声明:转载请声明作者,并添加原文链接。
简介
这篇博客主要解读无监督翻译算法。参考论文是 Lample, Guillaume, et al. "Phrase-Based & Neural Unsupervised Machine Translation." arXiv preprint arXiv:1804.07755 (2018).
链接: https://arxiv.org/pdf/1804.07755.pdf
因为最近实在太忙, 也没时间翻译论文。 博客就用先用英文中文混写记录。 不清楚之处还请多多包涵。 或者留言来问。
Initialization: word-by-word translations to preserve some original semantics.
Language modeling: train language models on both source and target languages.
Iterative Back-translation: leverage monolingual data in a semi-supervised setting
Couple the source-to-target translation
Backward model translation from the target to source language
1. Word-by-word translation using a bilingual dictionary inferred in an unsupervised way is not a great translation
2. Equipped with a language model and the word-by-word initialization, we can now build an early version of a translation system.
3. Next, we treat these system translations (original sentence in Urdu, translation in English) as ground truth data to train an MT system in the opposite direction, from English to Urdu.
Admittedly, the input English sentences will be somewhat corrupt because of translation errors of the first system.
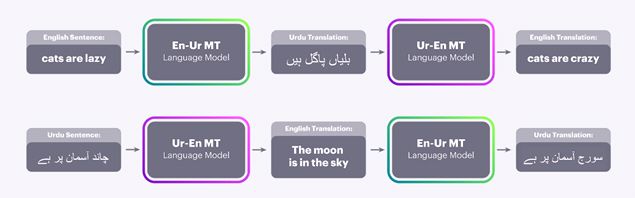
Fig. 1 解释的就是En Ur 两种语言的互相学习过程。 因为没有翻译好的语言对, 就只能使用无监督语言翻译的方法。
Fig.1 的上部分 就是首先将英语用查词典的方式一一对应的翻译成乌尔都语言(Ur).再通过language model, 调整语序, 变成 对应的乌尔都语言。 用这个乌尔都语当做输入, 原本的英语当做label 去训练Ur-En的翻译模型。
Fig.1 的下部分就是用上部分学到的Ur-En 翻译模型 去翻译乌尔都语得到 不太干净的翻译结果, 也就是英语。 这样一个有噪音的输入 再输入En-Ur MT的翻译模型。 Label 是原本的乌尔都语。 Label 是干净的。
上述优化过程交替反复进行。 最后就实现了无监督翻译模型。
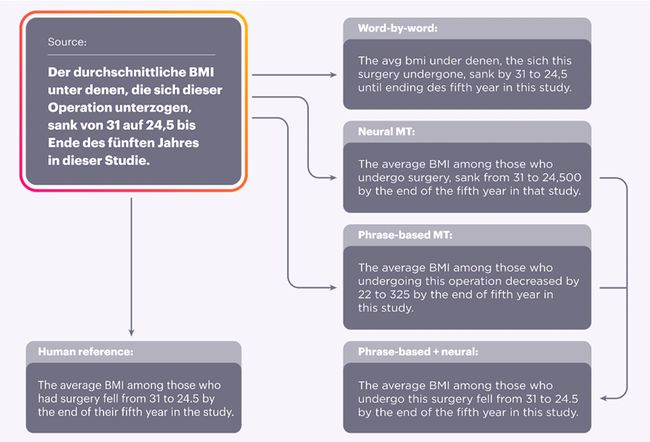
这里发现无监督翻译的话, 传统的词组(phrased-based network)和Neural machine learning 相结合的结果最好。
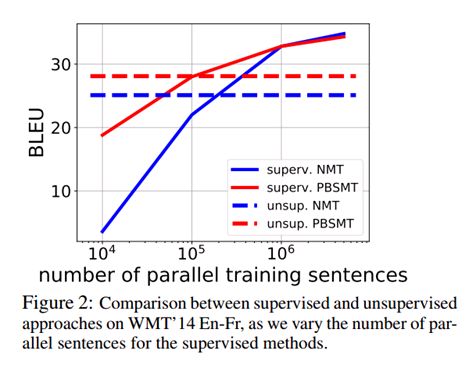
在parallel training sentence,即配对语言数据集比较小的时候, 无监督模型的performance 还比较好。
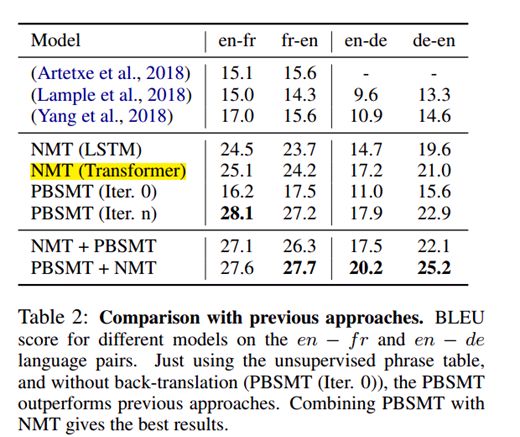
Table 2 show that our unsupervised NMT and PBSMT systems largely outperform previous unsupervised baselines