代码:
# cross validation 验证检验模型 变现
import numpy as np
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
# train_test_split 经常用,将数据划分为,训练和测试两部分
# 验证模型好坏?
# modelA X_train 预测 X_test accuracy = 0.98
# modelB X_train 预测 X_test accuracy = 0.76
# 得到结论,modelA适合数据,更好的选择
from sklearn.model_selection import train_test_split
X,y = datasets.load_wine(True)
X.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.15,random_state = 112567)
knn = KNeighborsClassifier(n_neighbors=1)
# cv = 5意味着,将数据分成5份
cross_val_score(estimator=knn,X = X_train,y = y_train,scoring = 'accuracy',cv = 5)
array([0.61290323, 0.66666667, 0.73333333, 0.86666667, 0.83333333])
knn = KNeighborsClassifier(n_neighbors=5)
# cv = 5意味着,将数据分成5份
cross_val_score(estimator=knn,X = X_train,y = y_train,scoring = 'accuracy',cv = 5)
array([0.58064516, 0.7 , 0.73333333, 0.7 , 0.73333333])
knn = KNeighborsClassifier(n_neighbors=3)
# cv = 5意味着,将数据分成5份
cross_val_score(estimator=knn,X = X_train,y = y_train,scoring = 'accuracy',cv = 5)
array([0.64516129, 0.7 , 0.76666667, 0.73333333, 0.73333333])
import matplotlib.pyplot as plt
scores = []
for k in np.arange(1,15):
knn = KNeighborsClassifier(n_neighbors=k)
# 平均值
scores.append(cross_val_score(estimator=knn,X = X_train,y = y_train,scoring = 'accuracy',cv = 5).mean())
scores = np.asarray(scores)
plt.plot(np.arange(1,15),scores)
[]
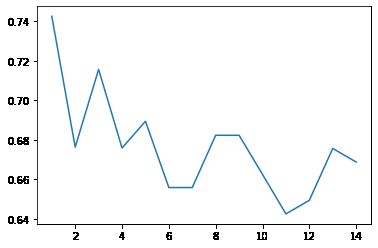
output_6_1.png
根据交叉验证,KNN算法,对于鸢尾花这个数据,邻居数量给 1个的时候,最优的!
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
0.8888888888888888
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
0.8148148148148148
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
0.7777777777777778