卷积神经网络详解
一个详解的链接(重要重要):通俗易懂:图解10大CNN网络架构 - 知乎
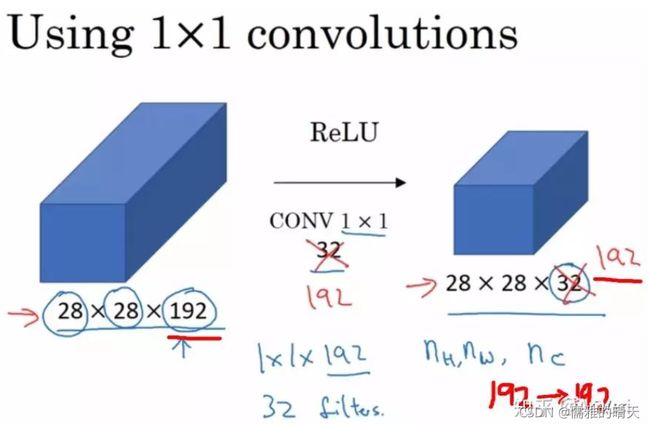
1x1卷积核
一文读懂卷积神经网络中的1x1卷积核 - 知乎
1x1卷积核,又称为网中网(Network in Network)。
- 降维/升维
当输入为6x6x32时,1x1卷积的形式是1x1x32,当只有一个1x1卷积核的时候,此时输出为6x6x1。此时便可以体会到1x1卷积的实质作用:降维。当1x1卷积核的个数小于输入channels数量时,即降维。
1x1卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度。

- 增加非线性 在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
备注:一个filter对应卷积后得到一个feature map,不同的filter(不同的weight和bias),卷积以后得到不同的feature map,提取不同的特征,得到对应的specialized neuron。
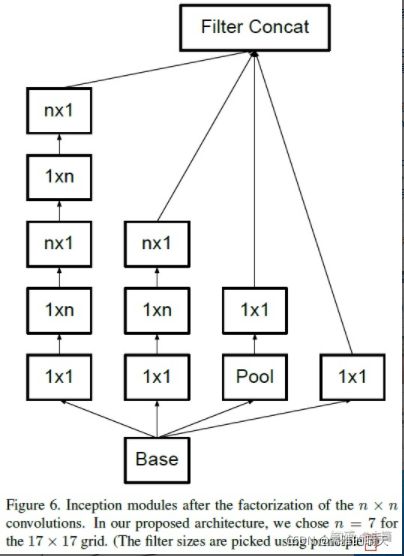
非对称卷积(Asymmetric Convolution)
减少运算量。
先进行一次n×1卷积,再进行一次1×n卷积,和直接进行n×n卷积的结果是一致的,但乘法运算的规模从n×n变成了2×n——所以n越大,非对称卷积降低运算量的效果越明显。
虽然可以降低运算量,但这种方法不是哪儿都适用的,非对称卷积在图片大小介于12×12到20×20大小之间的时候,效果比较好。
ResNet:深度残差网络(Deep residual network)
ResNet有架构上的trick:残差学习(Residual learning)。
退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。
残差学习来解决退化问题。
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。
CNN中的3x3卷积核,5x5卷积核,9x9的卷积核区别在哪里?
1. 卷积核从小到大,运算量递增
2.卷积核从小到大,感受野范围递增
四个3x3的卷积核累加卷积才能达到一个9x9卷积核所对应的感知野,但是所需要的参数量更少,且产生了更多的特征。
基于对图片认识,如果图片复杂,建议使用3*3卷积核。如果类似风景图片,大海,特征不复杂。可以使用9*9。卷积核小,参数少,特征多。
为什么可以对卷积后的图像进行池化操作?
图像中的相邻像素倾向具有相似的值,因此通常卷积层相邻的输出像素也具有相似的值,这意味着卷积层输出中包含的大部分信息都是冗余的。
Inception 结构:融合不同尺度的特征信息。
GoogLeNet的亮点:
inception(也称GoogLeNet)是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
- 引入了inception结构,融合不同尺度的特征信息。
- 使用1x1的卷积核进行降维及映射处理。
- 添加两个辅助分类器帮助训练。(AlexNet 和VGG都只有一个输出层,GoogLeNet有三个输出层(其中两个辅助分类层)。
- 丢弃全连接层,使用平均池化层(大大减少模型参数)。


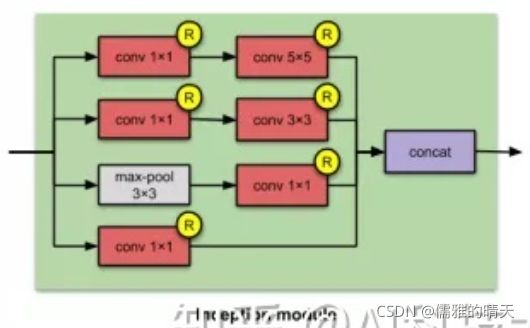
Inception模块:

Inception V3:
与之前的Inception-v1版本相比,有哪些改进?
- 把 n×n 卷积分解成不对称的卷积 1×n and n×1 卷积。
- 把 5×5 卷积分解成 2 个 3×3 卷积操作
- 把 7×7 卷积替换成一系列 3×3 卷积。
多个尺寸上进行卷积再聚合?
- 在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
- 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
MobileNet:是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络,相比于传统的卷积神经网络,在准确率小幅度降低的前提下大大减少模型参数与运算量。(相比于VGG16准确率减少了0.9%, 但模型参数只有VGG的1/32).
网络中的亮点:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数
 :控制卷积层卷积核个数和输入图像大小(是人为自己设定的而不是学习到的)
:控制卷积层卷积核个数和输入图像大小(是人为自己设定的而不是学习到的)
MobileNet V2 (2018年)相比于V1 准确率更高,模型更小。
亮点:
- Inverted residuals(倒残差结构)
- Linear Bottlenecks

残差结构:先降维再升维,两头大中间小的bottleneck。
倒残差结构使用ReLU6激活函数。
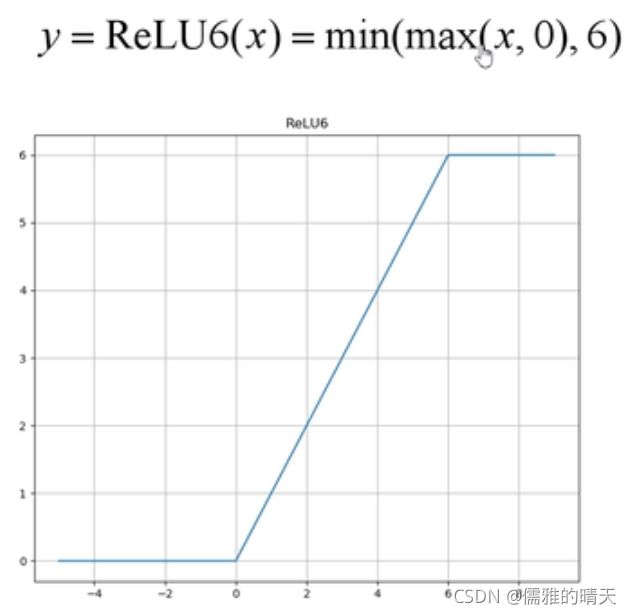

(使用线性激活函数用来避免信息损失,因为ReLU会造成低维特征信息损失)
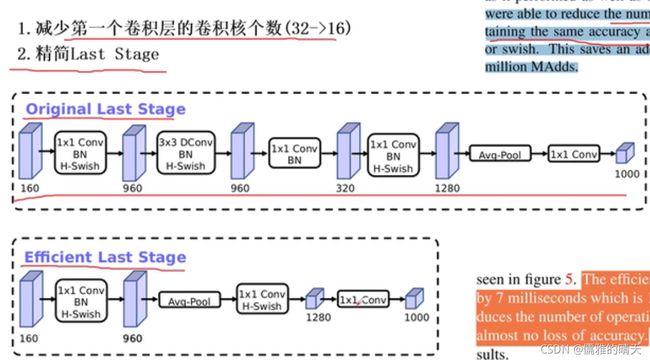
MobileNet V3亮点:
ResNet(2015):
亮点:
超深的网络结构(突破1000层)
提出residual模块
使用batch normalization加速训练(丢弃dropout):BN的目的是使我们的一批(Batch) feature map满足均值为0,方差为1的分布规律。
迁移学习:

