4.中间件
要求: 能熟练使用、部署、调优、问题排查、懂原理
1.缓存中间件: Redis/Memecache
1.redis有什么缺点
- 缓存和数据库双写一致性问题
- 缓存雪崩问题 (所有key一起失效)
- 缓存击穿问题 (key失效一起访问MySQL)
- 缓存穿透问题 (Redis和MySQL都没有数据)
- 缓存的并发竞争问题 (两个链接同时对一个key的值操作)
2.如何应对Redis 击穿、穿透、雪崩 如何应对并发竞争key
3.单线程的Redis为什么这么快?
多路复用
Resp协议
单线程
内存操作
为什么快:
4.Redis数据类型和使用场景
- String:一般做一些复杂的计数功能的缓存;
- Hash:存储二维数据或对象;
- List:可实现队列,栈及有序的数据存储;
- Set:常用于黑名单,微信抽奖等功能,应用场景多变;
- SortedSet:做排行榜应用,取TOPN操作;延时任务;做范围查找
5.Redis过期策略和内存淘汰机制
惰性删除策略
6.Redis和数据库双写一致性问题
最终一致性和强一致性
强一致性:在任何时刻所有的用户或者进程查询到的都是最近一次成功更新的数据。强一致性是程度最高一致性要求,也是最难实现的。关系型数据库更新操作就是这个案例。
最终一致性:和强一致性相对,在某一时刻用户或者进程查询到的数据可能都不同,但是最终成功更新的数据都会被所有用户或者进程查询到。
强一致性 三种更新策略
理论上给缓存设置过期时间可以保证最终一致性的解决方案,但是在这种方案下,设置过期时间过长会导致错误数据过多,设置过期时间过短会导致影响并发性能问题
- 1.先更新数据库,在更新缓存
- 2.先更新数据库,在删除缓存
- 3.先删除缓存,在更新数据库
第1种,
- 请求A更新数据库
- 请求B更新数据库
- 请求B更新缓存
- 请求A更新缓存
或者:
- 请求A查询缓存发现没有,从数据库拿到旧值
- 请求B更新数据库, 更新缓存
- 请求A把拿到的旧值,更新缓存
因为网络等原因,或者业务代码执行时间原因,会导致脏数据.
MySQL集群,读写分离,查询拿值比写入更快,是最不建议的
第2种,
- 请求A更新数据库,删除缓存
- 请求B拿取数据库旧值,更新缓存
一般因为读写分离,如果两部同时发生,第二步会比第一步更快操作缓存,但是如果有意外发生,可以设置延迟删除,但是如果删除失败呢, 也比较不可取
第3种,
- 请求A删除缓存,更新数据库
- 请求B发现缓存不存在,从数据库拿取旧值,更新缓存
即使用了行锁,请求A和请求B同时执行,请求B先于A从库里读取数据,也会把脏数据存到缓存,同时先删除缓存如果数据库更新失败,缓存无法直接恢复的问题,不可取
延时双删策略
- 先删除缓存
- 更新数据库, 更新缓存
- 再休眠一段时间,再次删除缓存
这么做,可以将一段时间的缓存可能存在的脏数据,再次删除
那么这个一段时间,具体该设置多久呢,即使根据业务设计几百ms,在高并发的场景下也会具有一定的风险性,并且频繁的删除从写,也会影响性能
名为《Cache-Aside pattern》的缓存更新策略中指出
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
目前有一个比较完善的针对第2种解决方案的完善方案
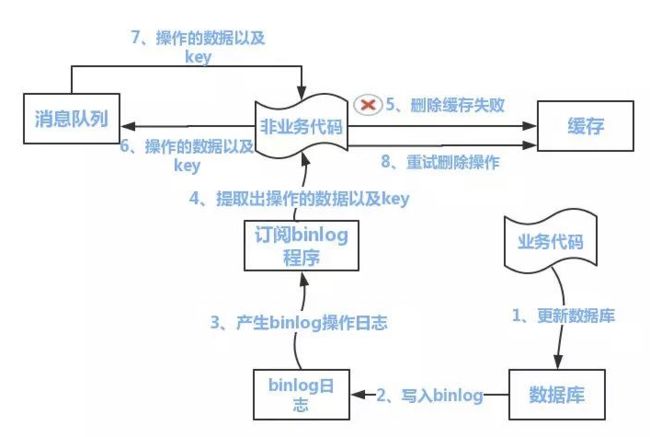
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能.
上述策略略微负责,在时间充裕的时候可以实现,那有么有特殊的场景和过度方法呢?
版本校验策略
如果更新的数据是数字,同时数据的一致性和在一定延时的情况下准确性要求不高,可以考虑
比如点赞,收藏,关注,浏览数等等,把数量当成迭代版本号,数量越大时越是新的数据,采用方案1,先更新数据库在更新缓存,在更新缓存时,先进行比较.如果数量小,就不更新.多数情况下,避免脏数据的产生.
最终一致性
如果对数据一致性和准确性,有严格的一致的要求,
比如商品秒杀、抢购场景.可以直接只使用缓存作为唯一真实来源,等活动结束,背后批量去更新数据库
异构数据库确实很难保持强一致性,利用补偿机制和减少时间窗口的方法,以及设置过期时间兜底,达到最终的一致.
7.CAP原理与强一致性、弱一致性、最终一致性
- 一致性(Consistency)
- 可用性(Availability)
- 分区容忍性(Partition tolerance)
CAP原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向
当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可,考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障“用户感知到的一致性”。通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,“用户感知到的一致性”的时间窗口则取决于数据复制到一致状态的时间。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
- 因果一致性。如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。与进程A无因果关系的进程C的访问遵守一般的最终一致性规则。
- “读己之所写(read-your-writes)”一致性。当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
- 会话(Session)一致性。这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
- 单调(Monotonic)读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
- 单调写一致性。系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
7.Redis布隆过滤器(Bloom Filter)
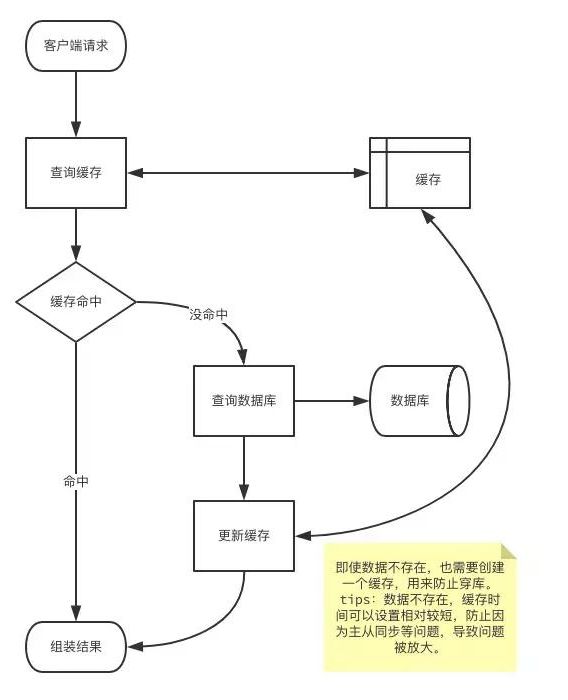
先查询缓存,缓存不命中再查询数据库。 然后将查询结果放在缓存中即使数据不存在,也需要创建一个缓存,用来防止穿库。这里需要区分一下数据是否存在。 如果数据不存在,缓存时间可以设置相对较短,防止因为主从同步等问题,导致问题被放大。
这个流程中存在薄弱的问题是,当用户量太大时,我们会缓存大量数据空数据,并且一旦来一波冷用户,会造成雪崩效应。 对于这种情况,我们产生第二个版本流程:redis过滤冷用户缓存流程
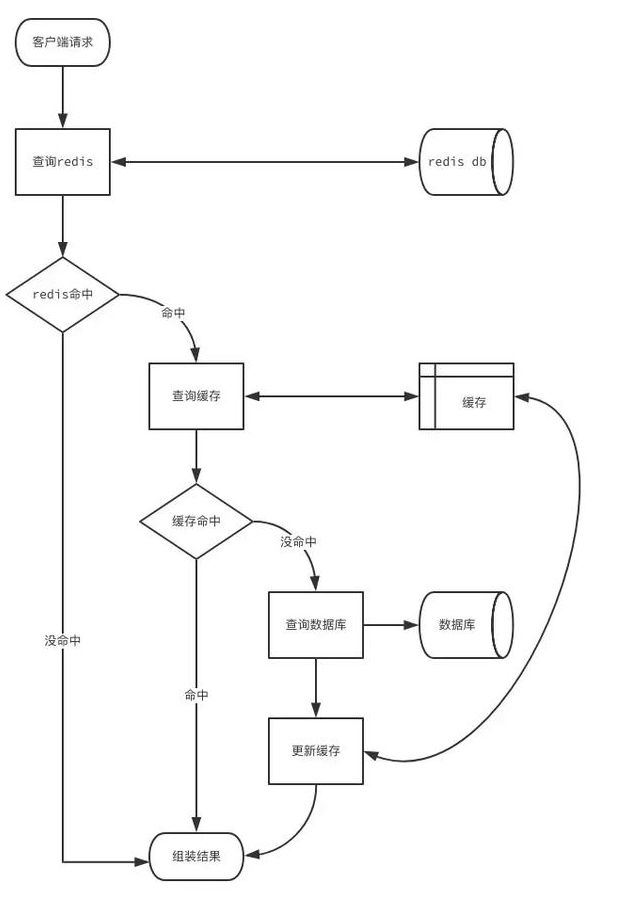
引用链接:https://www.cnblogs.com/yscl/p/12003359.html
什么是布隆过滤器?
本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器原理
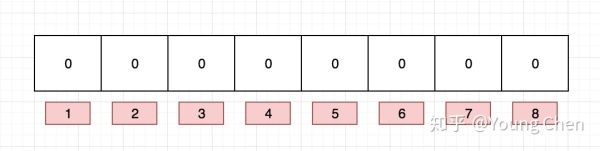
布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3....)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。 需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
下面以网址为例来进行说明, 例如布隆过滤器的初始情况如下图所示:
现在我们需要往布隆过滤里中插入baidu这个url,经过3个哈希函数的计算,hash值分别为1,4,7,那么我们就需要对布隆过滤器的对应的bit位置1, 就如图下所示:

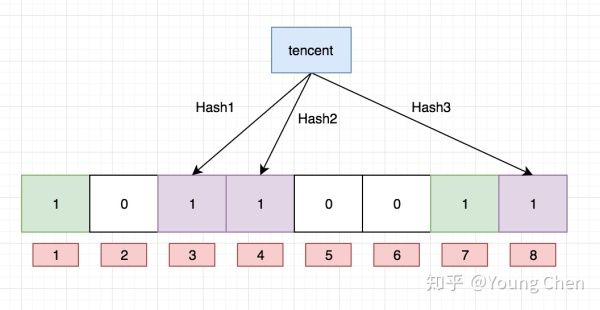
接下来,需要继续往布隆过滤器中添加tencent这个url,然后它计算出来的hash值分别3,4,8,继续往对应的bit位置1。这里就需要注意一个点, 上面两个url最后计算出来的hash值都有4,这个现象也是布隆不能确认某个元素一定存在的原因,最后如下图所示:
布隆过滤器的查询也很简单,例如我们需要查找python,只需要计算出它的hash值, 如果该值为2,4,7,那么因为对应bit位上的数据有一个不为1, 那么一定可以断言python不存在,但是如果它计算的hash值是1,3,7,那么就只能判断出python可能存在,这个例子就可以看出来, 我们没有存入python,但是由于其他key存储的时候返回的hash值正好将python计算出来的hash值对应的bit位占用了,这样就不能准确地判断出python是否存在。
因此, 随着添加的值越来越多, 被占的bit位越来越多, 这时候误判的可能性就开始变高,如果布隆过滤器所有bit位都被置为1的话,那么所有key都有可能存在, 这时候布隆过滤器也就失去了过滤的功能。至此,选择一个合适的过滤器长度就显得非常重要。
从上面布隆过滤器的实现原理可以看出,它不支持删除, 一旦将某个key对应的bit位置0,可能会导致同样bit位的其他key的存在性判断错误。
布隆过滤器的准确性
布隆过滤器的核心思想有两点:
- 多个hash,增大随机性,减少hash碰撞的概率
- 扩大数组范围,使hash值均匀分布,进一步减少hash碰撞的概率。
虽然布隆过滤器已经尽可能的减小hash碰撞的概率了,但是,并不能彻底消除,因此正如上面的小例子所举的小例子的结果来看, 布隆过滤器只能告诉我们某样东西一定不存在以及它可能存在。
关于布隆过滤器的数组大小以及相应的hash函数个数的选择, 可以参考网上的其他博客或者是这个维基百科上对应词条上的结果:Probability of false positives .

上图的纵坐标p是误判率,横坐标n表示插入的元素个数,m表示布隆过滤器的bit长度,当然上图结果成立都假设hash函数的个数k满足条件k = (m/n)ln2(忽略k是整数)。
从上面的结果来看, 选择合适后误判率还是比较低的。
布隆过滤器的应用
- 网页爬虫对URL的去重,避免爬取相同的URL地址
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
- 缓存穿透,将所有可能存在的数据缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
- 黑名单过滤,
布隆过滤器的使用
- Python版,不依赖Redis
安装: pip3 install pybloom_live
from pybloom_live import ScalableBloomFilter
# mode=ScalableBloomFilter.SMALL_SET_GROWTH
sbf = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
url = "皮卡丘1"
url2 = "皮卡丘2"
sbf.add(url)
print(url in sbf) # True
print(url2 in sbf) # False
如果需要去重的数据量不是特别大,推荐用这种方式, BloomFilter(定容)和ScalableBloomFilter(可伸缩的),ScalableBloomFilter超过参数默认值,也可以使用,推荐mode用默认
- Redis中使用布隆过滤器
详细的文档可以参考官方文档。
这个模块不仅仅实现了布隆过滤器,还实现了 CuckooFilter(布谷鸟过滤器),以及 TopK功能。CuckooFilter是在 BloomFilter的基础上主要解决了BloomFilter不能删除的缺点。 下面只说明了布隆过滤器
安装
传统的redis服务器安装 RedisBloom 插件,详情可以参考centos中安装redis插件bloom-filter
127.0.0.1:6379> bf.reserve black_male 0.001 1000
OK
bf.reserve {key} {error_rate} {size} # 创建一个空的名为
key的布隆过滤器,并设置一个期望的错误率和初始大小。{error_rate}过滤器的错误率在0-1之间bf.add {key} {item} # 往过滤器中添加元素。如果key不存在,过滤器会自动创建
bf.madd {key} {item} [item…] # 批量添加
bf.exists {key} {item} # 判断过滤器中是否存在该元素,不存在返回0,存在返回1
bf.mexists {key} {item} [item…] # 批量判断存在