多线程
CyclicBarrier和CountDownLatch的区别
CountDownLatch: 一个线程(或者多个), 等待另外N个线程完成某个事情之后才能执行。
CyclicBarrier: N个线程相互等待,任何一个线程完成之前,所有的线程都必须等待。
CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset() 方法重置。所以CyclicBarrier能处理更为复杂的业务场景,比如如果计算发生错误,可以重置计数器,并让线程们重新执行一次。
CountDownLatch:减计数方式,CyclicBarrier:加计数方式
ThreadLocal
ThreadLocal提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
底层实现:每个Thread维护一个ThreadLocalMap哈希表,这个哈希表的key是ThreadLocal实例本身,value才是真正要存储的值Object。
ThreadLocal和synchronized的区别?
ThreadLocal和synchronized关键字都用于处理多线程并发访问变量的问题,只是二者处理问题的角度和思路不同。
ThreadLocal是一个Java类,通过对当前线程中的局部变量的操作来解决不同线程的变量访问的冲突问题。所以,ThreadLocal提供了线程安全的共享对象机制,每个线程都拥有其副本。Java中的
synchronized是一个保留字,它依靠JVM的锁机制来实现临界区的函数或者变量的访问中的原子性。在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。此时,被用作“锁机制”的变量时多个线程共享的。
- 同步机制(
synchronized关键字)采用了以“时间换空间”的方式,提供一份变量,让不同的线程排队访问。而ThreadLocal采用了“以空间换时间”的方式,为每一个线程都提供一份变量的副本,从而实现同时访问而互不影响。
链接:https://www.jianshu.com/p/807686414c11
线程池的实现原理
当向线程池提交一个任务之后,线程池是如何处理这个任务的呢?

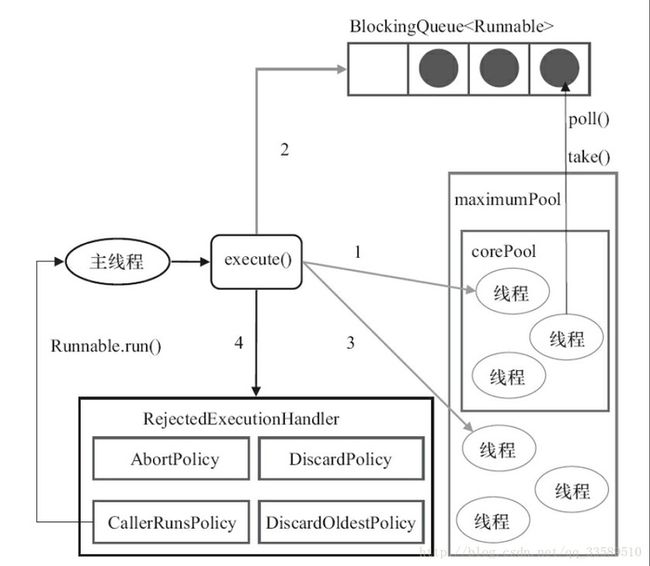
ThreadPoolExecutor执行execute()分4种情况
若当前运行的线程少于
corePoolSize,则创建新线程来执行任务(执行这一步需要获取全局锁)若运行的线程多于或等于
corePoolSize,则将任务加入BlockingQueue若无法将任务加入
BlockingQueue,则创建新的线程来处理任务(执行这一步需要获取全局锁)若创建新线程将使当前运行的线程超出
maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()
采取上述思路,是为了在执行execute()时,尽可能避免获取全局锁 在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
过滤器与拦截器
拦截器:spring mvc中的一项重要功能,主要作用是拦截用户的请求并进行相应的处理.比如通过拦截器进行用户权限验证,判断用户是否已经登录
过滤器:过滤器是实现了javax.servlet.Filter接口的服务器端程序,主要的用途是过滤字符编码,做一些业务逻辑判断,过滤器随web应用启动而启动,只初始化一次,只有当web应用停止或重新部署才销毁
监听器:监听器是实现了javax.servlet.ServletContextListener接口的服务器端程序,它也是随web应用的启动而启动,只初始化了一次,随web应用的停止而销毁.
过滤器和拦截器对比
(1)规范不同:Filter是在Servlet规范中定义的,是Servlet容器支持的。而拦截器是在Spring容器内的,是Spring框架支持的。
(2)使用的资源不同:同其他的代码块一样,拦截器也是一个Spring的组件,归Spring管理,配置在Spring文件中,因此能使用Spring里的任何资源、对象,例如Service对象、数据源、事务管理等,通过IoC注入到拦截器即可;而Filter则不能。
(3)深度不同:Filter在只在Servlet前后起作用。而拦截器能够深入到方法前后、异常抛出前后等,因此拦截器的使用具有更大的弹性。所以在Spring构架的程序中,要优先使用拦截器。
(4)使用范围不同:Filter是Servlet规范规定的,只能用于Web程序中。而拦截器既可以用于Web程序,也可以用于Application、Swing程序中。
缓存常见问题
缓存雪崩
原有的缓存失效,新的缓存还没有更新,导致原本访问缓存的请求,全部去查数据库,对数据库和CPU造成访问压力,严重的会造成数据库宕机
解决方案
- 加锁排队:对缓存的key加锁,当有1000个请求过来时,999个在等待 治标不治本
- 缓存标记:给每一个缓存数据增加相应的缓存标记,记录缓存是否失效,如果缓存标记失效,则更新缓存数据
- 缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
缓存穿透
查询数据时,数据库没有,缓存自然也没有。这样会导致用户查询的时候,在缓存找不到,每次都要去数据库查一遍,然后返回空(进行了两次无用的查询)。
解决方案
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
- 简单粗暴的方法:如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓存中获取就有值了,而不会继续访问数据库
缓存预热
系统上线后,将相关的缓存数据直接加在到缓存系统
解决方案
- 直接写个缓存刷新页面,上线时手工操作
- 数据量不大的话,可以在项目启动的时候自动进行加载
- 定时刷新缓存
缓存更新
常用的淘汰算法:
- FIFO:First In First Out,先进先出。判断被存储的时间,离目前最远的数据优先被淘汰。
- LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
- LFU:Least Frequently Used,最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
maxmemory-policy 六种方式
- volatile-lru:只对设置了过期时间的key进行LRU(默认值)
- allkeys-lru : 删除lru算法的key
- volatile-random:随机删除即将过期key
- allkeys-random:随机删除
- volatile-ttl : 删除即将过期的
- noeviction : 永不过期,返回错误
redis默认有6种缓存失效策略
1.noeviction:达到内存限额后返回错误,客户尝试可以导致更多内存使用的命令(大部分写命令,但DEL和一些例外)
2.allkeys-lru:为了给新增加的数据腾出空间,驱逐键先试图移除一部分最近使用较少的(LRC)。
3.volatile-lru:为了给新增加的数据腾出空间,驱逐键先试图移除一部分最近使用较少的(LRC),但只限于过期设置键。
4.allkeys-random: 为了给新增加的数据腾出空间,驱逐任意键
5.volatile-random: 为了给新增加的数据腾出空间,驱逐任意键,但只限于有过期设置的驱逐键。
6.volatile-ttl: 为了给新增加的数据腾出空间,驱逐键只有秘钥过期设置,并且首先尝试缩短存活时间的驱逐键
自定义缓存淘汰策略
- 定时清理过期的缓存
- 当有用户请求过来时,判断这个请求所用到的缓存是否过期,过期的话去底层系统得到新数据并更新缓存
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;
dubbo
容错机制(6种)
- Failsafe 失败安全,可以认为是把错误吞掉(记录日志)
- failover 失败转移 默认机制 重试其他服务器,默认重试2次
- failfast 快速失败,失败立即抛异常
- failback 失败自动恢复 记录失败请求,定时重发,通常用于通知
- Forking forks 设置并行数,并行调用多个服务,一个成功立即返回
- broadcast 广播调用所有提供者,任意一台报错,则执行的方法报错
负载均衡算法
- Random LoadBalance:随机访问策略,按照权重设置随机概率 dubbo默认的负载均衡算法
- RoundRobin LoadBalance:轮询,按照公约后的权重设置轮询比率
- LeastActive LoadBalance:最少活跃调用数,相同活跃数的随机,活跃数指调用(invoke)前后计数差,使慢的机器收到更少。
- ConsistentHash LoadBalance:一致性哈希
服务降级
降级的目的是为了保证核心服务可用
降级可以有几个层面的分类:自动降级和人工降级;
按照功能可以分为:读服务降级和写服务降级
- 对一些非核心服务进行人工降级;在大促之前通过降级开关关闭哪些推荐内容、评价等对主流程没有影响的功能
- 故障降级:比如调用的远程服务挂了,网络故障、或者RPC服务返回异常,那么可以直接降级;降级的方案比如设置默认值、采用兜底数据(系统推荐的行为广告挂了,可以提前准备静态页面做返回)等等
- 限流降级:在秒杀这种流量比较集中并且流量特别大的情况下,因为突发访问量特别大,可能会导致系统支撑不了。这个时候可以采用限流来限制访问量;当达到阈值时,后续的请求被降级,比如进入排队页面、跳转到错误页(活动太火爆,稍后重试等)
JVM内存溢出
- jvm什么情况下会溢出:当申请内存的速度超过内存回收的速度
- 怎么让栈内存溢出:栈是jvm内存区域中的一块,存在两种内存溢出
- stackOverflow和outofmemory两种错误。
- 递归过多会出现stackOverflow。如果在栈中申请过多内而超出栈剩余的内存会出现oom。
- 为什么jvm有垃圾回收还是会内存溢出
JVM回收内存只有条件的,根遍历遍历不到的对象才会被回收,如你所说,如果有一些对象一直持有强引用,那么就算JVM内存溢出也不会被回收。
mysql
配置相关
1. 8小时失效问题
问题描述
- msyql的连接被创建之后,如果没有手动关闭连接,mysql默认会在8小时之后回收连接
- 连接池保留了连接,但是mysql数据库已经回收了连接;使用sqlyog还能连上,但是程序中却连不上
理论依据
MySQL 的默认设置下,当一个连接的空闲时间超过8小时后,MySQL 就会断开该连接,而 c3p0/dbcp 连接池则以为该被断开的连接依然有效。在这种情况下,如果客户端代码向c3p0/dbcp 连接池请求连接的话,连接池就会把已经失效的连接返回给客户端,客户端在使用该失效连接的时候即抛出异常。
问题根本原因
在mysql中有相关参数设定,当数据库连接空闲一定时间后,服务器就会断开等待超时的连接:
相关参数
mysql> show variables like '%timeout%';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| connect_timeout | 10 |
| delayed_insert_timeout | 300 |
| innodb_flush_log_at_timeout | 1 |
| innodb_lock_wait_timeout | 50 |
| innodb_rollback_on_timeout | OFF |
| interactive_timeout | 28800 |
| lock_wait_timeout | 31536000 |
| net_read_timeout | 30 |
| net_write_timeout | 60 |
| rpl_stop_slave_timeout | 31536000 |
| slave_net_timeout | 3600 |
| wait_timeout | 28800 |
+-----------------------------+----------+
rows in set
wait_timeout 指的是mysql在关闭一个非交互的连接之前所要等待的秒数,其取值范围为1-2147483(Windows),1-31536000(linux),默认值28800。
interactive_time 指的是mysql在关闭一个交互的连接之前所要等待的秒数(交互连接如mysql gui tool中的连接),其取值范围随wait_timeout变动,默认值28800。
比如我们在终端上进入mysql管理,使用的即使交互的连接,这时候,如果没有操作的时间超过了interactive_time设置的时间就会自动断开。 当然我们可以在mysql_real_connect()中使用CLIENT_INTERACTIVE来设置位交互连接模式。
如果要修改timeout的值又不希望重启数据库服务器,那可以使用set global wait_timeout = 200;来修改,记得global哦,这是对mysql运行时全局变量的修改,如果没有global,则修改的变量只是当前这次开启的会话的而已
+----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | wait_timeout | 10 | +----------------------------+-------+
上面这样查看才能得到数值改动了,如果调用总的查看指令得不到改动信息。改动之后不能重启数据库,不然修改的值会继续变成默认值。
解决方案
- 修改配置文件
-
在/etc/my.cnf 添加
[mysqld] wait_timeout=31536000 interactive_timeout=31536000 windows
在my.ini文中增加
interactive_timeout=31536000
wait_timeout=31536000
- 程序连接池配置
- 如果是在Spring中使用DBCP连接池,在定义datasource增加属性validationQuery和testOnBorrow
- 如果是在Spring中使用c3p0连接池,则在定义datasource的时候,添加属性testConnectionOnCheckin和testConnectionOnCheckout
2. 数据库连接过多
原因
session用完没关闭,表示连接没释放。其他session不可以再利用这个连接。久而久之,连接池中连接数达到最大
解决方案
使用数据库连接池,c3p0,DBCP等
3. like索引失效
a.like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。如where reverse(code) like reverse('%Code2') b.like keyword% 索引有效。 c.like %keyword% 索引失效,也无法使用反向索引。
4. In or 比较
mysql in 和or 所在列如果没有索引。in的效率比or的高
详解
nginx
单点故障解决方案
Keepalived + nginx 实现nginx的高可用
通过keepalived来实现同一个虚拟IP映射到两台Nginx代理服务器,如果主服务器挂掉或者主服务器的keepalived挂掉又或者主服务器的Nginx挂掉(Nginx挂掉后会杀死keepalived的进程,在脚本中有控制)那从服务器的keepalived会检测到并会接管原先MASTER的网络功能,这种方式来实现Nginx的高可用性(如上文中的keepalived简要介绍)
详细介绍
负载均衡策略
负载均衡的策略可以大致分为两大类:内置策略 和扩展策略 内置策略:一般会直接编译进Nginx内核,常用的有、轮询、ip hash、最少连接 扩展策略:fair、url hash等
轮询
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
轮询加权:指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
ip_hash(ip绑定)
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
最少连接(least_conn)
下一个请求将被分派到活动连接数量最少的服务器
fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
| 调度策略 | 含义 |
|---|---|
| 轮询 | 按照时间顺序,逐一分配到不同的后端服务器 |
| 加权轮询 | weight值越大,分配到的访问几率越高 |
| ip_hash | 每个请求按访问IP的hash结果分配,这样来自同一个IP的请求固定访问一个后端服务器,可以解决分布式session问题,但不是最优的解决办法,另一个即集中式session存储校验,将session放到redis集群当中。 |
| url_hash | 按照访问的URL的hash结果来分配请求,使一个URL始终定向到同一个后端服务器 |
| less_conn | 最少连接数,哪个机器连接数少,就分发 |
| hash关键数值 | hash自定义的key |
spring
事务问题
下面的代码里事务有三个问题,都会导致事务不生效:
private方法加@Transactional 不生效,因为事务是基于动态代理,无法代理private方法;
-
同一个类中,方法A无事务,方法B有事务,在方法A中调用B,B事务不会生效;
原因:在一个Service内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务.是因为spring采用动态代理机制来实现事务控制,而动态代理最终都是要调用原始对象的,而原始对象在去调用方法时,是不会再触发代理了
spring默认的动态代理为java的动态代理,加事务的方法需要是一个接口方法,否则事务不生效。如果真的需要为一个非接口方法加事务,需要配置动态代理为cglib的动态代理;
代理
JDK动态代理
一次编写到处代理
缺点:被代理的类必须实现某个接口
CGLIB
和JDK动态代理是一样的,但是可以直接对实现类进行操作而非接口,这样会有很大的便利。
参考
循环依赖问题
三级缓存解决
DefaultSingletonBeanRegistry
// 一级缓存
/** Cache of singleton objects: bean name --> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
//三级缓存
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16);
//二级缓存
/** Cache of early singleton objects: bean name --> bean instance */
private final Map earlySingletonObjects = new HashMap(16);
A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,长大成人,
singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象也蜕变完美了!一切都是这么神奇!!
参考
场景一:成员变量引入即A依赖B,B依赖A
在finishBeanFactoryInitialization中,开始初始化A,毋庸置疑通过反射
之后【非完美对象】开始设置属性字段,此时发现需要一个B的对象。同时已标记A处于正在初始化阶段
显然接下来,开始去初始化B的对象,同样的手法,到设置属性阶段,发现需要A对象
于是乎,spring又开始去初始化对象A的依赖,此时先从缓存singletonObjects去取,没有再去看是否正处于初始阶段,是则再从缓存earlySingletonObjects中取,再没有,则看是否存在allowEarlyReference,是则从singletonFactories中取
将早期对象A设置到B中,再把B设置到A中
