本文主要用于介绍何恺明大神于2015年提出的空间金字塔池化网络(SPPNet网络),该网络架构也可以当作是R-CNN加速改进版。本笔记主要为方便初学者快速入门,以及自我回顾。
论文链接:https://arxiv.org/pdf/1406.4729.pdf
源码地址:http://research.microsoft.com/en-us/um/people/kahe/
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
现有的深度卷积神经网络都要求图像的输入是固定大小的(比如:224*224),然而这种“要求”其实都是“人为”的,且有可能会造成下游图像识别任务准确率的下降。本文提出的新的网络架构,我们采用了一种新的池化策略,“空间金字塔池化”(SPP-net)。该架构能对任意输入的图像尺度都生成固定长度的(fixed-length)的特征表达。金字塔池化对目标变形这种情况也具有很好的鲁棒性。在ImageNet 2012数据集上,我们的SPP-net相比于其他风格迥异的CNN网络架构,在准确率上有了一定的提升。
SPP-net同样能适用于目标检测领域。利用该网络架构后,我们只需对整张图片提取一次特征,然后在不同的候选区域上池化特征,来生成固定纬度的输出特征,用于后续的检测器训练。这种方法能够避免R-CNN中因重复计算图片特征而造成的资源浪费。实验表明,该方法在测试阶段,比R-CNN快了整整24-102倍,并且还同时在效果上有提升。
------------------第二菇 - 核心思想------------------
2.1 深度卷积神经网络的限制
毫无疑问,深度卷积神经网络的运用正在计算机视觉领域掀起一场新的变革。多项实验表明其效果碾压了过去多种传统图像算法,但是在训练和测试CNN网络阶段,有一个致命的问题始终存在,即:所有的CNN网络都会要求输入的图像大小是固定的(比如:224*224),这在很大程度上限制了输入的图片的大小尺度。若是一张任意大小的输入图像,想要进入到训练好的CNN中,其必要经过裁剪或缩放。而裁剪经常会错失一些图像的关键信息,缩放经常会造成图像的几何形状变化(如下图所示),最终造成整体准确率的下降。
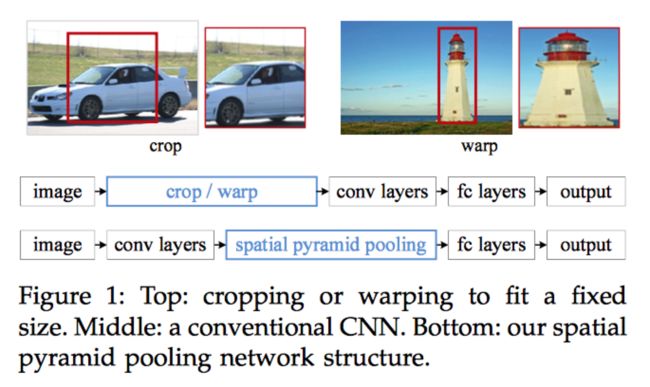
那么问题来了,为什么现在流行的CNN网络架构会要求图像的输入大小是一个定值呢?其实非常容易理解,熟悉卷积操作的同学肯定能够想到,卷积的滑动窗口其实对输入图像是没有任何限制的,因此经过多轮卷积操作得到的特征图(feature map)其大小是可以随输入图像大小任意变化的,那么问题只能是出在全连接层(FC),因为全连接层的大小我们是不能任意改变的,一旦全连接层的大小已经设定了,那倒着往前推,就让整个网络架构的输入的图像大小固定了。
了解到这一层面后,其实大家应该可以猜到本文要做的事情了,即,为了让输入的图像大小是可以任意变化的,只有在整个CNN网络架构的最后一层做一点文章了,而这也就是本文的提出的,取代FC层的SPP层(如上图下面的流程所示)。
2.2 SPPNet网络架构详解
跟着论文的节奏,我们先来看一下,图像经过一系列卷积操作以后,生成的特征图(feature map)是怎么样,
很明显,而且上面也讨论了,卷积操作对输入图像大小无要求,而最核心重要的特征图的处理,就是SPPNet网络的关键。
我们先明确一点,SPPNet中紧跟在卷积层后的空间金字塔池化层(spatial pyramid pooling)的输入是不固定的,但是输出是固定的。之所以输出是固定的,是因为,其后面仍然是需要接FC层去做下游任务的,因此,空间金字塔池化层就是一个对特征图中的特征进一步整合处理的过程。
接下来,我们重点理解一下空间金字塔池化层的概念,直接上一张原文中的示意图,

理解这张图,就需要深刻理解原文中的一句话,
“These spatial bins have sizes proportional to the image size, so the number of bins is fixed regardless of the image size.”
这里真的是好绕,一会儿spatial bins跟图片大小输入有关,一会儿number of bins又跟图片大小无关。。。第一次看的时候我也很蒙蔽,但是结合对BoW(词袋模型)和示意图的理解,我这里说明一下我对这句话的理解。
首先理解一个简单一点的,即number of bins是与图像无关的。这里的bins其实指的是最终整个池化层产生的结果是固定的,再直白一点就是,不管你那些bins是怎么得来的,但是最终输出加在一起的只要那么多。结合上图,就是,16 + 4 + 1 = 21。数字21就是bins的大小。
接着,我们再去理解spatial bins是与图片大小输入有关的。
先申明一件事情,上面的16,4,1其实就是池化得到的特征数,只不过,经过了第一层池化后得到了的特征输出,第二层池化后得到了的特征输出,第三层池化后得到了1个特征输出,所有的纬度都是256,这样他们才能拼接成一个固定大小的。
而空间金字塔池化的命名也由此而来,层层得加,每一层融合的空间信息是不一样的,自上而下,逐渐增加。试想,对于所有的池化层(并行,非串行)来说,输入的特征图大小是一样的,第三层只提炼了1个特征,是不是就可以简单理解为是全局池化了,融合的是全图的空间信息, 第二层提炼出了4个特征,自然每一次只融合了1/4的空间信息。
然后我们再来理解为什么spatial bins与图像大小输入有关。因为图像大小不一致,最终得到的特征图大小就不一致,但是经过池化后的特征数量又是一致的,那只能是池化层的大小(即spatial bin)是在动态变化的。比如,
当最终的特征图是的时候,要得到的输出,池化层的大小为7,步幅为6;但是当特征图是的时候,要得到的输出,池化层的大小为5,步幅为5。所以,针对不同的特征图,我们要想得到固定数量的特征,所设计的池化核的大小就是不一样的,而池化核就是作者这里指的spatial bins。
至此,理解该架构中最难的一句话,已经解释清楚了。简单总结一下,所谓的空间金字塔池化层,就是利用多个不同大小的池化核提取出固定大小的特征数。
2.3 SPPNet网络的训练过程
当然,细心的读者也已经发现了,如果真的要在训练时候满足任意尺度,那池化核的参数也要成千上万了,这显然是不可能的,本文作者也说了,其实真正训练的时候只考虑2种纬度的,分别为,的。其训练也分为2个过程,
1)首先进行单一尺寸的训练(Single-size training):仅仅针对来设计的3个池化核的大小,如下图所示,

文中给出的解释是,先单独训练单一尺寸的能提升模型的效果~
2)然后再进行多尺寸的训练(Multi-size training):这里作者多考虑了一种的,有一个细节就是,训练的图片不是重新裁剪的,而是直接将之前缩放过来的,目的是为了保证图片的内容是一致的,因此其后的FC层等的参数都是共享的,唯一变化的就是池化核的参数~而在训练的时候,也是一个轮次训练一种池化核参数。
值得一提的是,上面定义的尺寸也只是在训练的时候固定了图像的大小,在真正测试的时候,是可以接受任意尺寸的图像大小的(当然,也不是真的任意的,这取决于设计的池化核的区间范围)。
2.4 SPPNet网络架构的运用
SPPNet在图像分类上,取得了一定的提升,具体的展示过程,比较简单,有兴趣的同学自己看论文即可,这边重点讲一下,其在目标检测上的运用。
在那个年代(2015),R-CNN是最好的目标检测算法之一,但是其最大的弊端在于,对于其提取出的每一个候选区域框(约2000个),都需要经过一次CNN网络来提取特征,造成了大量的时间浪费,而运用SPPNet能将特征提取的操作只进行一次,从而大大提高了时效性。
我们来直接看一下论文中给出的示意架构图,

一张图片只经过一次CNN网络提取特征,拿到了特征图以后,我们再根据一种映射关系(论文的附录中有介绍),从原图生成的候选框中,找到特征图上的位置,然后将特征图经过空间金字塔池化层(可接受任意大小哦~),输出的维度还是固定的,再用于后续的训练。因此,将R-CNN中的重复提取特征的操作大大简化了,自然整个效率就上去了~
具体的实验效果这边就不展开了,同样有兴趣的同学可以翻看原始论文~上面有很详细的实验过程和结论。
------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想已经说清楚了。本论文主要是提出了一种新的网络架构SSPNet,主要用以解决CNN网络需要固定输入图像大小的顽疾,并附以详细的实验论证过程,证明其可行性,为后续发展奠定了基础。
简单总结一下本文就是先罗列了一下该论文的摘要,再具体介绍了一下本文作者的思路,也简单表述了一下自己对SPPNet网络的理解。希望大家读完本文后能进一步加深对该论文的理解。有说的不对的地方也请大家指出,多多交流,大家一起进步~