搭建环境:
mac,mac OS,python2.7
安装scrapy:
官方网站:https://scrapy.org/
mac下打开终端,输入“pip install scrapy”,如果安装过程中报“Permission denied”错误,遇到权限问题,输入“sudo –H pip install scrapy”

安装成功。
创建第一个爬虫项目:
打开终端命令行,输入“scrapy startproject first_scraper”,回车后开始创建,我遇到了问题“AttributeError: 'module' object has no attribute
'OP_NO_TLSv1_1'”,提示需要“Invalid requirement: 'twisted=13.1.0'”,应该是安装的twisted版本过高(默认安装的17.9)
执行“sudo -H pip install twisted==13.1.0”,安装低版本twisted
安装过程可以看出,把新版本Twisted-17.9.0卸载了,安装完成以后重新执行创建成功。
新建项目的目录结构如下:
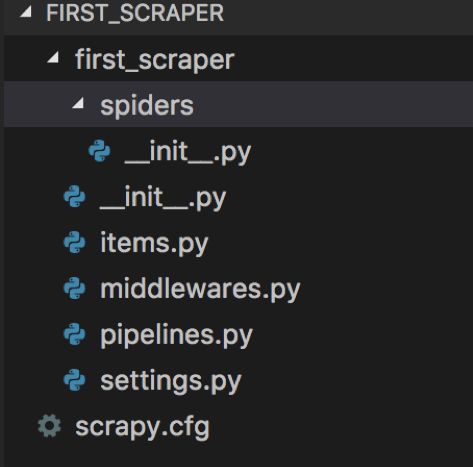
scrapy已经把基础的项目结构搭建好了,
1.spiders目录下可以创建爬虫类,需要继承scrapy.Spiders,主要是爬虫解析及业务实现,创建一个初级的爬虫主要工作在此。
2.middlewares.py是中间件,可以先忽略。
3.scrapy.cfg 配置文件,可以先忽略
4.settings.py 项目的设置,可以先忽略
5.items.py 项目的数据项文件,类似与后台开发,对应数据项的model
6.pipelines.py 数据项的存储实现
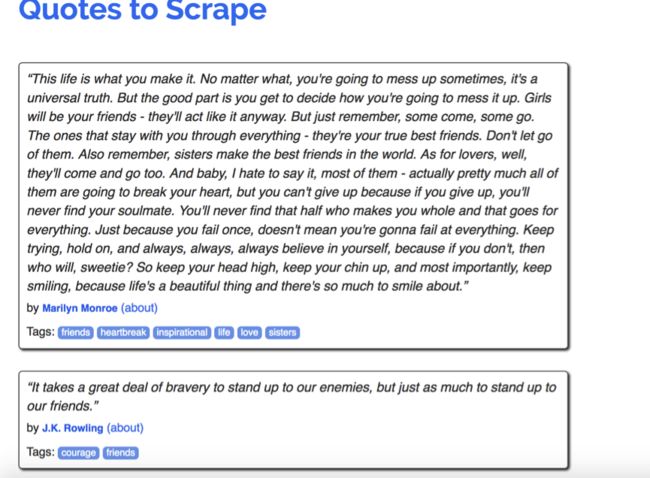
下面实现一个非常简单的爬虫,已scrapy官方文档里提供的网站为目标网站,网址:http://quotes.toscrape.com,网页是一个简单的列表展示,每页10项数据,效果如图:
查看页面的html代码(可以借助firebug等工具),可以看到,每项的html代码如下:
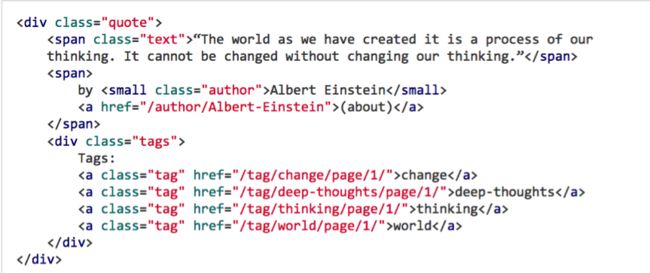
练习爬取每一项的span class ="text"的内容以及
small class=”author”后面的作者
在spiders目录下创建第一个自己的爬虫类demoSpider.py,代码如下:
import scrapy
class DemoSpider(scrapy.Spider):
name ="quotes"
start_urls = ['http://quotes.toscrape.com/']
'''
def start_requests(self):
urls=[
'http://quotes.toscrape.com/',
]
for url in urls:
yield scrapy.Request(url=url,callback = self.parse)
'''
def parse(self,response):
for item in response.css("div.quote"):
text =item.css("span.text::text").extract_first()
author = item.css("small.author::text").extract_first()
print(dict(text=text, author=author))
打开mac上的终端,输入命令scrapy crawl quotes,执行爬虫,执行结果如下:

解释一下代码:
1. import scrapy 引用scrapy库
2. class DemoSpider(scrapy.Spider):创建爬虫类
3. name = "quotes"爬虫的名字,这个名字是在执行scrapy crawl quotes命令时用到的
4. start_urls = ['http://quotes.toscrape.com/'] 这行代码和注释掉的代码效果一样,爬取的初始URL数组
5. def parse(self,response) 数据项解析,循环获取reponse里面的item,然后根据css标记获取到数据,最后打印出来
使用scrapy创建一个非常简单的爬虫就完成了,还是非常容易上手的。
可以参考官方的英文文档,说的很详细:
官方使用说明