本文结构:
- 什么是 ROC?
- 怎么解读 ROC 曲线?
- 如何画 ROC 曲线?
- 代码
- 什么是 AUC?
- 代码
- ROC 曲线和 P-R 曲线对比?
ROC 曲线和 AUC 常被用来评价一个二值分类器的优劣。
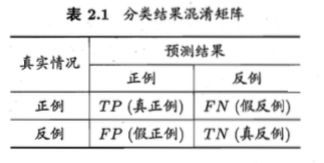
先来看一下混淆矩阵中的各个元素,在后面会用到:
1. ROC :
Receiver Operating Characteristic Curve 是评价二值分类器的重要指标
横坐标为假阳性率(False Positive Rate,FPR)=FP/N,预测为正但实际为负的样本占所有负例样本的比例。
纵坐标为真阳性率(True Positive Rate,TPR)=TP/P, 预测为正且实际为正的样本占所有正例样本的比例。

对角线对应的是 “随机猜想”
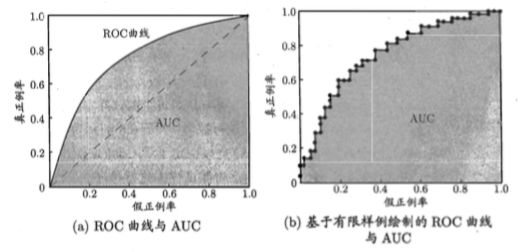
当一个学习器的 ROC 曲线被另一个学习器的包住,那么后者性能优于前者。
有交叉时,需要用 AUC 进行比较。
2. 先看图中的四个点和对角线:
- 第一个点,(0,1),即 FPR=0, TPR=1,这意味着 FN(false negative)=0,并且FP(false positive)=0。这意味着分类器很完美,因为它将所有的样本都正确分类。
- 第二个点,(1,0),即 FPR=1,TPR=0,这个分类器是最糟糕的,因为它成功避开了所有的正确答案。
- 第三个点,(0,0),即 FPR=TPR=0,即 FP(false positive)=TP(true positive)=0,此时分类器将所有的样本都预测为负样本(negative)。
- 第四个点(1,1),分类器将所有的样本都预测为正样本。
- 对角线上的点表示分类器将一半的样本猜测为正样本,另外一半的样本猜测为负样本。
因此,ROC 曲线越接近左上角,分类器的性能越好。
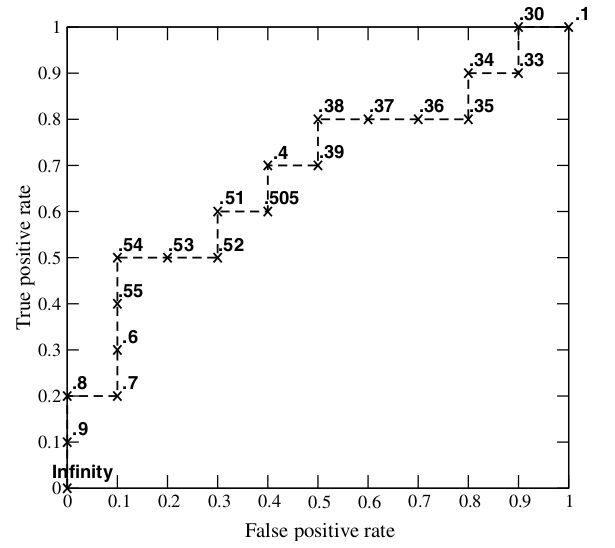
3. 如何画 ROC 曲线
例如有如下 20 个样本数据,Class 为真实分类,Score 为分类器预测此样本为正例的概率。
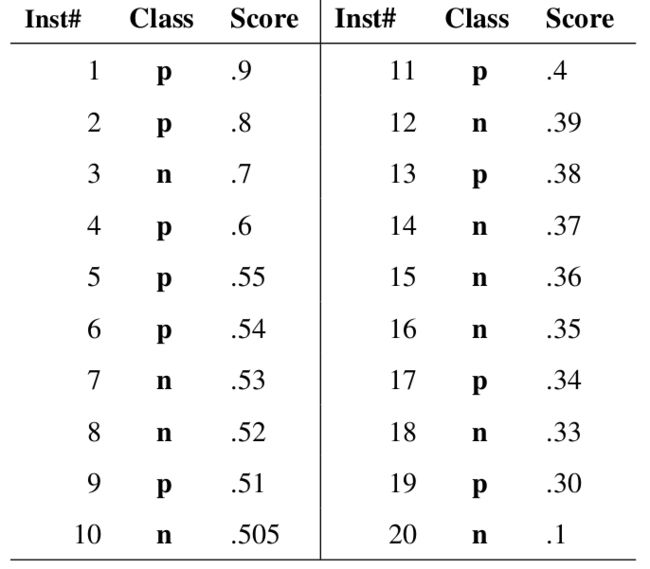
- 按 Score 从大到小排列
- 依次将每个 Score 设定为阈值,然后这 20 个样本的标签会变化,当它的 score 大于或等于当前阈值时,则为正样本,否则为负样本。
- 这样对每个阈值,可以计算一组 FPR 和 TPR,此例一共可以得到 20 组。
- 当阈值设置为 1 和 0 时, 可以得到 ROC 曲线上的 (0,0) 和 (1,1) 两个点。
4. 代码:
输入 y 的真实标签,还有 score,设定标签为 2 时是正例:
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
就会得到相应的 TPR, FPR, 截断点 :
fpr = array([ 0. , 0.5, 0.5, 1. ])
tpr = array([ 0.5, 0.5, 1. , 1. ])
thresholds = array([ 0.8 , 0.4 , 0.35, 0.1 ])#截断点
5. AUC:
是 ROC 曲线下的面积,它是一个数值,沿着 ROC 横轴做积分,
当仅仅看 ROC 曲线分辨不出哪个分类器的效果更好时,用这个数值来判断。
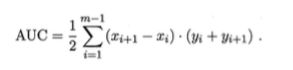
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
从上面定义可知,意思是随机挑选一个正样本和一个负样本,当前分类算法得到的 Score 将这个正样本排在负样本前面的概率就是 AUC 值。AUC 值是一个概率值,取值一般在 0.5~1 之间,AUC 值越大,分类算法越好。
6. 代码:
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
0.75
7. ROC 曲线相比 P-R 曲线有什么特点?
当正负样本的分布发生变化时,ROC 曲线的形状能够基本保持不变,而 P-R 曲线的形状一般会发生较剧烈的变化。
想要验证这个结论,可以先根据数据画出一对 roc 和 PR 曲线,再将测试集中的负样本数量增加 10 倍后再画一对 ROC 和 PR 图,然后会看到 P-R 曲线发生了明显的变化,而 ROC 曲线形状基本不变
这样,在评价一个模型的表现时,如果选择了不同的测试集进行评价,那么 ROC曲线可以更稳定地显示出模型的性能
这个特点的实际意义
例如计算广告领域中的转化率模型,正样本的数量可能只是负样本数量的 1/1000 甚至 1/10000,这时若选择不同的测试集,ROC 曲线能够更加稳定地反映模型的好坏
ROC 的这种稳定性使得它的应用场景更多,被广泛用于排序、推荐、广告等领域
如果roc更稳定,那要 PR 做什么?
当我们希望看到模型在某个特定数据集上的表现时,P-R 曲线能够更直观地反映模型性能。
大家好!我是 Alice,欢迎进入一起学《百面机器学习》系列!
这个系列并不只是根据书本画个思维导图,除了用导图的形式提炼出精华,还会对涉及到的重要概念进行更深度的解释,顺便也梳理一下机器学习的知识体系。
欢迎关注我,一起交流学习!
本篇文章在原来的基础上加了 ROC 曲线和 P-R 曲线的对比。
学习资料:
《百面机器学习》
《机器学习》,周志华
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html