一、哈希?
hash,散列,直译为哈希。哈希表,即为散列存储结构,给定一个key值,通过一定的哈希算法f(x),得到给定value的存储位置;
存储位置 = f(key);
常见的hash算法有直接寻址法,除留余数法,等等。
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)
二、存储结构
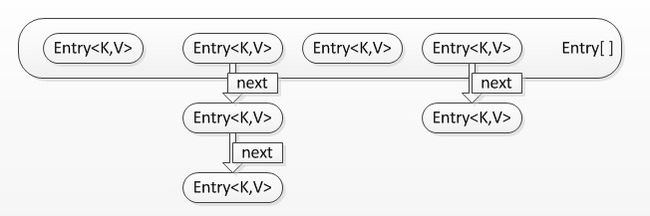
数组 + 链表,图示:
三、重要变量
- DEFAULT_INITIAL_CAPACITY
默认Map容量大小,1<<4 = 16; - MAXIMUM_CAPACITY
Map容量上限,1<<30; - DEFAULT_LOAD_FACTOR
默认(扩容)加载因子,0.75f; - Entry
散列表,对应上面的数组,每一个数组元素便是一个链表; - size
Map的实际大小,即key-value映射关系的数量; - threshold
扩容阈值大小,为Map容量大小 * 加载因子; - loadFactor
加载因子,默认为0.75f;
四、方法详解
1. 初始化
默认散列表为空;
/**
* An empty table instance to share when the table is not inflated.
*/
static final Entry[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table = (Entry[]) EMPTY_TABLE;
有三个构造方法,基础方法如下:
/**
* Constructs an empty HashMap with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
注意threshold = initialCapacity;初始阈值threshold等于初始Map容量initialCapacity,默认为16;
init()是一个空方法;
2. 添加数据
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
注意上面初始化时,散列表Entry数组是空的,并且阈值是等于初始Map容量大小的,那么有必要查看inflateTable方法;
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
一目了然,在第一次put的时候分别初始化了阈值threshold和散列表table的大小,后面initHashSeedAsNeeded初始化hashseed用作hash算法之用,只做了解;
回到put源码,给定的key是null即特殊处理,否则int hash = hash(key);计算出给定key的hash值,int i = indexFor(hash, table.length);得到在散列表table中存储的位置,然后遍历该位置的链表,满足e.hash == hash && ((k = e.key) == key || key.equals(k))即说明该key已经存在映射关系,将新value覆盖旧数据,并返回旧数据oldValue;
如若遍历完该链表未有满足条件元素,则说明是全新的key,需要添加key-value到Map中;
看看addEntry的源码;
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
重点来了,当满足(size >= threshold) && (null != table[bucketIndex])时会发生扩容,也就是说该Map的映射关系key-value的数量不小于阈值threshold,并且该位置上的链表不为空的情况下才会发生扩容;
那么看看真正Map的扩容方法resize;
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
首先是临界条件判断,然后构造一个扩容后的空散列表newTable,通过transfer方法将旧数据传输过去,并重新定义当前Map的散列表table,和阈值threshold;
再回到addEntry中,查看最后一步的createEntry方法;
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
容易看出,就是将新的key-value插入到散列表bucketIndex位置链表的头部,并增加size大小;
3. 获取数据
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
*
A return value of {@code null} does not necessarily
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
相比添加数据而言,获取倒是简单得多,重点查看getEntry这个方法;
/**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*/
final Entry getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
通过给定的key计算出对应value存在散列表中的位置,得到该链表,然后遍历该链表,得到匹配的Entry节点,没有找到便返回null;
这就是大牛们鬼斧神工之处,充分发挥了数组优于查询链表优于插删的特点,给我们开发者编写了如此强大的HashMap,致敬~
五、并发问题
并发中使用HashMap会发生死循环,那么是为什么呢?
上面分析扩容时的resize方法里面的transfer数据传输方法,简单带过,这里具体看看源码;
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
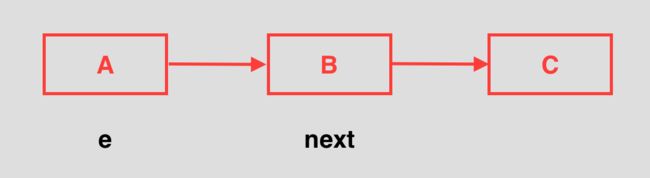
假设有两个线程P和Q同时添加数据发生扩容执行transfer方法,不巧某一个bucket位置有三个元素A、B、C,当P线程执行到Entry时,该链表示意图为:
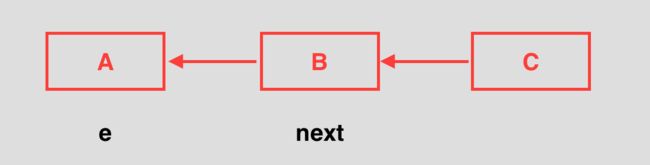
然后切换到Q线程,Q线程执行完transfer方法体后(头插法),该链表指向发生改变:
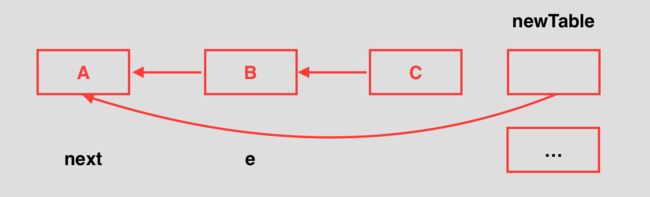
又切换到P线程继续执行,第一次while循环后再次执行Entry后,新的散列表指向示意图:
再次执行while循环体后:
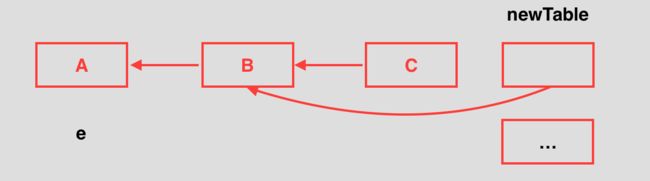
此时e.next是null,但是table[i]是B,继续执行循环,采用头插发将A插到B前面,同时循环体结束,此时该链表则形成环:
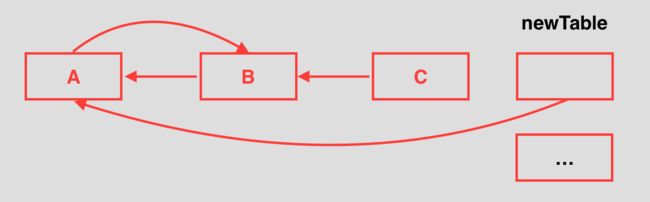
当该链表成环后,再在程序get取值时,并且key刚好对应的bucket是该链表在散列表中的位置,则e.next永远不会为null,导致死循环,严重CPU 100%程序宕机。
因此并发条件下千万不要使用HashMap,可使用ConcurrentHashMap,采用分段锁的机制比HashTable效率更高。顺便提句Collections.synchronizedMap()是给所有接口方法加锁,HashTable与之无异,只不过前者支持所有Map接口的实现,后者只是HashMap的同步类。
六、参考文章
- 哈希表(散列表)原理详解;
- HashMap数据结构
- 老生常谈,HashMap的死循环