R数据分析:数据清洗的思路和核心函数介绍
好多同学把统计和数据清洗搞混,直接把原始数据发给我,做个统计吧,这个时候其实很大的工作量是在数据清洗和处理上,如果数据很杂乱,清洗起来是很费工夫的,反而清洗好的数据做统计分析常常就是一行代码的事情。
Data scientists only spend 20% of their time creating insights, the rest wrangling data.
想想今天就给大家写一篇数据处理的常用函数介绍吧。全是自己的一丢丢经验,肯定不会是最优的,仅仅是给个参考,因为在R中同一个目的的实现方法太多了,找到适合自己的才是最好的。我争取尽量清晰地一步一步给大家展示一下整个清洗数据的流程。
在R语言中我们会用一系列的方法把我们的数据清洗过程连起来,整个的思路就是从原始数据开始,一步一步形成我们的最终可以用来做统计的数据。
整体上我们数据处理的步骤可以包含下面5个部分,也是有顺序的5步:
- Importing of data(数据导入)
- Column names cleaned or changed(列名的清洗转换)
- De-duplication(去重)
- Column creation and transformation (e.g. re-coding or standardising values)(生成新变量)
- Rows filtered or added(数据选择)
本文就带着大家一步一步走一遍,中间会详细说明一些核心函数的用法,希望对大家有点帮助。当然了,以下内容默认您已经理解dplyr包的基础,比如Pipes%>%符号。
数据导入
数据导入大家应该都没有问题,就算有问题网上搜搜一般都可以解决,导入数据的方法有很多种,这儿会推荐大家直接用右上角的菜单import data,或者使用rio包的import函数。我现在有一个已经导入的原始数据raw如下图:
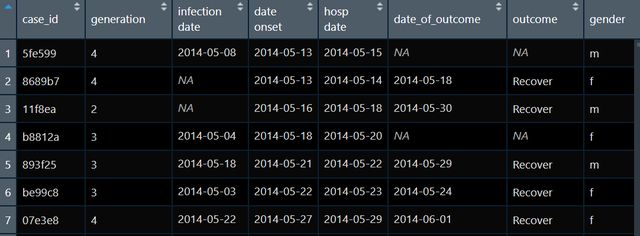
数据导入进来之后我们首先应该整体上看看变量类型,变量名称都是如何的,以此决定我们是不是将变量名初步改改,或者变量类型也得改改,就是首先得有个整体把握,此时推荐大家运行一下skim函数,这个是帮助我们了解数据整体形式的十分方便的函数,请大家把summary忘掉,直接运行skim:
skimr::skim(raw)函数的输出包括整体的数据有多少行多少列,列的不同类型(数值,字符,时间)有几种,然后不同的列的类型还会输出我们关心的指标,比如字符型的列都会有每一列的缺失比例,极值,非重复值,空白等:

比如对于每一个数值型的列都会有缺失数量,均值标准差百分位数,直方图等等我们关心的东西:

反正就是大家用skim函数就可以从整体上把握住我们的数据的样子了。
另外还会推荐大家用names函数看看数据的列名,有了对数据集的整体把握和全部的变量名,我们可以紧接着进行下一步:变量名的转换。
列名的清洗转换
转化的目的就是使得之后的操作调用变量可以更加的清晰和方便,我可以瞅瞅我的原始数据的列名:
names(raw)
在查看列名时我们需要关注一下列名是不是符合以下要求:
- 在可读性高的情况下尽可能短
- 没空格
- 没有特殊字符(&, #, <, >, …)
- 样式统一(e.g. all date columns named like date_onset, date_report, date_death…)
对照上面的标准我们其实就可以知道目前我的原始数据raw的列名中,infection date中出现了空格,date onset . infection date这两个列名的也有空格而且形式应该统一以下比较好;然后…28这个列名有特殊符号,这些最好都先得改改。
当我们的数据集非常大的时候,比如有好几千个变量的时候,改列名或者列名统一也是一件比较繁琐的事情,这个时候会推荐大家用clean_names()函数自动修改一下,之后再写代码微调,这样对大型数据库处理起来可以节省大量时间,对我们的数据raw我们可以写出如下代码:
data <- raw %>%
janitor::clean_names()运行上面的代码后我们再看data的列名就可以发现至少特殊字符和空格的问题统统都没有了:

上面属于粗犷的处理,但是还有其它的问题,反正实际情况中大家也免不了需要改列名的,此时可以用rename函数进行列名的手动修改,基本格式是新名=旧名,如下:
raw %>%
janitor::clean_names() %>%
rename(date_infection = infection_date,
date_hospitalisation = hosp_date,
date_outcome = date_of_outcome)运行代码后我们就可以看到所有设定的列名都被改好了。
很多时候我们是从一个很大的微观数据库中摘变量来分析的,就是常常我们只需要那些我们用得着的变量,这时可以用select函数,这个大家用的比较多,这儿分享几个在使用select的时候的辅助函数,将这些辅助函数和select结合起来会使得效率更高,这些函数有一个统一的名字叫做“tidyselect” helper functions,常见的如下图:

比如我就想选择所有的数值型变量来分析我就可以写出如下代码:
select(where(is.numeric))比如我就想找变量名中包含某个字符的变量,我就可以用contain函数,比如我现在手里是一个母子配对数据集,变量既有母亲的也有孩子的,我就可以用contain方便滴筛选出来母子的年龄:
select(contains("age"))上面的代码会将所有包含“age”这个字符串的变量都筛出来;同样的道理我们还可以用ends_with() and starts_with()筛出来大型数据集中以某个字符开头和结尾的列,比如一个纵向随访数据集每一波的cesd都是以cesd开头为列名的我们就可以用starts_with()将所有随访的cesd都筛出来。还有matches()函数也可以帮助实现列名的匹配筛选,比如在raw数据中,用如下代码就可以筛选出所有列名中含有“onset”,“hosp”,“fev”的列
raw %>%
select(matches("onset|hosp|fev")) %>%
names()![]()
上面一步就实现了将fever的发病时间,入院时间,住院时长这些变量都筛出来,指导这些操作在处理大型数据库的时候就会省事很多。
反正,整体的操作都是非常灵活的,会有很多细节需要学习,但是大家要掌握的是我知道有这么一个函数可以解决这个问题,我就先记住函数名,具体细节可以边用边查,整体的学习过程就是这样。
新变量生成和变量转换
在数据处理中我们还会涉及到变量的改变和根据原有变量生成新变量,变量生成和转换都可以用mutate来实现,具体规则就是:
mutate(new_column_name = value or transformation)就上面这个式子,用起来可就是包罗万象,比如在你的数据中有身高体重,我想计算一个新的变量叫做bmi,则可以写出代码如下:
mutate(bmi = wt_kg / (ht_cm/100)^2)还有很多的新变量生成和转换的应用场景,比如完全复制一个变量,新列全是7,用另外的变量计算,两个变量的值贴一起形成新变量:
raw%>%
mutate(
new_var_dup = case_id, # 完全复制
new_var_static = 7, # 新列全是7
new_var_static = new_var_static + 5, #用另外的变量计算新变量
new_var_paste = stringr::str_glue("{hospital} on ({date_hospitalisation})") # 两个变量的值贴一起形成新变量
) 还有很多很多的操作都是在mutate中完成的。
我们常常还会有的需求是一次性处理好多个变量,比如一次性将所有的变量都转换为字符类型,这个时候为了代码的整洁统一我们依然可以用mutate和across,结合.cols和.fns参数就行,比如下的代码就是将3个列全部转换为字符串,大家不用特意再去用lapply或者写循环什么的:
raw %>%
mutate(across(.cols = c(temp, ht_cm, wt_kg), .fns = as.character))还有几个小技巧,比如我想将数据库的所有列都进行某一个操作,我不用将所有的列名都敲出来,只需要用everything函数就可以,比如用下面的代码就实现将数据的所有列转换为字符型:
raw %>%
mutate(across(.cols = everything(), .fns = as.character))大家把握住一个原则就是列的生成转换就是用mutate就行,然后涉及到选择的时候我们一定记得要结合辅助函数“tidyselect” helper functions。要有这个意识。
还有一个函数要给大家介绍一下就是coalesce()
很多时候我们一个变量有两种测量方式,比如有自我报告的体重,还有物理测量的体重,我们通常的想法是以物理测量的为准,当物理测量有缺失我们用自我报告的数据来填补,这么一个过程我们就可以用coalesce函数一步搞定,如下:

所以说我们在使用mutate的时候我们可以根据需要结合coalesce函数,比如下面的代码就实现了在raw数据集中当village_detection缺失时用village_residence的值填补:
raw %>%
mutate(village = coalesce(village_detection, village_residence))- 变量重新编码
变量重新编码也是常见的操作,它也是属于变量转换的大框框里面的,所以我们依然是用mutate,比如在我们的raw数据中,我们有个变量hospital,这个变量有很多的水平,其实好多水平是一样的:
table(raw$hospital, useNA = "always") 
这种情况在我们自己录入的数据库中经常会出现
就是"Mitylira Hopital"和"Mitylira Hospital",和"Military Hopital"其实都可以看成是录入的时候录错了,其实他们都是"Military Hospital",这个时候我们要做的就是重新编码变量,可以用mutate和recode实现我们的需求:
raw%>%
mutate(hospital = recode(hospital,
# for reference: OLD = NEW
"Mitylira Hopital" = "Military Hospital",
"Mitylira Hospital" = "Military Hospital",
"Military Hopital" = "Military Hospital",
"Port Hopital" = "Port Hospital",
"Central Hopital" = "Central Hospital",
"other" = "Other",
"St. Marks Maternity Hopital (SMMH)" = "St. Mark's Maternity Hospital (SMMH)"
))上面的代码运行完,我们再看相应的错误的录入都正确地归为相应水平了
大家还应该掌握的使用逻辑判断进行变量重新编码的方法,这个时候需要用到replace(),ifelse()andif_else()和case_when(),给大家写一个case_when的例子,这个函数就是在我们需要根据某个变量的值生成新变量的时候使用,比如我们根据age_unit的不同取值,生成新变量age_years,我们就可以用case_when():
raw %>%
mutate(age_years = case_when(
age_unit == "years" ~ age,
age_unit == "months" ~ age/12, # 年龄单位为月,age_years就等于年龄/12
is.na(age_unit) ~ age, # 年龄单位缺失的话,默认成“年”,age_years就等于age
TRUE ~ NA_real_)) #其余所有情况都归为age_years缺失在使用case_when的时候我们可以将想设定的都设定好,余下的情形都可以用关键字TRUE代表,就想上面代码的最后一行那样,对于age_unit这个变量的其余的所有情况我们都认为age_years为缺失。
- 缺失值替换
缺失值转换依然可以在mutate中完成,因为它依然是在变量转化的框架里:
因为我们的hospital这个变量其实是有很多的缺失值的,我们希望将相应的缺失值都替换成missing,我们就可以写出如下代码:
raw %>%
mutate(hospital = replace_na(hospital, "Missing"))有一种情况需要注意,就是因子变量中有NA,我们如果用replace_na会报错,上面代码中hospital变量是字符型的,所以没有问题。就是对于一个因子来讲,它本身水平就是固定的,有了NA,我们将NA进行替代,比如替代成missing,其实missing它并不是因子原来本身的一个水平,所以会报错,这个时候我们可以用fct_explicit_na()函数。
fct_explicit_na()函数会直接将因子变量中的NA进行相应的替换,替换的值也自动成为该因子的一个水平。
- 数值变量转分类变量
就是说我们有时候想将连续变量转成分类变量分析,这个时候常常会用到的函数有age_categories(),cut(),quantile(),ntile()
看一个age_categories()的例子:
raw%>%
mutate(
age_cat = age_categories(
age_years,
breakers = c(0, 5, 10, 15, 20,
30, 40, 50, 60, 70)))上面的代码就将age_years这个连续变量化成了分类变量,分的节点就是breakers参数的向量中,quantile(),ntile()则可以帮助我们快速地划分节点。分类过后就可以用table函数查看每个类别的数量,上面的代码就是将连续变量age_years用breakers参数中的点进行了划分,划分后形成了分类变量,结果如下:

有时候我们对划分的结果会不放心,比如这个类别到底是开区间还是闭区间,当然这些都是有参数可以调的,为了确认我们也可以做交叉表格,我么可以把原来的连续变量和生成的分类变量进行交叉:
table("Numeric Values" = raw$age_years,
"Categories" = raw$age_cat,
useNA = "always") 通过这么样一个操作我们就可以判断是不是相应的连续变量都被正确地划分到了相应的类别中:

还有一种比较特别的需求,我们虽然想按连续变量分组,但是我想每个组的人数相同,这个时候结合ntile()就可以实现,比如我想把age_years化成分类变量,且规定每一类人数相同,我就可以写出如下代码:
ntile_data <- raw %>%
mutate(even_groups = ntile(age_years, 10))去重
去重大家就去研究一个函数,叫distinct就行。
行的过滤和添加
给数据库的行进行改变大家都会,但是要在原先的数据框中间插入一行怎么办呢?
可以用addrow,比如我想在原来的数据集raw的第二行之前插入一行,我可以用如下代码:
raw %>%
add_row(row_num = 666,
case_id = "abc",
generation = 4,
`infection date` = as.Date("2020-10-10"),
.before = 2)该行的每一个变量都需要规定一下,没设定的都会空着,.before = 2的意思就是在原来数据框的第二行之前插入。
- 按规则进行行的选择
选择行也是用的比较多的,比如我就想选性别为女的行,或者我就想选择某些变量没有缺失的行等等,选择行我们是用filter,但是在以是否缺失为条件的时候大家不要去用filter(!is.na(column) & !is.na(column))这个时候推荐大家用drop_na,通过drop_na就可以将某个变量有确实的行全拿掉。
- 横向计算
正常我们计算变量都是纵向依次计算的,比如最开始写的BMI计算的例子,有时候我们需要对一个观测的多个变量进行计算,比如一个病人有好多症状,我想对每个病人症状个数求和,本质上这是一个横向计算的问题,我就可以使用rowwise()函数,用完之后记得ungroup()一下:
row %>%
rowwise() %>%
mutate(num_symptoms = sum(c(fever, chills, cough, aches, vomit) == "yes")) %>%
ungroup() %>%
select(fever, chills, cough, aches, vomit, num_symptoms) 比如上面的代码就计算好了每一个病人的症状个数。
小结
今天给大家写了数据处理中的一些函数和处理的一般流程:导入数据后先整体把握,第二步规范列名,列搞定之后第三步就是去重,去完重就是生成新变量,变量转换;最后一步就是行的选择和添加。每一个步骤中给大家写了一点点例子,感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先记得收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,有疑问欢迎私信。