无聊废话
最近在学习HCIE的视频,收藏了几个相关的视频,结果前几天。。。视频被下架了了。。。呃。。。(⊙o⊙)…

视频被下架了。。。我学了一半呀。。。哭。。。
在网上一顿找,依旧找不到。。。
得不到的永远在骚动。。。(歌词。。。)
为了不让自己重蹈覆辙所以我想把我想看的B站视频在“偷偷的”下载下来。。。存到自己的硬盘里。。。嘿嘿嘿。。。
于是说干就干。。。不留遗憾。。。于是打开浏览器 → “如何下载B站视频?” →enter
诶。。。这个是不错
但是尼玛我这里有213个视频呀。。。

我怎么获取下载链接呀?一个一个复制粘贴手会断啊喂。。。
request太难,不会。。。
Beautifulsoup不会。。。
selenium嘿嘿嘿。。。还不手起刀落。。。个屁啊。。。为啥输出有但是实际用Xpath就是没结果呀。。。
算了,我只要一个网页,程序搞不定的活,我搞,反正就一次,我真是天才。。。
好,人工获取网页源码。。。。哔。。。。
使用Xpath读取我的网页文件,然后获取一大堆链接。然后获取一个个链接的列表,so easy。。。
搞定。。。接下来就是到网址那里取下载啦。。。哈哈哈哈。。。
等等。。。213个。。。。
一个一个放到网站点下载,手会断啊喂。。。
果然这个东西不是一次百度可以搞定的。既然如此,那就百度两次。。。
打开浏览器 → “如何批量下载B站视频?” →enter
网上一阵搜索,发现you-get。。。https://github.com/soimort/you-get

OK,fork you!!!

嘿嘿嘿。。。不错,就是你啦,不用图形操作,只要提供一个链接即可下载B站视频,就是你啦。。。(关键还能装逼。。。嘿嘿。。。)
诶。。。等等,我怎们让python运行cmd命令呀。。。
一顿百度,借鉴(copy)之后。。。脚本就写好啦。。。
代码
#coding=utf-8
import requests
import lxml
from lxml import etree
import os
import sys
import you_get
import time
#==========================配置参数====================
#html文件路径
html_path = r'html.html'
#视频保存路径
path = r'G:\bilibili_flv'
#==========================配置参数====================
# 读取html文件
html_doc = open(html_path).read()
# print(html_doc)
mytree = etree.HTML(html_doc)
# print(etree.tostring(mytree))
#用xpath提取下载链接形成list
url_list = mytree.xpath("/html/body/ul //@href")
# print(url_list)
print("列表长度:%s" % len(url_list))
#调用you-get下载视频
def download(url, path):
sys.argv = ['you-get', '-o', path, url]
#使用代理命令: you-get -x 127.0.0.1:1080 [url]
you_get.main()
#上班时间等待
def waiting():
# 规定时间静默
print("等待中。。。")
while True:
# str_time = time.strftime("%Y%m%d%H%M%S", time.localtime())
str_time = time.strftime("%H%M%S", time.localtime())
#9点15分-18点
if int(str_time) >= 91500 and int(str_time) <= 180000:
# print(str_time)
print('.', end="")
time.sleep(60)
else:
print(str_time)
# time.sleep(1)
break
#主程序
if __name__ == '__main__':
i = 1
# 循环下载
for url in url_list:
#定时器
# waiting()
try:
link = "https://www.bilibili.com%s" % url
print('%s 下载中。。。第%s个' % (link, i))
download(link, path)
time.sleep(2)
finally:
i += 1

list-box代码的获取
我的视频链接源代码文件:html.html
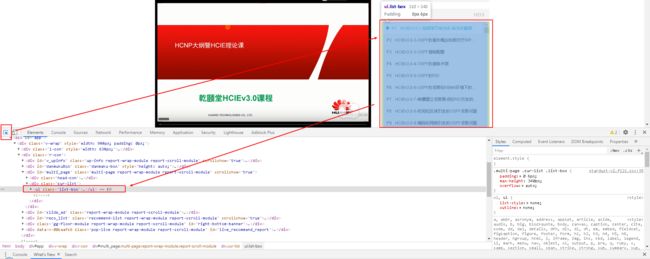
获取方法:Chrome浏览器按F12,选择对应的“list-box”元素,然后:右键→copy→copy outerHTML,将list-box元素代码保存到txt中。
- P1HCIEv3.0-1-如何学习华为IE-华为IE能带来什么好处以及IE做什么
- P2HCIEv3.0-2-OSPF的基本概念和相对于RIP的改进
- P3HCIEv3.0-3-OSPF基础配置
- P4HCIEv3.0-4-OSPF的基础术语
- P5HCIEv3.0-5-OSPF的RID
- P6HCIEv3.0-6-OSPF的邻居和NBMA环境下的邻居
- P7HCIEv3.0-7-单播建立邻居要点和RID引发的问题
- P8HCIEv3.0-8-时间和区域引发的OSPF邻居问题
- P9HCIEv3.0-9-掩码和网络引发的OSPF邻居问题
- P10HCIEv3.0-10-其他链路上网络和掩码引发的OSPF邻居问题
- P11HCIEv3.0-11-开启华为设备上MTU检测引发的OSPF邻居问题
- P12HCIEv3.0-12-介质类型和OSPF网络类型
- P13HCIEv3.0-13-OSPF网络类型基本规则
- P14HCIEv3.0-14-OSPF报文类型和作用
- P15HCIEv3.0-15-OSPF邻接关系建立详解
- P16HCIEv3.0-16-DR BDR基本规则
- P17HCIEv3.0-17-DR回顾和NBMA推荐的网络设计
- P18HCIEv3.0-18-1、2类LSA和SPF计算得到路由
- P19HCIEv3.0-19-OSPF区域间路由即3类LSA
- P20HCIEv3.0-20-3类以及1、2类LSA过滤
- P21HCIEv3.0-21-OSPF防环机制总结
- P22HCIEv3.0-22-OSPF虚连接1
- P23HCIEv3.0-23-虚链路续
- P24HCIEv3.0-24-5类LSA
- P25HCIEv3.0-25-外部路由类型
- P26HCIEv3.0-26-OSPF特殊出去-末节
- P27HCIEv3.0-27-OSPF的完全末节区域
- P28HCIEv3.0-28-OSPF的NSSA区域1
- P29HCIEv3.0-29-OSPF的NSSA细节详解
- P30HCIEv3.0-30-OSPF的区域间汇总
- P31HCIEv3.0-31-OSPF区域间和外部路由汇总
- P32HCIEv3.0-32-OSPF认证类型和方式实施
- P33HCIEv3.0-33-OSPF虚连接认证问题
- P34HCIEv3.0-34-中间系统到中间系统基础
- P35HCIEv3.0-35-中间系统到中间系统基本实施
- P36HCIEv3.0-36-中间系统到中间系统NET地址和 区域概述
- P37HCIEv3.0-37-中间系统到中间系统设备级别和调整
- P38HCIEv3.0-38-中间系统到中间系统的Hello报文和垫片
- P39HCIEv3.0-39-中间系统到中间系统的网络类型和DIS
- P40HCIEv3.0-40-中间系统到中间系统的邻居关系拍错
- P41HCIEv3.0-41-中间系统到中间系统的邻居关系建立和LSP同步
- P42HCIEv3.0-42-中间系统到中间系统的路由泄露基础
- P43HCIEv3.0-43-中间系统到中间系统的路由泄露基础和TAG
- P44HCIEv3.0-44-中间系统到中间系统的汇总
- P45HCIEv3.0-45-中间系统到中间系统的过载位实验
- P46HCIEv3.0-46-中间系统到中间系统的下一跳权重
- P47HCIEv3.0-47-中间系统到中间系统的认证
- P48HCIEv3.0-48-中间系统到中间系统的收敛特性
- P49HCIEv3.0-49-BGP基础概念
- P50HCIEv3.0-50-BGP的EBGP邻居
- P51HCIEv3.0-51-BGP的IBGP邻居和路由
- P52HCIEv3.0-52-BGP的报文类型
- P53HCIEv3.0-53-BGP路由的产生和通告原则
- P54HCIEv3.0-54-BGP通告原则续和重要的下一跳问题
- P55HCIEv3.0-55-多点接入环境下的下一跳行为
- P56HCIEv3.0-56-BGP路由黑洞以及引入方案的风险演示
- P57HCIEv3.0-57-BGP全互联解决方案实施和对等体组案例
- P58HCIEv3.0-58-BGP的同步规则
- P59HCIEv3.0-59-BGP的聚合方式第1部分
- P60HCIEv3.0-60-BGP的聚合第2部分
- P61HCIEv3.0-61-BGP聚合的属性修改
- P62HCIEv3.0-62-基本的路由反射器
- P63HCIEv3.0-63-BGP路由反射器的通告原则
- P64HCIEv3.0-64-BGP路由反射器的防环原则和实施
- P65HCIEv3.0-65-BGP联邦的理念和基本实施
- P66HCIEv3.0-66-BGP的联邦续
- P67HCIEv3.0-67-BGP的团体属性1
- P68HCIEv3.0-68-BGP的团体属性2
- P69HCIEv3.0-69-BGP属性分类
- P70HCIEv3.0-70-BGP选路原则1
- P71HCIEv3.0-71-BGP选路原则2
- P72HCIEv3.0-72-BGP选路原则3
- P73HCIEv3.0-73-BGP选路原则4
- P74HCIEv3.0-74-BGP选路原则5
- P75HCIEv3.0-75-BGP的正则表达式
- P76HCIEv3.0-76-路由引入的定义
- P77HCIEv3.0-77-路由匹配工具ACL
- P78HCIEv3.0-78-路由匹配工具前缀列表
- P79HCIEv3.0-79-次优路由产生以及堵住该路由
- P80HCIEv3.0-80-不当的度量引发的环路以及堵住该路由
- P81HCIEv3.0-81-路由策略的规则以及应用
- P82HCIEv3.0-82-通过修改路由协议优先级解决次优问题
- P83HCIEv3.0-83-路由操控中TAG的应用
- P84HCIEv3.0-84-PBR基于策略的路由
- P85HCIEv3.0-85-路由操控中重要的默认路由
- P86HCIEv3.0-86-MPLS的产生背景
- P87HCIEv3.0-87-MPLS的基本实施案例
- P88HCIEv3.0-88-MPLS架构介绍
- P89HCIEv3.0-89-经典的标签行为
- P90HCIEv3.0-90-LDP的概念以及报文类型
- P91HCIEv3.0-91-LDP会话建立以及拍障
- P92HCIEv3.0-92-基于平台的标签空间和标签分配
- P93HCIEv3.0-93-标签控制和标签保留机制
- P94HCIEv3.0-94-MPLS中LDP的防环以及TTL处理
- P95HCIEv3.0-95-IGP和LDP同步
- P96HCIEv3.0-96-MPLS虚拟私有网络实例
- P97HCIEv3.0-97-MPLS实现VPN实例的RD
- P98HCIEv3.0-98-MPLS实现多协议BGP更新VNv4路由以及验证R
- P99HCIEv3.0-99-MPLS实现客户和PE的路由更新
- P100HCIEv3.0-100-数据转发层面解析
- P101HCIEv3.0-101-MPLS环境下的路由反射器
- P102HCIEv3.0-102-静态方式接入MPLS
- P103HCIEv3.0-103-中间系统到中间系统接入MPLS
- P104HCIEv3.0-104-讨论中间系统到中间系统接入MPLS的防环以及E
- P105HCIEv3.0-105-OSPF协议接入MPLS
- P106HCIEv3.0-106-域ID的作用和OSPF防环机制
- P107HCIEv3.0-107-OSPF的 shamlink作用
- P108HCIEv3.0-108-MCE在OSPF环境下的特殊实施
- P109HCIEv3.0-109-BGP接入MPLS以及MTU
- P110HCIEv3.0-110-组播基础
- P111HCIEv3.0-111-组播IP地址和组播MAC地址
- P112HCIEv3.0-112-组播架构和IGMPv1
- P113HCIEv3.0-113-IGMPv2工作原理
- P114HCIEv3.0-114-实施协议无关组播的密集模式
- P115HCIEv3.0-115-密集模式工作原理
- P116HCIEv3.0-116-RPF检查原理和实验
- P117HCIEv3.0-117-实施PIM的稀疏模式
- P118HCIEv3.0-118-稀疏模式的注册和共享树形成
- P119HCIEv3.0-119-稀疏模式的SPT切换
- P120HCIEv3.0-120-稀疏模式的DR功能
- P121HCIEv3.0-121-BSR方式选举RP
- P122HCIEv3.0-122-SSM和IGMPv3
- P123HCIEv3.0-123-IGMP snooping和代理
- P124HCIEv3.0-124-AS间组播实施和RPF检查
- P125HCIEv3.0-125-交换端口的ACCESS模式
- P126HCIEv3.0-126-交换端口的Trunk模式
- P127HCIEv3.0-127-交换端口的Hybrid模式
- P128HCIEv3.0-128-交换即的MUX VLAN实现
- P129HCIEv3.0-129-路由式代理ARP理论和实验
- P130HCIEv3.0-130-VLAN间代理ARP在超级VLAN的应用
- P131HCIEv3.0-131-VLAN内代理ARP在端口隔离组的应用
- P132HCIEv3.0-132-端口安全理论和实验
- P133HCIEv3.0-133-实施QinQ技术
- P134HCIEv3.0-134-实施手工负载模式的链路捆绑
- P135HCIEv3.0-135-手工负载模式捆绑的特点和调整
- P136HCIEv3.0-136-实施LACP静态模式的链路捆绑
- P137HCIEv3.0-137-STP的背景和本质
- P138HCIEv3.0-138-STP的工作原理和选举根设备
- P139HCIEv3.0-139-STP选举根端口
- P140HCIEv3.0-140-STP选举DP以及其他
- P141HCIEv3.0-141-RSTP报文格式和端口角色
- P142HCIEv3.0-142-RSTP端口角色的增加和端口状态的减少
- P143HCIEv3.0-143-选举新的DP的同步机制
- P144HCIEv3.0-144-RSTP的拓扑改变以及BPDU过滤
- P145HCIEv3.0-145-生成树的保护特性
- P146HCIEv3.0-146-MSTP基础实施
- P147HCIEv3.0-147-MSTP的其他概念和调整
- P148HCIEv3.0-148-DHCP基础
- P149HCIEv3.0-149-分配固定IP地址的DHCP实现
- P150HCIEv3.0-150-基于全局的DHCP实现
- P151HCIEv3.0-151-DHCP中继代理技术的实现
- P152HCIEv3.0-152-DHCP snooping的实现
- P153HCIEv3.0-153-VRRP理论和实践
- P154HCIEv3.0-154-实施BFD
- P155HCIEv3.0-155-GRE基础
- P156HCIEv3.0-156-实施GRE隧道和路由协议
- P157HCIEv3.0-157-安全需求和IPSEC参数
- P158HCIEv3.0-158-站点间虚拟私有网络理论基础和实施
- P159HCIEv3.0-159-IKE概念和框架
- P160HCIEv3.0-160-实施基于IKE的IPSEC站点间的VPN
- P161HCIEv3.0-161-IPSEC的回顾调整以及NAT环境下的解决方案
- P162HCIEv3.0-162-GRE over IPSEC解决方案
- P163HCIEv3.0-163-实施动态智能虚拟私有网络的多点GRE隧道
- P164HCIEv3.0-164-实施动态智能虚拟私有网络的NHRP
- P165HCIEv3.0-165-实施动态智能虚拟私有网络的动态路由协议
- P166HCIEv3.0-166-实施动态智能虚拟私有网络的其他协议和IPSEC
- P167HCIP-18-认识中间系统协议
- P168HCIP-19-中间系统网络实体标题和基本配置
- P169HCIP-20-中间系统路由器类型
- P170HCIP-21-中间系统报文类型和网络类型
- P171HCIP-22-中间系统邻居关系建立和电路调整
- P172HCIP-23-中间系统邻居关系和3次握手
- P173HCIP-24-中间系统知识串讲
- P174HCIP-25-中间系统的LSP交互
- P175HCIP-26-基本的中间系统路由泄露
- P176HCIP-27-中间系统的收敛
- P177HCIP-76-IPv6基础和地址分类
- P178HCIP-77-IPv6单播地址
- P179HCIP-78-IPv6组播地址和其他
- P180HCIP-79-IPv6报文头部解析
- P181HCIP-80-IPv6邻居发现-解析
- P182HCIP-81-IPv6邻居发现-跟踪邻居状态和地址重复
- P183HCIP-82-IPv6-无状态自动配置
- P184HCIP-83-OSPFv3概述和基本配置
- P185HCIP-84-OSPFv3和OSPFv2的区别
- P186HCIP-85-RA中的M和O以及DHCPv6实施
- P187QoS1-QoS概念和基本理论
- P188QoS2-QoS中的重要参数详解
- P189QoS3-报文头部中的分类字段和实验
- P190QoS4-QoS的任务实施方向问题
- P191QoS5-华为设备实施分类和标记
- P192QoS6-模拟器上实施QoS的分类和标记
- P193QoS7-QoS软硬件队列
- P194QoS8-队列要素和FIFO
- P195QoS9-PQ优先级队列和实施
- P196QoS10-CQ自定义队列概述
- P197QoS11-CQ队列以及实施
- P198QoS12-WFQ详解1
- P199QoS13-WFQ详解2
- P200QoS14-实施CBQ
- P201QoS15-实施CB-WFQ和LLQ
- P202QoS16-WRED理论和华为基于流的WRED
- P203QoS16-实施MQC的WRED
- P204QoS17-限速基本概念
- P205QoS18-令牌桶概念和工作机制
- P206QoS19-令牌桶机制2
- P207QoS20-在华为设备实施监管即限速以及基于每IP限速
- P208QoS21-实施思科的基于类的监管
- P209QoS22-整形理论和实施
- P210QoS23-简单的链路效率实施
- P211补充-MPLS MTU问题解决方案
- P212补充-针对VN实例的控制策略
- P213补充-静态LSP实现