Deep Interest Evolution Network(DIEN)专题1:论文解析Deep Interest Evolution Network for Click-Through Rate
算法概述
Deep Interest Evolution Network(DIEN)是在Deep Interest Network(DIN)基础上的改进方法,其初衷是为了解决当前CTR预估中存在的一些问题:
1.大多数的方法缺少兴趣模型,直接把用户的行为当作用户的兴趣,缺少对具体行为背后隐含的兴趣做模型化处理;
2.用户的兴趣在不断发生变化,之前的大多数方法缺少对用户兴趣变化趋势的思考。
DIEN通过设计兴趣提取层(Interest Extractor Layer)来获取用户历史行为的兴趣,通过在这一层添加一个额外的损失函数来监督每一步的兴趣提取。
在电商系统中,用户的兴趣非常广泛,DIEN通过加入兴趣进化层(Interest Evolving Layer)来获取与目标推荐相关的兴趣进化过程。
基本的网络结构
深度兴趣网络详解中已经给出了基本模型结构的介绍,DIEN和DIN的基本模型结构是类似的,下面还是具体介绍一下。
特征表示(Feature Representation)
文章中的线上系统有四类特征:User Profile(性别、年龄等), User Behavior(访问过的商品id), Ad(推荐的商品(target item)id)and Context(时间等特征)。每一个类里面的每一个具体特征都是一个one-hot编码,注意这和之前的DIN是不一样的,之前的DIN可能有muti-hot编码。四类特征所有具体特征的one-hot编码拼接到一起分别得到向量:![]() ,
,![]() ,
,![]() 和
和![]() 。
。
对于序列化的CTR模型,每一个具体特征都包含一个行为的列表,每一个行为对应一个one-hot编码(比如浏览过的商品每一个商品就是一个one_hot编码,所有浏览过的商品构成一个列表List),可以被表示为:
![]()
![]() 是one-hot编码向量,对应的是用户的第
是one-hot编码向量,对应的是用户的第 个行为,
个行为, 是用户的历史行为数,
是用户的历史行为数, 为用户所有可能点击的商品数总和。
为用户所有可能点击的商品数总和。
基本的模型结构
大多数Deep CTR模型都是基于embedding&MLP这一基本结构构建的,下面介绍下基本结构的主要组成部分:
embedding 层:每一个具体特征对应一个嵌入矩阵(embedding matrix),例如访问商品的嵌入矩阵可以表示为:![]() ,即每一个商品对应一个
,即每一个商品对应一个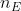 维的嵌入向量。具体的来说,对于行为特征
维的嵌入向量。具体的来说,对于行为特征![]() ,其对应的嵌入式向量为
,其对应的嵌入式向量为![]() ,那么按照时间序排列的嵌入向量列表可以表示为:
,那么按照时间序排列的嵌入向量列表可以表示为:![]() 。同理,推荐物品相关特征的嵌入向量列表可以表示为:
。同理,推荐物品相关特征的嵌入向量列表可以表示为:![]() 。
。
MLP
首先,同一类特征的嵌入式向量首先进行池化操作,随后将不同类的所有池化向量连接到一起,最后连到到一起的向量被送入接下来的MLP层来做最后的预测。
损失函数
深度CTR模型中,广泛应用的损失函数使用的是目标item的label预测:

其中,![]() ,
, 为有
为有 个样本的训练集合,
个样本的训练集合,![]() 。
。
DIEN的网络结构
DIEN旨在获取获取用户的兴趣以及模型化用户的兴趣进化过程,其结构如下图

DIEN由几部分组成:
1.各类特征均通过embedding层进行转换;
2.DIEN通过两步来获取兴趣进化:1)兴趣提取层(interest extractor layer)基于用户的行为序列提取兴趣序列;2)兴趣进化层(interest evolving layer)模型化与目标推荐物品相关的兴趣的进化过程;
3.最后兴趣表示向量和嵌入向量被拼接到一起。
兴趣提取层(Interest Extractor Layer)
在兴趣提取层,从用户行为习惯序列中提取一系列的兴趣状态。为了平衡效率和性能,采用了GRU(Gate Recurrent Unit)网络结构(具体GRU结构介绍可参考GRU详解):
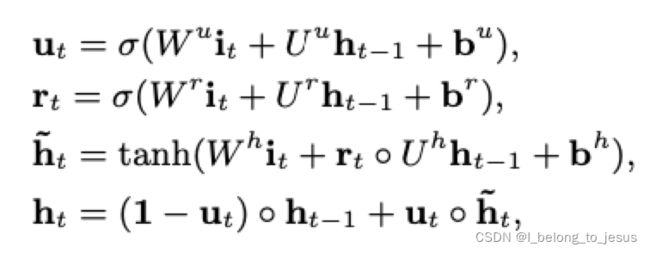
 为sigmoid激活函数,
为sigmoid激活函数,![]() 是内积。
是内积。![]() ,
,![]() 和
和![]()
![]() 。
。![]() ,
,![]() 和
和![]()
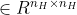 。
。![]() 是隐藏层的尺寸,
是隐藏层的尺寸,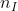 是输入的尺寸。
是输入的尺寸。![]() 为GRU的输入,
为GRU的输入,![\textbf{i}_t = \textbf{e}_b[t]](http://img.e-com-net.com/image/info8/8341ece1a85a488180f1434ce0a32604.gif) 代表用户采取的第个行为,
代表用户采取的第个行为,![]() 为第个隐藏状态。
为第个隐藏状态。
然而,隐藏层 ![]() 只能获取行为间的依赖性,无法高效地表示兴趣。由于目标商品的点击行为由最后的兴趣来触发,label只包含监管最终兴趣预测的真实信息,而历史状态
只能获取行为间的依赖性,无法高效地表示兴趣。由于目标商品的点击行为由最后的兴趣来触发,label只包含监管最终兴趣预测的真实信息,而历史状态![]() 不包含合适的监督。显而易见,每一步的兴趣状态直接导致了随后的行为,所以提出了辅助损失(auxiliary loss),auxiliary loss使用行为
不包含合适的监督。显而易见,每一步的兴趣状态直接导致了随后的行为,所以提出了辅助损失(auxiliary loss),auxiliary loss使用行为![]() 去监管兴趣状态
去监管兴趣状态![]() 的学习(
的学习(![]() 和
和![]() 应该具有很强的相关性)。而且,除了取出下一步的真实行为作为正样本,也通过从未点击商品集合采样来取出一些负样本。考虑有对行为嵌入序列:
应该具有很强的相关性)。而且,除了取出下一步的真实行为作为正样本,也通过从未点击商品集合采样来取出一些负样本。考虑有对行为嵌入序列:![]() ,其中
,其中![]() 代表点击过的行为序列,而
代表点击过的行为序列,而![]() 表示负样本序列。
表示负样本序列。![]() 表示用户
表示用户 在第次点击商品的嵌入向量,
在第次点击商品的嵌入向量,![]() 为所有商品的集合。
为所有商品的集合。![]() 为从商品集合随机抽取的且不是用户在第次点击过的商品。auxiliary loss的表达式为:
为从商品集合随机抽取的且不是用户在第次点击过的商品。auxiliary loss的表达式为:
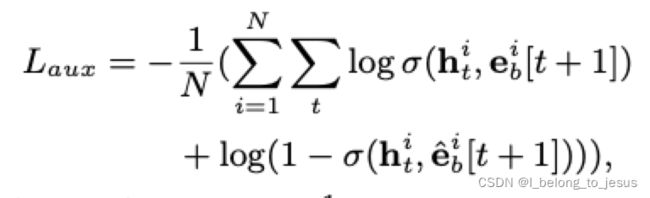
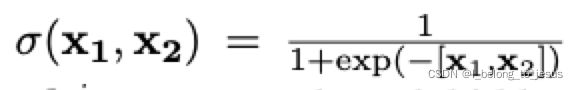 为sigmoid激活函数,
为sigmoid激活函数,![]() 表示GRU对于用户的第个隐藏状态,可以看到,auxiliary loss 通过优化的方法,使得
表示GRU对于用户的第个隐藏状态,可以看到,auxiliary loss 通过优化的方法,使得![]() 和
和![]() 的相关性变强,而
的相关性变强,而![]() 和
和![]() 相关性变弱,从而达到当前时刻状态
相关性变弱,从而达到当前时刻状态![]() 预测下一时刻行为
预测下一时刻行为![]() 的目标,整个全局loss为:
的目标,整个全局loss为:
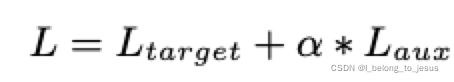
 为超参数,用来平衡兴趣表示和CTR预测。在auxiliary loss的帮助下,在用户发生行为
为超参数,用来平衡兴趣表示和CTR预测。在auxiliary loss的帮助下,在用户发生行为![]() 时,每个隐藏层
时,每个隐藏层![]() 足够表示当前用户兴趣的状态,把所有个兴趣点连在一起
足够表示当前用户兴趣的状态,把所有个兴趣点连在一起![]() 构成兴趣序列能够模型化兴趣的变化过程。
构成兴趣序列能够模型化兴趣的变化过程。
总的来说,引入 auxiliary loss有如下优势:
1.兴趣学习的角度,可以帮助GRU的隐藏层更好的表达用户的兴趣;
2.对于长序列GRU模型的训练,降低了BP算法的难度;
3.给予embedding层学习更多的语义信息,可以训练出更好的embedding矩阵。
兴趣进化层 (Interest Evolving Layer)
由于外部环境和内部感知的影响,不同用户的兴趣随时间在不断变化。兴趣的变化有两个特点:兴趣的多样性,一段时间喜欢书籍,一段时间喜欢衣服;兴趣有可能相互影响,但变化过程(例如书记的种类、衣服的品类等)几乎是独立变化的,通常只关心与推荐商品相关就可以。
在兴趣提取层的帮助下,可以拿到兴趣序列的有效表示。通过分析兴趣变化的特征,兴趣进化层结合了注意力机制的本地激活能力以及GRU模型化兴趣变化的序列学习能力。GRU每一步中的局部激活可以增强相关用户兴趣的影响,同时减弱兴趣飘变的干扰,对于模型化目标推荐物品相关的兴趣变化过程是很有帮助的。
兴趣进化层的核心同样是一个GRU,![]() 和
和![]() 分别表示兴趣进化模型的输入和隐藏状态,兴趣进化模型的GRU输入为对应兴趣提取层的兴趣状态:
分别表示兴趣进化模型的输入和隐藏状态,兴趣进化模型的GRU输入为对应兴趣提取层的兴趣状态:![]() 。最后的隐藏状态
。最后的隐藏状态![]() 表示最后的兴趣状态。
表示最后的兴趣状态。
在兴趣进化模型中,注意力函数的表达式为:

![]() 为推荐商品的嵌入向量的连接,
为推荐商品的嵌入向量的连接,![]() ,
,![]() 为隐藏状态的纬度,
为隐藏状态的纬度,![]() 为推荐商品的嵌入向量维度。Attention的分数反映了推荐物品
为推荐商品的嵌入向量维度。Attention的分数反映了推荐物品![]() 和输入
和输入![]() 的关系,更强的相关性会导致更高的注意力分数。几种结合注意力机制和GRU模型化兴趣变化过程的几种方法:
的关系,更强的相关性会导致更高的注意力分数。几种结合注意力机制和GRU模型化兴趣变化过程的几种方法:
GRU with attentional input (AIGRU)
AIGRU是注意力机制控制输入的GRU模块,主要目的是为了在兴趣进化过程中激活相关的兴趣,AIGRU使用注意力分数来影响兴趣进化层的输入:
![]()
![]() 为兴趣提取层中GRU的隐藏状态,
为兴趣提取层中GRU的隐藏状态,![]() 为兴趣进化层的GRU的输入。以这种方式,不相关的兴趣可以通过注意力分数来减少影响。AIGRU的缺点是,即使兴趣相关性很低也依然会影响兴趣进化的学习。
为兴趣进化层的GRU的输入。以这种方式,不相关的兴趣可以通过注意力分数来减少影响。AIGRU的缺点是,即使兴趣相关性很低也依然会影响兴趣进化的学习。
Attention based GRU(AGRU)
AGRU用注意力分数代替了GRU的更新门来直接修改隐藏状态:
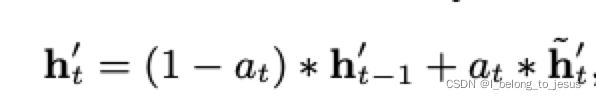
AGRU利用注意力分数直接控制隐藏层的更新,削弱了兴趣变化中不相关兴趣的影响,使得AGRU解决了AIGRU的缺点。
GRU with attentional update gate (AUGRU)
AGRU可以使用注意力分数来直接控隐藏层的更新,但是注意力分数是标量,即用一个标量![]() 代替了一个向量(更新门
代替了一个向量(更新门![]() ),这导致忽略了不同纬度间的不同,因此给出一种更准确的GRU即AUGRU:
),这导致忽略了不同纬度间的不同,因此给出一种更准确的GRU即AUGRU:
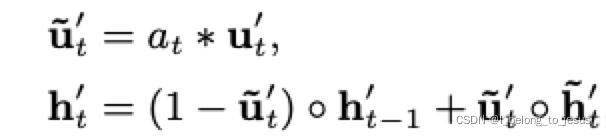
![]() 为原始的更新门,
为原始的更新门,![]() 为新的更新门,这样既保留了不同纬度的信息,又通过注意力分数
为新的更新门,这样既保留了不同纬度的信息,又通过注意力分数![]() 来控制相关性的影响。
来控制相关性的影响。
实验对比结果和结论
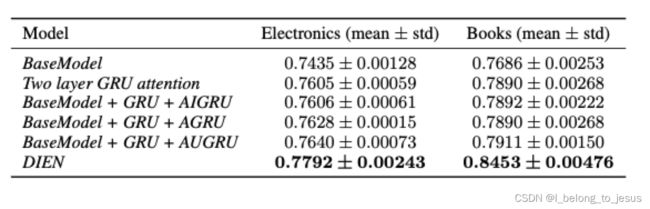
从实验对比上来说,DIEN即GRU+AUGRU+auxiliary loss + 其他常规模块的方式有明显的优势,这表明监督信息对于序列化兴趣和嵌入表示学习过程的重要性。