为什么80%的码农都做不了架构师?>>> 
文章简介
玄惭,真名罗龙九,阿里云DBA专家,负责阿里云RDS线上稳定以及专家服务团队。他经历过阿里历年双11实战考验,积累了7年对阿里云数据库用户的运维、调优、诊断等丰富DBA经验。本专题集结了玄惭排查经验、性能优化心得、最佳实践以及其他思考。
性能优化
1. 性能测试:自建数据库对比RDS中应当注意的地方(适用于MySQL,SQL SERVER,MongoDB)
常常很多用户对比测试自建数据库和RDS的性能差异,其测试结果往往是RDS不如ECS自建,用户往往怀疑难道我花了那么多的钱买的RDS难道还不如自己在ECS上搭建吗?从数据库测试的角度来看,测试首先必须是的公平的进行,其结果才具有说服力。
详情:https://yq.aliyun.com/articles/71232?spm=5176.153233.793261.1.d75LDx
2. 一个价值“千万”的秒杀场景参数优化
秒杀最早来自天猫双11各种商品的促销活动中,现在已经有很多业务场景在使用,比如抢红包,抢票等。其特点有三高:瞬时并发高,数据一致性高,热点更新频度高。这样三高的场景下往往给数据库造成极大的压力,大量更新数据库中的同一行,这样必然会产生锁等待,导致数据库的性能急剧下降的问题,很容出现雪崩效应。面对秒杀业务的场景,数据库成为了底层系统中最重要的瓶颈点,阿里经过几年的沉淀也诞生了很多的技术手段来进行优化,这里我们就重点讲一下底层数据所做的优化。
详情:https://yq.aliyun.com/articles/46353?spm=5176.153233.793261.4.d75LDx
3. 复杂关联SQL的优化
昨天处理了一则复杂关联SQL的优化,这类SQL的优化往往考虑以下四点:
-
查询所返回的结果集,通常查询返回的结果集很少,是有信心进行优化的;
- 驱动表的选择至关重要,通过查看执行计划,可以看到优化器选择的驱动表,从执行计划中的rows可以大致反映出问题的所在;
- 理清各表之间的关联关系,注意关联字段上是否有合适的索引;
-
使用straight_join关键词来强制表之间的关联顺序,可以方便我们验证某些猜想;
详情:https://yq.aliyun.com/articles/9048?spm=5176.153233.793261.6.d75LDx
4. 化繁为简-优化sql
这里有一段对话取自于和用户的一段旺旺聊天记录,在征得用户的同意后,放到我的blog中,希望更多的人能够看见,分享是一件快乐的事情;同时也想借此来说明一些问题,有时候试图用一条sql完成所有的业务逻辑可能会遇到麻烦,需要对复杂的sql进行一些拆分,可能会得到更好的效果。
详情:https://yq.aliyun.com/articles/9060?spm=5176.153233.793261.8.d75LDx
5. MySql sql优化之order by desc/asc limit M
Order by desc/asc limit M是我在mysql sql优化中经常遇到的一种场景,其优化原理也非常的简单,就是利用索引的有序性,优化器沿着索引的顺序扫描,在扫描到符合条件的M行数据后,停止扫描。看起来非常的简单,但是我经常看到很多性能较差的SQL没有利用这个优化规律,这里将结合一些实际的案例来分析说明。
详情:https://yq.aliyun.com/articles/9063?spm=5176.153233.793261.10.d75LDx
6. mysql sql优化之straight_join
在mysql中就有之对应的straight_join,由于mysql只支持nested loops的连接方式,所以这里的straight_join类似oracle中的use_nl hint。mysql优化器在处理多表的关联的时候,很有可能会选择错误的驱动表进行关联,导致了关联次数的增加,从而使得sql语句执行变得非常的缓慢,这个时候需要有经验的DBA进行判断,选择正确的驱动表,这个时候straight_join就起了作用了,下面我们来看一看使用straight_join进行优化的案例。
详情:https://yq.aliyun.com/articles/9064?spm=5176.153233.793261.12.d75LDx
7. 浅谈mysql的子查询
mysql的子查询的优化一直不是很友好,一直有受业界批评比较多,也是我在sql优化中遇到过最多的问题之一,你可以点击这里 ,这里来获得一些信息,mysql在处理子查询的时候,会将子查询改写,通常情况下,我们希望由内到外,也就是先完成子查询的结果,然后在用子查询来驱动外查询的表,完成查询,但是恰恰相反,子查询不会先被执行;今天希望通过介绍一些实际的案例来加深对mysql子查询的理解。
详情:https://yq.aliyun.com/articles/9070?spm=5176.153233.793261.14.d75LDx
8. SQL优化的一些总结
SQL的优化是DBA日常工作中不可缺少的一部分,我们可以按照 T=S/V(T代表时间,S代表路程,V代表速度)的思路来进行优化。
详情:http://hidba.org/?spm=5176.153233.793261.16.d75LDx&p=498
9. mysql explain 中key_len的计算
今天丁原问我mysql执行计划中的key_len是怎么计算得到的,当时还没有注意,在高性能的那本书讲到过这个值的计算,但是自己看执行计划的时候一直都没有太在意这个值,更不用说深讨这个值的计算了: ken_len表示索引使用的字节数,根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段都被查询用到。
详情:https://yq.aliyun.com/articles/17087?spm=5176.153233.793261.18.d75LDx
10. loose index scan 优化distinct
有这样的一个需求:select count(distinct nick) from user_access_xx_xx;这条sql用于统计用户访问的uv,由于单表的数据量在10G以上,即使在user_access_xx_xx上加上nick的索引,通过查看执行计划,也为全索引扫描,sql在执行的时候,会对整个服务器带来抖动。
详情:https://yq.aliyun.com/articles/17090?spm=5176.153233.793261.20.d75LDx
11. 使用伪’loose index scan’优化max
有时候我们会遇到以下的应用场景:
SELECT MAX(log_time)
FROM log_table
WHERE log_machine IN ($machines)
CREATE TABLE log_table (
id INT NOT NULL PRIMARY KEY,
log_machine VARCHAR(20) NOT NULL,
log_time DATETIME NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE INDEX ix_log_machine_time ON log_table (log_machine, log_time);
我们建立的索引为:(log_machine,log_time),当我们传入单个machine的时候,速度很快,但是当我们传入多个machines的时候,查询速度会一下子就降下来。
详情:https://yq.aliyun.com/articles/17091?spm=5176.153233.793261.22.d75LDx
12. mysql批量提交的优化
Java应用排量写入MySQL的优化,使用rewriteBatchedStatements=true参数,对批量操作,性能有较大提高,从官方解释上看,对普通操作没有。
详情:https://yq.aliyun.com/articles/17092?spm=5176.153233.793261.24.d75LDx
故障排查
1. Oracle迁移到MySQL性能下降的注意点
最近有较多的客户系统由原来由Oracle改造到MySQL后出现了性能问题CPU 100%,或是后台的CRM系统复杂SQL在业务高峰的时候出现堆积导致业务故障。在我的记忆里面淘宝最初从Oracle迁移到MySQL期间也遇到了很多SQL的性能问题,记忆最为深刻的子查询,当初的版本是MySQL5.1,这个版本对子查询的优化较差,导致了很多从Oracle迁移到MySQL的系统出现过性能问题,所以后面的开发规范中规定前台交易系统不要有复杂的表join。
详情:https://yq.aliyun.com/articles/72487?spm=5176.153233.793262.2.d75LDx
2. MySQL 5.5版本注意大内存导致DDL变慢的问题
最近在协助用户进行系统重构,RDS测试选型自然成为了本项目的一个重点,但是用户在测试不同规格的时候发现大规格的实例性能居然不如小规格,4C32G规格性能比8C64G规格高出10%,其性能监控也是非常的正常,4C32G规格是8C64G规格资源消耗的一半,TPS也是相当,那问题到底出现在那里?
详情:https://yq.aliyun.com/articles/73684?spm=5176.153233.793262.4.d75LDx
3. 注意table_open_cache过小也会导致性能问题
周一的时候有一个客户反馈自从上次rds重启后,慢查询特别多,有大量响应时间在1~3秒的请求,后端的工程师介入调查,发现随便建一个最简单的表,插入数据都需要300ms。一开始的时候怀疑可能是网络延迟导致的,客户测试了从ecs到rds的网络延迟,测试结果网络延时不到1ms,那问题到底出现在那里?在MySQL中可以使用profile去查看SQL的执行时间主要消耗在哪里,所以我们来看一下profile。
详情:http://hidba.org/?spm=5176.153233.793262.6.d75LDx&p=1119
4. RDS弹性升级后性能反而下降的案例
刚刚结束的2015年双11,天猫以912亿的成交量再次打破去年的记录成为一个奇迹,大家可能不知道,这些天猫的订单最后的处理都是放在阿里云聚石塔的机房完成,从2012年开始,淘宝的ISV,商家就开始把他们的订单,CRM后台系统逐渐迁移到云上,最核心的数据库就是存放在RDS中。
双11之前用户都会进行大批量的弹性升级,期间有较多用户反馈,在弹性升级后性能出现了大幅度的下降,其中由一个用户有两个RDS,一个RDS进行了弹性升级,另外一个RDS没有出现弹性升级,结果弹性升级后的RDS反而出现了性能下降,这让我们反思不得其解。RDS的弹性升级包括了两部分,一部分是磁盘容量的升级,另一部分是内存容量的升级(内存升级会同时升级数据库的连接数,CPU,IOPS),那么是什么原因导致了性能下降?
详情:https://yq.aliyun.com/articles/8964?spm=5176.153233.793262.8.d75LDx
5. 关于RDS只读实例延迟分析
只读实例是目前RDS用户实现数据读写分离的一种常见架构,用户只需要将业务中的读请求分担到只读节点上,就可以缓解主库查询压力,同时也可以把一些OLAP的分析查询放到另外的只读节点上,减小复杂统计查询对主库的冲击,RDS只读节点架构图如下:

由于RDS只读节点采用原生的MySQL Binlog复制技术,那么延迟必然会成为他成立之初就会存在的问题。
详情:https://yq.aliyun.com/articles/9046?spm=5176.153233.793262.10.d75LDx
6. 捣蛋SQL导致实例iops 100%
一用户RDS每天隔一段时间就会出现IOPS 100%的问题,求助到阿里云,这类问题的出现有以下一些排查思路:
1.慢SQL问题:通过优化索引,子查询,隐士转换,分页改写等优化;
2.DDL:create index,optimze table,alter table add column,create as select 。
详情:https://yq.aliyun.com/articles/50744?spm=5176.153233.793262.12.d75LDx
7. MySQL update use index merge(Using intersect) increase chances for deadlock
昨天一同事发现线上系统在并发更新的时候出现了死锁,通过排查定位于update更新使用了两个索引导致。
详情:http://hidba.org/?spm=5176.153233.793262.14.d75LDx&p=1065
8. 一次数据库上云迁移性能下降的排查
某客户目前正在将本地的业务系统迁移上云,测试过程中发现后台运营系统,在rds上运行时间明显要比线下PC上自建数据库运行时间要慢1倍,导致客户系统割接延期的风险。用户线下一台PC服务器的性能居然还比顶配的RDS跑的快,这让用户对RDS的性能产生了质疑,需要立刻调查原因。
详情:http://hidba.org/?spm=5176.153233.793262.16.d75LDx&p=1039
9. RDS链路卡慢问题的诊断
经常会收到用户反馈在使用RDS的过程中出现卡慢,闪断地情况,当出现此类问题的时候,首先我们要进行一下测试,看看问题出现在哪一个阶段,RDS给到用户的是一个DNS地址,其实他包括三个阶段:DNS–>VIP–>DB
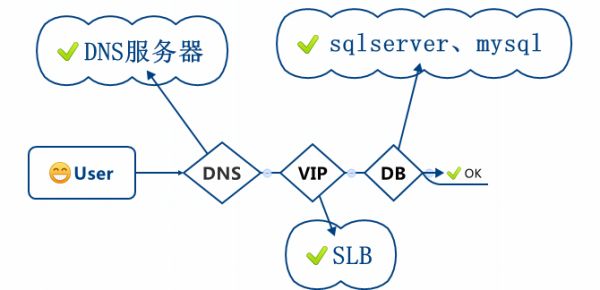
我们可以在本地的应用服务器(VM)上通过简单的ping命令,或者数据库的客户端去不断的连接测试RDS,来获取每次连接RDS的响应时间(RT)。
详情:https://yq.aliyun.com/articles/9047
10. ibdata1文件持续增加的问题定位
用户的ibdata1文件持续增加:
Innodb的表有两种存放方式:
第一种共享表空间方式:所有表的索引,数据统一存放在一个共享表空间中,这样会导致共享表空间的空间迅速增长,同时空间回收困难;
第二种独占表空间方式:就是RDS目前采用 的,也就是一张表一个表空间,表中的索引和数据存放在自己独立的表空间中,空间能够比较容易的回收;
无论是独占还是共享表空间,innodb都会有系统共享表空间(ibdata1),该系统表空间主要用于存储数据字典,undo entry,insert buffer,doublewrite buffer,
详情:https://yq.aliyun.com/articles/9055?spm=5176.153233.793262.20.Dkw83z
11. 有趣的大小写问题-utf8_bin
问题:
xxx@3023 14:51:26>insert into test_tmp_log_node_10445__01 select * from test;
ERROR 1062 (23000): Duplicate entry ‘taobao|维西v’ for key ‘idx_nodetemp_10445_01’
https://yq.aliyun.com/articles/9056
12. 关于RDS实例CPU超过100%的分析
https://yq.aliyun.com/articles/9065?spm=5176.153233.793262.24.t3VqBT
13. mysql主键的缺少导致备库hang
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的稳定性,也希望通过这篇博客,来加深主键在innodb引擎中的重要性,希望用户在使用RDS,设计自己的表的时候,一定要为表加上主键,主键可以认为是innodb存储引擎的生命,下面我们就来分析一下这个案例(本案例的生产环境的binlog为row模式,对于myisam存储引擎也有同样的问题)。
详情:https://yq.aliyun.com/articles/9066?spm=5176.153233.793262.26.t3VqBT
14. Waiting Auto-INC LOCK导致死锁
今天下午在看死锁相关的文档,到线上查看一生产数据库的时候,正好发现了show engine innodb status有一个死锁的信息: LATEST DETECTED DEADLOCK
详情:https://yq.aliyun.com/articles/9071?spm=5176.153233.793262.28.t3VqBT
15. 执行计划错误—索引统计信息的不准确
mysql在生成执行计划的时候,需要根据索引的统计信息进行一个估算,计算出成本最低的索引;但是mysql索引统计信息的采集默认8个pag,其中5.1估算rows estimate的算法存在bug http://bugs.mysql.com/bug.php?id=53761 ,么你的执行计划很有可能由于索引统计信息的不准确,导致优化不能够正确的选择索引。
详情:https://yq.aliyun.com/articles/9075?spm=5176.153233.793262.30.t3VqBT
16. 主备不一致:Table definition on master and slave does not match
昨天一同事在线上做变更,为了保证主库的稳定性,先在备库把binlog关闭,然后在进行DDL变更,在通过切换HA,把备库切换为主库,在老的主库上做DDL变更
看上去这样做法没有太大的问题,但是当备库变更一做完,HA切换到备库,开始老主库变更的时候,备库就出现复制出现错误.。
详情:https://yq.aliyun.com/articles/9076?spm=5176.153233.793262.32.t3VqBT
17. 一则优化案例
昨晚收到客服MM电话,一用户反馈数据库响应非常慢,手机收到load异常报警,登上主机后发现大量sql执行非常慢,有的执行时间超过了10s,本文是解决思路总结。
详情:https://yq.aliyun.com/articles/17084?spm=5176.153233.793262.34.t3VqBT
18.mysql中的Waiting for tables
接着上篇中遇到的mysql子查询,在问题的诊断中,丹臣注意到一个较为严重的问题,就是我们生产库中全部的数据库访问请求都处于Waiting for tables的状态,在将大查询kill掉后,所有的请求恢复正常;简单的理解为大查询阻塞了其他访问请求,但是这个理论是不可信,如果阻塞该表的DML还可以理解,但是把该数据库上的所有请求都阻塞了,这还是说不通的。那么我们就来看看所有的请求处于Waiting for tables这个状态是什么原因导致的。
详情:https://yq.aliyun.com/articles/17085?spm=5176.153233.793262.36.t3VqBT
19. 生产库中遇到mysql的子查询
使用过oracle或者其他关系数据库的DBA或者开发人员都有这样的经验,在子查询上都认为数据库已经做过优化,能够很好的选择驱动表执行,然后在把该经验移植到mysql数据库上,但是不幸的是,mysql优化器在处理子查询的时候,会将将子查询改写。
详情:https://yq.aliyun.com/articles/17086?spm=5176.153233.793262.38.t3VqBT
20. mysql子查询的弱点
mysql的子查询的优化不是很友好,一直有受业界批评比较多.
关于mysql的查询有两个知识点:
第一个为mysql在处理所有的查询的时候都强行转换为联接来执行,将每个查询包括多表中关联匹配,关联子查询,union,甚至单表的的查询都处理为联接,接着mysql执行联接,把每个联接在处理为一个嵌套循环(oracle-nest-loop);
第二个知识点:在mysql在处理子查询的时候,会将将子查询改写,通常情况下,我们希望由内到外,先完成子查询的结果,然后在用子查询来驱动外查询的表,完成查询
详情:http://hidba.org/?spm=5176.153233.793262.40.t3VqBT&p=260
21. Drop table 出现的问题
由于应用下线,需要把数据库中相关应用的表删除,库中有一千多张表,事先已经将所有的表rename到test库中,drop table的脚步也已经准备好,所以接下来的工作本以为是很轻松的事情,但是在执行脚本的过程中,发现删除表的速度感觉有点慢,查看主机的负载也在挺高的,报警消息中thread running过高也出现了,发现大多数线程的状态是Opening Tables,但还是勉强的忍受了过去,事后想想为什么删除表也会这么的慢?
详情:https://yq.aliyun.com/articles/17116?spm=5176.153233.793262.42.t3VqBT
22. Incorrect datetime value
MySQL中设置sql_mode。
https://yq.aliyun.com/articles/17124?spm=5176.153233.793262.44.t3VqBT
最佳实践
1. RDS MySQL空间优化最佳实践
本期将介绍存储空间相关的最佳实践。
详情:https://yq.aliyun.com/articles/55594?spm=5176.153233.793263.2.t3VqBT
2. MySQL锁问题最佳实践
近一段时间处理了较多锁的问题,包括锁等待导致业务连接堆积或超时,死锁导致业务失败等,这类问题对业务可能会造成严重的影响,没有处理经验的用户往往无从下手。下面将从整个数据库设计,开发,运维阶段介绍如何避免锁问题的发生,提供一些最佳实践供RDS的用户参考。
详情:http://hidba.org/?spm=5176.153233.793263.4.t3VqBT&p=1080
3. RDS MySQL参数调优最佳实践
很多时候,RDS用户经常会问如何调优RDS MySQL的参数,为了回答这个问题,写一篇blog来进行解释:
-
哪一些参数不能修改,那一些参数可以修改;
-
这些提供修改的参数是不是已经是最佳设置,如何才能利用好这些参数。
详情:https://yq.aliyun.com/articles/8961?spm=5176.153233.793263.6.t3VqBT
4. 如何将RDS的数据同步到本地自建数据库
长期以来有很多的用户咨询如何将RDS的数据同步到本地的数据库环境中,本篇文章以在阿里云的ECS服务器为例来说明如何将RDS的数据同步到本地数据库中。RDS对外提供服务是一个DNS地址+端口3306,这样就屏蔽了RDS后端的主从节点,那么该如何将数据同步到本地?
详情:https://yq.aliyun.com/articles/9044?spm=5176.153233.793263.8.t3VqBT
5. RDS最佳实践(五)—Mysql大字段的频繁更新导致binlog暴增
RDS Mysql采用的binlog 格式默认为ROW,在Mysql 5.6的版本之前,Mysql每次列的修改(update)都需要记录表中所有列的值。这样就存在一个问题,如果表中包含很多的大字段,表的单行长度就会非常长,这样每次update就会导致大量的 binlog空间生成。针对这个问题,在mysql 5.6中进行了改进,复制支持”row image control” ,只记录修改的列而不是行中所有的列,这对一些包含 BLOGs 字段的数据来说可以节省很大的处理能力,因此此项改进不仅节省了磁盘空间,同时也提升了性能。
详情:https://yq.aliyun.com/articles/9050?spm=5176.153233.793263.10.t3VqBT
6. RDS最佳实践(四)—如何处理Mysql的子查询
MySQL低版本中该如何优化的子查询。
详情:https://yq.aliyun.com/articles/9051?spm=5176.153233.793263.12.t3VqBT
7. RDS最佳实践(三)—如何制定相关的流程来规范RDS的使用
如何制定相关的流程来规范RDS的使用?
详情:https://yq.aliyun.com/articles/9052?spm=5176.153233.793263.14.t3VqBT
8. RDS最佳实践(二)—如何快速平稳的迁入RDS
用户在购买完RDS后,接下来就可以开始往RDS迁入数据了。在RDS是否支持在线平滑的迁移?
详情:https://yq.aliyun.com/articles/9053?spm=5176.153233.793263.16.t3VqBT
9. RDS最佳实践(一)—如何选择你的RDS
我该如何选择RDS?我要购买多大规格的RDS?RDS的连接数,iops指的是什么?上诉这些问题相信是每一个RDS用户在开始使用的时候都会有这样的疑问。首先我们要了解一下RDS的组成包括哪一些,从阿里云官网的购买页面中我们可以看到RDS包括了以下参数:数据库类型,版本,存储空间,规格:内存+连接数+io,地域,那我们就一个个来分析一下
详情:http://hidba.org/?spm=5176.153233.793263.18.t3VqBT&p=899
10. 巧用query cache
巧用query cache解决慢SQL的问题。
详情:https://yq.aliyun.com/articles/9057?spm=5176.153233.793263.20.t3VqBT
11. innodb使用大字段text,blob的一些优化建议
其中一个应用,对blob字段的依赖非常的严重,查询和更新的频率也是非常的高,单表的存储空间已经达到了近100G,如何优化?
详情:https://yq.aliyun.com/articles/9072?spm=5176.153233.793263.22.t3VqBT
12. 为什么我的RDS慢了?
为什么我的RDS突然变慢了?相信这是大多数客户在使用RDS中经常遇到的头疼问题。这里我将通过实际的真实案例来分析一下用户在使用RDS中慢的原因。
详情:http://hidba.org/?spm=5176.153233.793263.24.t3VqBT&p=512
13. mysql分析函数的实现
MySQL中分析函数是如何实现的。
https://yq.aliyun.com/articles/17101?spm=5176.153233.793263.26.t3VqBT
14. 数据库上云经典案例分析
本文PPT来自阿里云技术专家玄惭于10月14日在2016年杭州云栖大会上发表的演讲,分享主题为《数据库上云经典案例分析》。
详情;https://yq.aliyun.com/articles/63071?spm=5176.153233.793263.28.t3VqBT
双十一
1. 2016阿里云数据库双11复盘-自动化备战,0干预
2016年双11狂欢节完美落幕,这是阿里云RDS连续第五年支持双11大促,在持续高压力冲击下,整个双11期间0故障0丢单,相比前面四年,在备战过程中更加的自动和主动,今年双11高峰期间达到了0干预的目标。本文由核心参加工程师整理总结今年双11备战过程中在自动化以及性能优化所作的一些改进。
详情:https://yq.aliyun.com/articles/65099?spm=5176.153233.793264.2.t3VqBT
2. 阿里云数据库专家玄惭:云数据库超大流量峰值保障最佳实践
本次演讲收集整理了自RDS成立至今,在历次大流量峰值中如何保障活动中云数据库备战的最佳实践,包括之前的改造,压测和扩容;期间的监控,预案执行和应急处理;之后的收容和总结。力求全链路地帮助客户安全稳定地渡过超大流量峰值,让在你备战过程中少走一些弯路,多一些从容。
详情:https://yq.aliyun.com/articles/59220?spm=5176.153233.793264.4.t3VqBT
问题分析
1. 查看mysql实时运行sql的工具–orztop
该工具为我的同事朱旭开发的一款可以查看mysql数据库实时运行的sql状况的工具,以前苦于通过show processlist/show full processlist抓取sql的同志们现在只要盯一盯屏幕就可以了,非常的方便。
详情:http://hidba.org/?spm=5176.153233.793265.2.t3VqBT&p=841
2. 使用Percona Data Recovery Tool for InnoDB恢复数据
昨晚收到一则求助,一个用户的本地数据库的重要数据由于误操作被删除,需要进行紧急恢复,用户的数据库日常并没有进行过任何备份,binlog也没有开启,所以从备份和binlog入手已经成为不可能,咨询了丁奇,发了一篇percona的文章给我,顿时感觉有希望,于是到percona的官网上下载了恢复工具。
详情:https://yq.aliyun.com/articles/9059?spm=5176.153233.793265.4.t3VqBT
3. RDS MySql支持online ddl
在日常和客户沟通的过程中发现,他们在做mysql ddl变更的时候由于MySql本身的缺陷不支持online ddl,导致他们的业务不得不hang住一会儿,表越大,时间影响越长,所以期待有更好的解决方法;有些用户也想了一些方法,比如通过主备切换的方法,先在备库进行ddl,然后在通过主备切换到原主库进行ddl,但由于RDS对外提供给用户的是一个dns加port,所以后端的主备对用户是透明的,此方法行不通。其实在开源社区中已经有比较成熟的方法,那就是percona的pt-online-schema-change工具是其中之一,这里通过测试主要了解该工具的可靠性以及存在的问题,是否在RDS上支持。
详情:https://yq.aliyun.com/articles/9061?spm=5176.153233.793265.6.t3VqBT
其他
1. 云数据库 MySQL 版官网
MySQL是全球最受欢迎的开源数据库,作为开源软件组合 LAMP中的重要一环,广泛应用于各类应用场景。
详情:https://www.aliyun.com/product/rds/mysql?spm=5176.153233.793266.2.t3VqBT
2. 云数据库DBA专家服务
ApsaraDB专家服务组,全部来自阿里云DBA团队和数据库内核团队,多次参与 历年双11的护航保障活动,为客户提供阿里原厂顶尖水准的数据库服务。
详情:https://promotion.aliyun.com/ntms/ac/clouddba.html?spm=5176.153233.793266.4.t3VqBT
文章链接:https://zhuanlan.zhihu.com/p/27834293