1.createStore(reducer,preloadedState,enhance)
参数:
reducer:给出action和当前state,返回下一个新的state;
initState:初始化state, 如果reducer是使用combineReducer提供的方法,
那么state一定是和reducer的key值一样的结构对象;
enhancer:必须是fun,不然会报错,高阶函数,返回强化过的高阶函数,
就是将creatStore的能力增强 。
返回:
store:可供读写并且监控改变的store,当然写只能通过dispatch(state, action)了
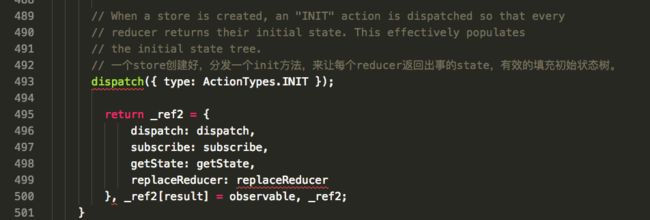
注册了4个方法:
getState()
获得store中当前的状态。
dispath(action)
分发一个action,并返回这个 action,这是唯一能改变 store 中数据的方式。
subscrible(listener)
注册一个监听者,他在 store 发生变化时被调用。
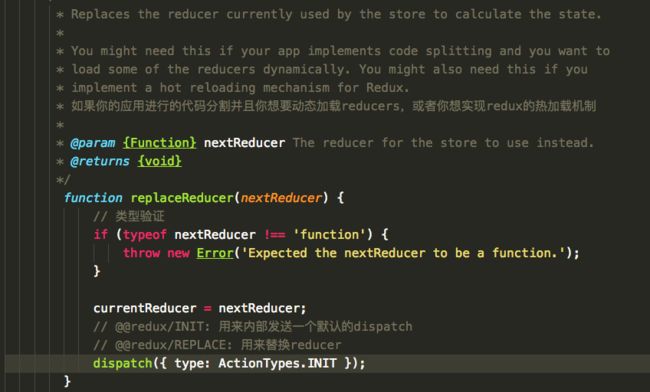
replaceReducer(nextReducer)
更新当前 store 里的reducer
createStore就是一个大的闭包,就是一个函数里面有别的函数的话,那么在外部调用里面的函数,那么在外部函数的state,reducer,listener都不会被销毁,就一直存在,里面的函数可以对公共方法变量进行读写。。。我可真是一个小机灵鬼~~~
源码大概200行,很多注释,我翻译一下


2.combineReducers(reducers):把reducer函数检查过滤,合成一个新的函数,dispatch的时候,挨个执行每个reducer
接收reducers对象(key-value),以reducers的name作为key。

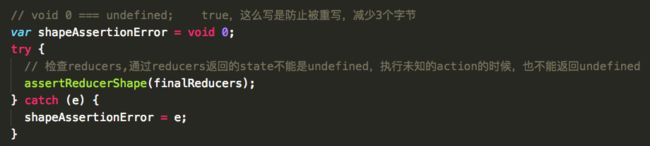
过滤掉value是undefined的reducers,生成一个新的reducers对象。finalReducers

通过assertReducerShape检查错误的reducers,检查形式是:
①reducer(undefined, { type: ActionTypes.INIT }),先检验initialState返回的是不是undefined; ②reducer(undefined, { type }),检验随机的一个type是否会返回undefined
返回一个函数combination,这个方法才是最终的reducer,因此dispatch的时候,是调用了这个函数。该方法接受state和action两个参数,每次都会逐个调用每一个小的reducer,返回一个单独的{key-value}对象state,key与reducer的key保持一致。

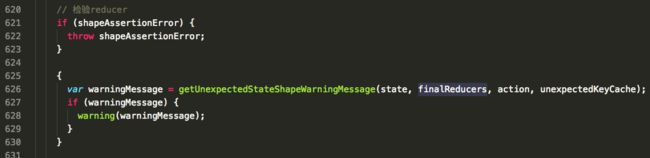
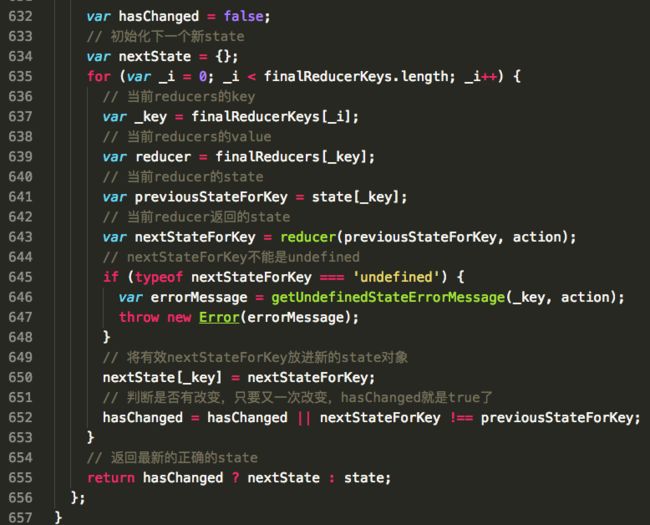
这点代码的意思是,每个reducer(prevState,action)返回的就是新的state[key],最终每个reducer给state一个key,组成一个完整的state。
重点:
①state只有一个,就是createStore创建出来的state,state的属性有几个是根据combinReducer有几个reducer决定的;
②执行上面方法的时候,穿进去的state是对应当前reducer的state,比如state.todos / state.visibility;
附上参考文档:https://blog.csdn.net/bgk083/article/details/50867365
3.applyMiddleware
创建一个store强化器,能提供中间件去dispatch action。
看代码就是。。。先创建createStore,再循环参数,将state和dispatch作为参数传入,依次调用中间件,将上次的调用返回的store传入下一个中间件。
redux执行同步的数据修改是没问题的,但是异步的数据修改,需要redux-thunk中间件,就是action发出后过一段时间再执行reducer。
中间件会被放在applyMiddleware()中,在applyMiddleware方法中,遍历所有的middleware,将state和dispatch作为参数传入,依次执行,最后才dispatch action,这就实现了,在action和reducer之间增加了功能,可以做异步处理的地方。
4.bindActionCreators
bindActionCreators唯一的用处就是在子组件未察觉redux的情况下,将dispatch传递给子组件。
5.compose
深度执行函数,从右到左,依次执行。applyMiddleware 机制的核心在于组合 compose,将不同的 middlewares 一层一层包裹到原生的 dispatch 之上,
compose(a, b, c)
c( b( a(...arguments) ) )
6.react-redux
redux实现了状态数据的集中管理,dispatch时候,redux里面的数据确实变了,但是react并没有变化,所以还要监听state变化,然后setState,那么就是左右应用store的子组件都要监听state的变化,麻烦!!!
react-redux就是为此而生,它提供Provider和connect。顶层组件必须包裹在Provider里面,并且store必须作为参数放在Provider里面。
6.1 Provider
提供3中方法:
getChildContext:外部store对象放入context中,使子孙组件能够直接访问
render:渲染子级元素,使整个应用成为provider的子组件
constructor:初始化获得props中的store
provider会将由props传入的store,渲染到自己的context上,再由connect取出context的内容,渲染到子组件上
6.2 connect
connect是高阶组件,接受参数,吐出一个高级的组件,connect接受两个方法一个组件。
connect(mapStateToProps, mapDispatchToProps)(component)。
connect会取出context里的store,然后把store里面的数据映射到当前组件的props,使得组件只要在props使用数据和方法就可以,不用再去context里面取值+监听变化+重新渲染视图。
const mapStateToProps (state) {
return {
data1: state.data1,
data2: state.data2,
...
}
}
这里面的参数state,是在connect函数里面调用mapStateToProps的时候传进去的,所以不会报state未定义的错。const mapDispatchToProps (state) {
return {
changeColor: (color) => {
dispatch({ type: 'CHANGE_COLOR', themeColor: color })
} ,
changeText: (text) => {
dispatch({ type: 'CHANGE_TEXT', themeText: text })
}
...
}
}
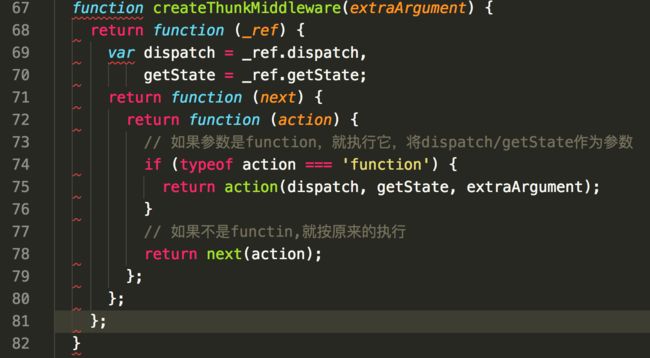
7.redux-trunk
可以接受一个返回函数的action creator。如果这个action creator 返回的是一个函数,就执行它,如果不是,就按照原来的next(action)执行
8.柯里化curring
一个函数可以接受很多参数,柯里化函数,就是只接受一个参数,利用返回的函数,来处理剩下的参数
fn(a, b, c, d) => fn(a)(b)(c)(d)
fn(a, b, c, d) => fn(a, b)(c)(d)
fn(a, b, c, d) => fn(a)(b, c, d)
fn(a, b, c, d) => fn(a)(b)(c)(d)()
fn(a, b, c, d) => fn(a);fn(b);fn(c);fn(d)