学习笔记是学习了 极客时间 - 《MySQL实战45讲》整理的笔记。
影响SQL语句索引值的有序性
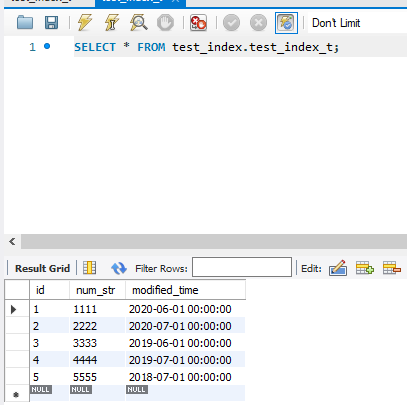
先说结论:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
我们先来创建一张测试表
create table `test_index_t` (
`id` integer NOT NULL,
`num_str` varchar(32) DEFAULT NULL,
`modified_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`num_str`),
KEY `t_modified` (`modified_time`)
)
然后往其中插入5条样例数据
字段含有函数操作
查询数据数据中6月份的所有数据,SQL如下:
SELECT
*
FROM
test_index_t
WHERE
(modified_time >= '2019-06-01'
AND modified_time <= '2019-07-01')
OR (modified_time >= '2020-06-01'
AND modified_time <= '2020-07-01')
explain命令结果如下

我们再来用另外一种方式来查询
SELECT
*
FROM
test_index_t
WHERE
month(modified_time) = 7
explian命令结果如下

经过对比,我们可以看到使用month函数后,MYSQL优化器不会去考虑走modified_time得索引。
还有另外一种方式也可以直观的看出来
隐式类型转换
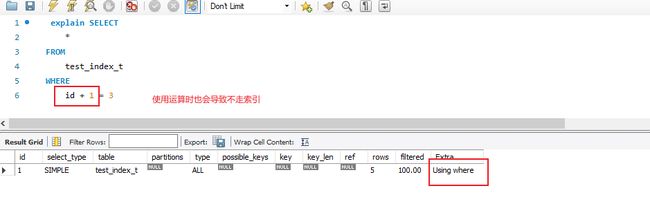
我们在定义表中 num_str 段类型是 varchar(32),如果我们执行如下两个查询SQL,我们看看区别

那么这是为什么呢? MYSQL优化器在执行第一个查询语句的时候,相当于执行
select * from test_index_t where CAST(num_str AS signed int) = 3333;
变向的使用了函数,因此也会影响索引的选择。
隐式字符编码转换
如果两张表T1 编码为 utf8mb4,表T2为utf8,那我们看一下如下的SQL语句
select T2.* from T1, T2 where T2.otherId=T1.otherId and T1.id=2;
我们来看看这条SQL语句的执行过程
- 从T1表中获取到id为2的otherId字段
- T2表中查询匹配到的T1获取的otherId字段
这里T1被称为 驱动表 T2被称为被驱动表。
由于上述过程先T1表中取出字符集为utf8mb4的otherId,然后再去匹配T2表中字符集为utf8的ohterId,由于MYSQL 中字符集 utf8mb4 是 utf8 的超集,所以当这两个类型的字符串在做比较的时候,MySQL 内部的操作是,先把 utf8 字符串转成 utf8mb4 字符集,再做比较。
因此相当于执行了
select T2.* from T1, T2 where CONVERT(T2.otherId USING utf8mb4)=T1.otherId and T1.id=2;
因此 连接过程中要求在被驱动表的索引字段上加函数操作,是直接导致对被驱动表做全表扫描的原因。
MYSQL如何保证数据的不丢的?
首先我们需要回顾一下SQL语句的更新流程

- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁 盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到 新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。 5
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状 态,更新完成。
在这里要注意一点是流程中的redo log commit 不是事务中的commit,这里指的只是一种状态。
binlog的写入机制
原理:事务执行过程中,先把日志写到 binlog cache,事 务提交的时候,再把 binlog cache 写到 binlog 文件中。
这里涉及到了binlog cache:系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控 制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂 存到磁盘。每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
如图所示:
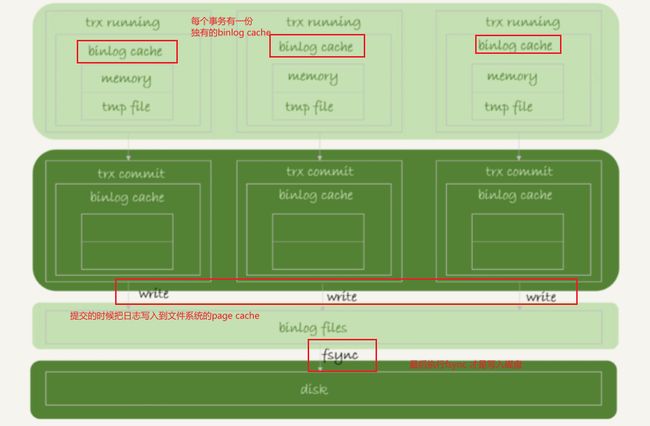
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync; 3
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
如果将 sync_binlog 设置为大于1,如果MYSQL服务异常重启,可能会导致binlog日志中缺少事务日志。
redo log 的写入机制
redo log 三种状态,如图所示

为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参 数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
与此同时,InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写 到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
除了上述的参数配置和MYSQL的默认线程之外还有两种场景会让一个没有提交的事务的 redo log 写入到磁盘中。
- redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时 候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。
- 并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁 盘。假设一个事务 A 执行到一半,已经写了一些 redo log 到 buffer 中,这时候有另 外一个线程的事务 B 提交,如果 innodb_flush_log_at_trx_commit 设置的是 1,那么 按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时候,就会带上事务 A 在 redo log buffer 里的日志一起持久化到磁盘。
通常我们MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要 等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。
组提交(group commit)机制
那么我们将两个参数都设置为1的时候,一个事务进来 redo log日志和binlog日志的就需要写两次磁盘,那么磁盘的写入能力应该是MYSQL TPS的两倍,换句话说 MySQL TPS 是每秒两万的话,每秒就会写四万次磁盘。但是实际上并不是这样,磁盘的写入能力与TPS相差不大,这里需要引入一个概念日志逻辑序列号(log sequence number,LSN)
LSN:
- LSN 是单调递增的,用来对应 redo log 的一个个写入点。每次写入长度为 length 的 redo log, LSN 的值就会加上 length。
- LSN 也会写到 InnoDB 的数据页中,来确保数据页不会被多次执行重复的 redo log。
举个例子:
如下图所示 三个并发事务 (trx1, trx2, trx3) 在 prepare 阶段,都写完 redo log buffer,持久化到磁盘的过程,对应的 LSN 分别是 50、120 和 160。
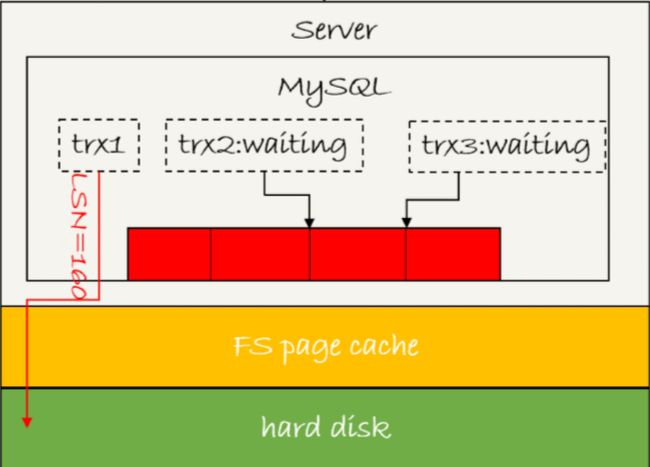
- trx1 是第一个到达的,会被选为这组的 leader;
- 等 trx1 要开始写盘的时候,这个组里面已经有了三个事务,这时候 LSN 也变成了 160;
- trx1 去写盘的时候,带的就是 LSN=160,因此等 trx1 返回时,所有 LSN 小于等于 160 的 redo log,都已经被持久化到磁盘;
- 这时候 trx2 和 trx3 就可以直接返回了
细化日志写入机制流程
我们了解了 binlog和redolog日志的写入机制后,我们可以回顾到最开始的SQL语句的更新流程图,在更新流程图末尾的写双日志的操作,可以细化如下图
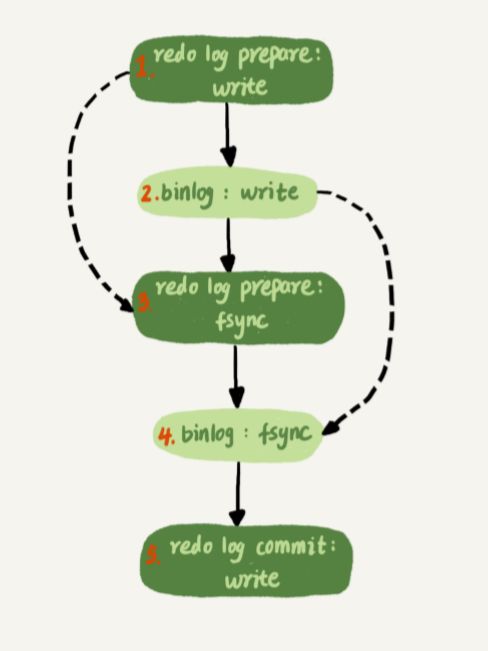
- redo log prepare状态 进行组提交,将redo log写到磁盘上的redo log
- 把binlog 从 binlog cache 中写到磁盘上的 binlog 文件
- 调用redo log fsync持久化
- 调用binlog fsync持久化
- 在执行redo log commit状态的持久化
这样做的好处是多个事务提交的时候 binlog和redo log可以一起持久化,减少IOPS的消耗,提高性能。
数据库异常重启,MYSQL数据的恢复规则?
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并 完整: a. 如果是,则提交事务; b. 否则,回滚事务。
如何判断redo log中的事务与binlog中的事务关联的呢?
它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应 的事务。