory 政策而被删除时发送
A参数 g$lshzxe 的别名,相当于是All
)
(Redis内事件通知机制,即命令publish<->subscrible/psubscribe,利用psubscribe这个机制,我们就能监控其key过期的事件了,不过如果我们想要通过写代码做监控的话,这里的pub sub 和持久化类型的MQ还是不同的,这里如果没有订阅者/消费者在线的话,事件发出也就发出了,是会错过的,另外,刚刚所说的过期机制也不会很准确的体现其过期时间的。当开启了subscribe或者psubscribe之后,对应的client就属于阻塞等待状态了。因此还是不推荐使用这种机制。
)
TTL ${key} 获取key对应的剩余存活时间(秒单位),返回值:key不存在:-2,key不失效:-1;≥0:剩余时间。时间复杂度为O(1),若想精细到毫秒,可以使用命令:PTTL ${key}
KEYS ${pattern} 可以获取满足表达式的所有KEY,时间复杂度为O(M),M为数据库中的key个数,通常禁用。
TYPE ${key} 获取一个key对应值的类型,时间复杂度为:O(1),返回值为:string,hash,list,zset,set,none(不存在的key时)
RENAME ${key} ${newkey} 将key改名为newkey,并将其值过期时间等一同转义至newkey,如果${newkey}已经存在,则直接覆盖。时间复杂度O(1)。建议命名时考虑好,避免修改操作,减少key使用遗漏。RENAMENX ${key} ${newkey} 当newkey不存在时,将key改名为newkey。时间复杂度O(1)。返回值:1:成功;0:newkey已存在。
DUMP RESTORE # 序列化,反序列化;序列化手段不限于String类型数据,序列化操作会与Redis自身RDB版本有关,若期望通过此来做双层持久需要注意RDB版本升级将要影响数据结论
MIGRATE,MOVE 移动key 跨服务,跨DB
RANDOMKEY 随机返回一个存在的key
OBJECT 主要用于看一个key的使用情况:
OBJECT REFCOUNT ${key} 返回给定 key 引用所储存的值的次数。此命令主要用于除错。
OBJECT ENCODING ${key} 返回给定 key 锁储存的值所使用的内部表示(representation)。
OBJECT IDLETIME ${key} 返回给定 key 自储存以来的空转时间(idle, 没有被读取也没有被写入),以秒为单位。 即自上次处理至今的时间。
SORT ${key} [BY][LIMIT][GET][ASC|DESC][ALPHA] ,用于对一个集合类型的key里的value排序。 SORT 默认排序的内容为数值型;若先参照字符型排序,需要使用ALPHAO(N+M*log(M)), N 为要排序的列表或集合内的元素数量, M 为要返回的元素数量。若不排序,时间复杂度 O(N)。其余关键字参见下面举例理解:
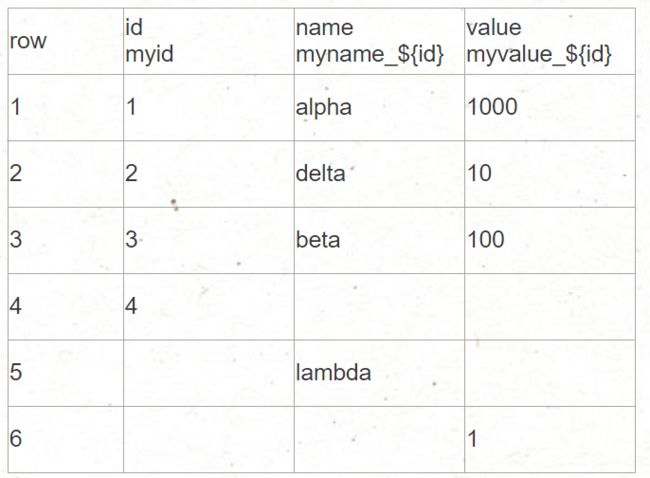
构建一个上述的表格
LPUSH myid 1
LPUSH myid 2
LPUSH myid 3
LPUSH myid 4
SET myname_1 alpha
SET myname_2 delta
SET myname_3 beta
SET myname_5 lambda
SET myvalue_1 1000
SET myvalue_2 10
SET myvalue_3 100
SET myvalue_6 1
---ok 构建完成
只对myid进行排序:
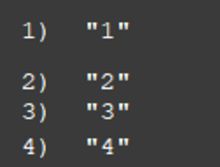
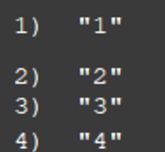

由上述例子可以看出,SORT默认使用ASC排序,其中以数值元素为比较值


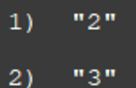
SORT myid limit 0 0 无结果
SORT myid limit 4 1 无结果

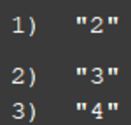
由上述例子可以看出来,LIMIT 用法比较像MySQL的limit用法, LIMIT ${offset} ${count},但这里的limit offset传入负数时,会将其直接视为0,但是count若传入负数,则会全部查询出来

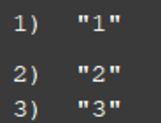
上述例子可以看出,排序后,也可以通过正则表达式,按照排序好的value,匹配至新key,进行获取数据 ,因此这样得到的数据类似于权值排序结果,但若集合中的值,不存在对应的匹配的key的话,则对应部分的返回为null
当然,对应外部键也可以用hash结构存储,对应的命令可变为:
SORT myid GET myhash_*->name

可见其结果为按照匹配到的新key对应的值进行排序,未获取到对应匹配的值视为最小
注:若by 对应的key不存在,则不进行排序,这类操作可以用于关联查询
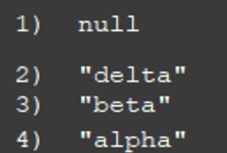
按myvalue排序,再获取对应的myname
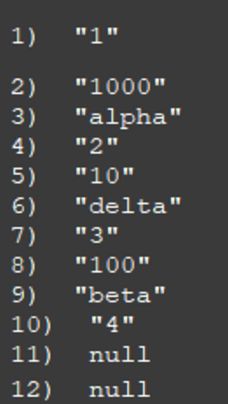
可以根据上述例子看出,通过myid对应值进行排序获取多个键匹配值可以写多个GET 进行处理,其中 GET # 表示获取自身值
SCAN ${游标} [$match}] [${count}] 针对全部key
HSCAN key ${游标} [$match}] [${count}] 针对hash结构key内fields
ZSCAN key ${游标} [$match}] [${count}] 针对SortedSet结构key内所有元素
SSCAN key ${游标} [$match}] [${count}] 针对Set结构key内所有元素
${游标} 从0 开始 从0 结束,每次SCAN Redis都会返回给你下一个游标,若为0,则表示结束,若不为0,哪怕返回集合是空的也不是结束
${match}就是通配表达式
${count}表示本次扫描本次返回的数据集元素个数,默认是10,每次均可修改
注:SCAN命令为增量式获取,有可能获取到重复元素
RedisKey的命令
Redis数据结构
Redis数据结构的命令