26.python机器学习-MachineLearning
26.1 机器学习概述

机器学习应用场景

26.2 数据来源与类型
26.1 数据来源
- 企业日益积累的大量数据(互联网公司更为显著)
- 政府掌握的各种数据
- 科研机构的实验数据
- … …
- 离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度。
- 连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
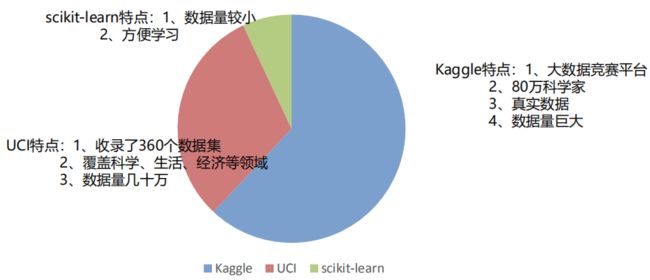
26.2 可用数据集
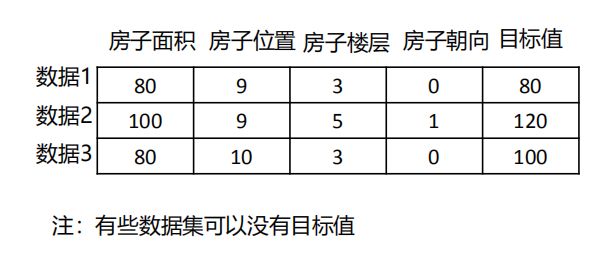
26.3 常用数据集数据的结构组成
结构:特征值+目标值
26.3 数据的特征工程
26.3.1 Scikit-learn库介绍
- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。
26.3.2 数据的特征处理
- 数值型数据:
- 标准缩放:
- 归一化
- 标准化
- 缺失值
- 标准缩放:
- 类别型数据:one-hot编码
- 时间类型:时间的切分
26.4 实验
逻辑回归
In:
import numpy as np
X = np.random.rand(1000,4) #(1000, 4)
y = np.random.randint(2, size=1000)
In:
#训练集和测试集拆分
from sklearn.model_selection import train_test_split
# help(train_test_split)
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
In:
from sklearn.linear_model import LogisticRegression
In:
# help(LogisticRegression)
logic = LogisticRegression() #建立模型
# penalty='l2' 惩罚项,避免过拟合的问题
#max_iter=100 迭代100次
In:
#训练模型
logic.fit(x_train,y_train) #X是特征,y是目标值
out:
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
In:
#评估模型
from sklearn.model_selection import cross_val_score
score = cross_val_score(logic,x_test,y_test,cv=4)
print(score.mean())
out:
0.558623449379752
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
In:
#预测结果
y_predict = logic.predict(x_test) #X代表了测试集的特征
In:
y_predict
out:
array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1,
1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0,
0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0,
0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1,
0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1,
0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1,
0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0,
1, 0])
In:
logic.score(x_test,y_test)
out:
0.49
决策树
In:
from sklearn.tree import DecisionTreeClassifier
- criterion :gini,entropy
- max_depth:最大深度
- min_samples_split:最小切分样本数
- min_samples_leaf:叶子节点最小样本数
- max_leaf_nodes:最大叶子节点个数
- max_features:最大特征数
In:
#参数调优
from sklearn.model_selection import GridSearchCV,StratifiedKFold
skcv = StratifiedKFold(n_splits=4,random_state=33)
grid_params = {'max_features':[3,4],'criterion':['gini','entropy']}
# help(GridSearchCV)
gs = GridSearchCV(dt,param_grid=grid_params,cv=skcv)
gs.fit(x_train,y_train)
out:
GridSearchCV(cv=StratifiedKFold(n_splits=4, random_state=33, shuffle=False),
error_score='raise-deprecating',
estimator=DecisionTreeClassifier(class_weight=None,
criterion='gini', max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort=False, random_state=None,
splitter='best'),
iid='warn', n_jobs=None,
param_grid={'criterion': ['gini', 'entropy'],
'max_features': [3, 4]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
In:
gs.best_params_ #最优参数组合
out:
{'criterion': 'gini', 'max_features': 3}
In:
gs.best_score_
out:
0.5
In:
dt_best = DecisionTreeClassifier(criterion='gini',max_features=3)
dt_best.fit(x_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=3, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
In:
dt.score(x_test,y_test)
out:
0.48
随机森林
In:
from sklearn.ensemble import RandomForestClassifier
- n_estimators: 评估器的数量
- criterion :gini,entropy
- max_depth:最大深度
- min_samples_split:最小切分样本数
- min_samples_leaf:叶子节点最小样本数
- max_leaf_nodes:最大叶子节点个数
- max_features:最大特征数
In:
rf = RandomForestClassifier()
In:
rf.fit(x_train,y_train)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\ensemble\forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.
"10 in version 0.20 to 100 in 0.22.", FutureWarning)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
In:
rf.score(x_test,y_test)
out:
0.51
In:
rf.feature_importances_
out:
array([0.23488722, 0.24854995, 0.25496364, 0.26159919])
XGBOOST
In:
pip install xgboost
Collecting xgboost
Downloading https://files.pythonhosted.org/packages/29/31/580e1a2cd683fa219b272bd4f52540c987a5f4be5d28ed506a87c551667f/xgboost-1.1.1-py3-none-win_amd64.whl (54.4MB)
Requirement already satisfied: scipy in d:\programdata\anaconda3\lib\site-packages (from xgboost) (1.3.1)
Requirement already satisfied: numpy in d:\programdata\anaconda3\lib\site-packages (from xgboost) (1.16.5)
Installing collected packages: xgboost
Successfully installed xgboost-1.1.1
Note: you may need to restart the kernel to use updated packages.
In:
from xgboost import XGBClassifier
- max_depth:深度
- learning_rate:学习率
- gamma
- C:惩罚因子
In:
xgb = XGBClassifier()
In:
xgb.fit(x_train,y_train)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1,
objective='binary:logistic', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
In:
xgb.score(x_test,y_test)
out:
0.535
In:
y_pred = xgb.predict(x_test)
In:
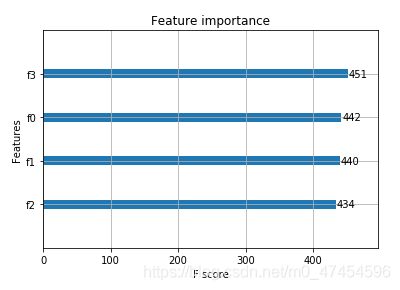
#特征重要程度
from xgboost import plot_importance
plot_importance(xgb)
out:
In:
#评价方法
from sklearn.metrics import classification_report,f1_score
rep = classification_report(y_test,y_pred)
f1 = f1_score(y_test,y_pred)
print(f1)
out:
0.5753424657534247
朴素贝叶斯
In:
from sklearn.naive_bayes import GaussianNB
In:
# help(MultinomialNB)
nb = GaussianNB()
nb.fit(x_train,y_train)
out:
GaussianNB(priors=None, var_smoothing=1e-09)
In:
nb.score(x_test,y_test)
out:
0.61
SVM
调优的参数
- C:惩罚因子
- gamma
- kernel: linear,rbf
In:
from sklearn.svm import SVC
svm = SVC()
svm.fit(x_train,y_train)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
In:
svm.score(x_test,y_test)
out:
0.6
神经网络
In:
from sklearn.neural_network import MLPClassifier
重要参数:
- activation:激活函数,默认relu
- hidden_layer_sizes:隐藏层神经元个数
- learning_rate:学习率
In:
mlp = MLPClassifier()
mlp.fit(x_train,y_train)
mlp.score(x_test,y_test)
D:\ProgramData\Anaconda3\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:585: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
% self.max_iter, ConvergenceWarning)
out:
0.495