opencv的机器学习检测在ML库中具有很大的相似性。简单来说都可以分成两步:
1、训练/得到分类器。
2、使用分类器进行数据分类。
实现这两步所需要的也只是两个关键函数:
1、train()
2、predict()
以下我们就14组数据进行训练,每组数据有两个参数,来得到分类器,然后再对一组有两个参数的数据进行预测。

预测参数:
下面开始进行编码拟合:
朴素贝叶斯分类
#include "opencv2/ml/ml.hpp"
using namespace std;
using namespace cv;
const int NUM = 14; //训练样本的个数
const int D = 2; //维度
//14个维数为4的训练样本集
double inputArr[NUM][D] =
{ 21,3,
24,3,
30,4,
15,3,
13,3,
19,4,
18,3,
12,3,
13,2,
26,4,
17,3,
16,3,
14,3,
16,3,
};
//一个测试样本的特征向量
double testArr[] = { 20, 3};
int main()
{
Mat trainData(NUM, D, CV_32FC1);//构建训练样本的特征向量
for (int i = 0; i(i, j) = inputArr[i][j + 1];
}
}
Mat trainResponse = (Mat_(NUM, 1) <<
39,36,53,31,22,25,33,26,50,25,24,57,33,23);//构建训练样本的类别标签
CvNormalBayesClassifier Mybayes;
bool trainFlag = Mybayes.train(trainData, trainResponse);//进行贝叶斯分类器训练
if (trainFlag) {
Mybayes.save("normalBayes.txt");
}
else {
system("pause");
exit(-1);
}
CvNormalBayesClassifier Tbayes;
Tbayes.load("normalBayes.txt");
Mat testSample(1, D, CV_32FC1);//构建测试样本
for (int i = 0; i(0, i) = testArr[i];
}
float flag = Tbayes.predict(testSample);//进行测试
cout << "flag = " << flag << endl;
system("pause");
return 0;
}
得到的结果为:
朴素贝叶斯分类器
决策树
#include "opencv2/core/core_c.h"
#include "opencv2/ml/ml.hpp"
#include
#include
int main()
{
//init data
float fdata[14][2] = {
21, 3,
24, 3,
30, 4,
15, 3,
13, 3,
19, 4,
18, 3,
12, 3,
13, 2,
26, 4,
17, 3,
16, 3,
14, 3,
16, 3,
};
cv::Mat data(14, 2, CV_32F, fdata);
float fresponses[14] = { 39, 36, 53, 31, 22, 25, 33, 26, 50, 25, 24, 57, 33, 23 };
cv::Mat responses(14, 1, CV_32F, fresponses);
CvDTree *tree;
CvDTreeParams params(10,2, 0,true,15, 0, true,true, NULL);
tree = new CvDTree;
tree->train(data, CV_ROW_SAMPLE, responses, cv::Mat(),
cv::Mat(), cv::Mat(), cv::Mat(),
params);
double testArr[] = { 20, 3 };
cv::Mat sample(1, 2, CV_32F, testArr);
double flag = tree->predict(sample, cv::Mat())->value;
std::cout << "flag=" << flag << std::endl;
system("pause");
return 0;
}
得到的结果是:
决策树
随机森林
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include
#include
using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
double trainingData[14][2] = { 21, 3,
24, 3,
30, 4,
15, 3,
13, 3,
19, 4,
18, 3,
12, 3,
13, 2,
26, 4,
17, 3,
16, 3,
14, 3,
16, 3 };
CvMat trainingDataCvMat = cvMat(14, 2, CV_32FC1, trainingData);
float responses[14] = { 39, 36, 53, 31, 22, 25, 33, 26, 50, 25, 24, 57, 33, 23 };
CvMat responsesCvMat = cvMat(14, 1, CV_32FC1, responses);
CvRTParams params = CvRTParams(10, 2, 0, false, 16, 0, true, 0, 100, 0, CV_TERMCRIT_ITER);
CvERTrees etrees;
etrees.train(&trainingDataCvMat, CV_ROW_SAMPLE, &responsesCvMat,
NULL, NULL, NULL, NULL, params);
double sampleData[2] = { 20, 3 };
Mat sampleMat(2, 1, CV_32FC1, sampleData);
float flag = etrees.predict(sampleMat);
cout << "flag=" << flag << endl;
system("pause");
return 0;
}
得到的结果是:
随机森林
boosting
由于boosting的原理是将若干个弱分类器进行结合得到一个强分类器,如图所示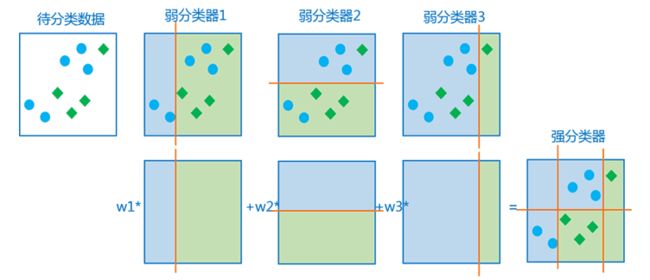
boosting原理
所以boosting只支持二级分类,我们为了和上述其他几种情况作对比,将不小于26的response值设置为1,不大于25的response值设置为0,来进行分类训练,观察得到的结果。

response的新旧值对照表
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include
#include
using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
float trainingData[14][2] = { 21, 3,
24, 3,
30, 4,
15, 3,
13, 3,
19, 4,
18, 3,
12, 3,
13, 2,
26, 4,
17, 3,
16, 3,
14, 3,
16, 3 };
Mat trainingDataMat(14, 2, CV_32FC1, trainingData);
float responses[14] = { 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0 };
Mat responsesMat(14, 1, CV_32FC1, responses);
float prior[] = {1,1};
CvBoostParams params(CvBoost::REAL, // boost_type
10, // weak_count
0.95, // weight_trim_rate
15, // max_depth
false, // use_surrogates
prior
);
CvBoost boost;
boost.train(trainingDataMat,
CV_ROW_SAMPLE,
responsesMat,
Mat(),
Mat(),
Mat(),
Mat(),
params
);
float myData[2] = { 20, 3 };
Mat myDataMat(2, 1, CV_32FC1, myData);
double flag = boost.predict(myDataMat);
cout << "flag=" << flag << endl;
system("pause");
return 0;
}
boosting
可以认为boosting计算出的值为26。