「自然语言处理(NLP)」自然语言生成(NLG)论文整理(一)
来源: AINLPer 微信公众号(点击了解一下吧)
编辑: ShuYini
校稿: ShuYini
时间: 2020-02-27
引言: 下面是作者整理的关于自然语言生成(NLG)相关的论文文章,能找到源码的作者也直接贴出来了,如果你对NLG感兴趣或者也在找一些相关的文章,希望能够帮助你~~
如果你一篇篇的论文下载不方便,你也可以关注 AINLPer 回复:NLG001 进行打包下载。
TILE: Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation
Author: Yu Chen, Lingfei Wu, Mohammed J. Zaki
Paper:https://openreview.net/pdf?id=HygnDhEtvr
Code: https://github.com/hugochan/RL-based-Graph2Seq-for-NQG
论文简述: 本文提出了一种基于增强学习(RL)的QG图序列(Graph2Seq)模型。该模型由一个带有双向门控图神经网络编码器的Graph2Seq生成器和一个混合评估器组成,该混合评估器将交叉熵和RL损耗结合起来,以确保生成的文本在语法和语义上都是有效的。
TILE: Data-dependent Gaussian Prior Objective for Language Generation
Author: Zuchao Li, Rui Wang, Kehai Chen, Masso Utiyama, Eiichiro Sumita, Zhuosheng Zhang, Hai Zhao
Paper:https://openreview.net/pdf?id=S1efxTVYDr
Code:https://drive.google.com/file/d/1q8PqhF9eOLOHOcOCGVKXtA_OlP6qq2mn
论文简述: 语言生成问题,最大似然估计(MLE)被普遍采用,但是MLE忽略了负多样性,所以本文通过引入一个额外的Kullback-Leibler散度项来增加MLE损失,这个散度项是通过比较依赖于数据的高斯先验和详细的训练预测得到的。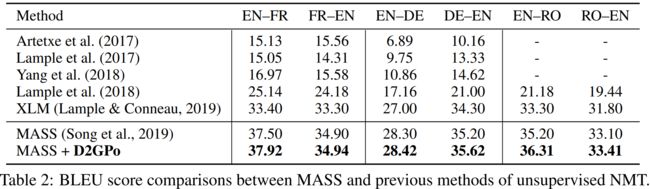

TILE: code2seq: Generating Sequences from Structured Representations of Code
Author: Uri Alon, Shaked Brody, Omer Levy, Eran Yahav.
Paper:https://openreview.net/pdf?id=H1gKYo09tX
Code: None
论文简述: 本文提出了code2seq模型,一种利用编程语言的语法结构来更好地编码源代码的替代方法。模型将代码片段表示为其抽象语法树(AST)中的一组组合路径,并在解码时注意选择相关路径。
TILE: Execution-Guided Neural Program Synthesis
Author: Xinyun Chen, Chang Liu, Dawn Song.
Paper:https://openreview.net/pdf?id=H1gfOiAqYm
Code: None
论文简述: 大多数现有的神经程序合成方法都采用编码器-解码器结构,但是现有方法的主要缺点是语义信息没有得到充分利用。为此本文提出了两种简单而有原则的技术来更好地利用语义信息,这两种技术是执行引导合成和合成器集成。这些技术足够通用,可以与任何现有的编码器-解码器风格的神经程序合成器相结合。
TILE: Representation Degeneration Problem in Training Natural Language Generation Models
Author: Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, Tieyan Liu.
Paper:https://openreview.net/pdf?id=SkEYojRqtm
Code: None
论文简述: 研究了基于神经网络的自然语言生成任务模型训练中出现的表示退化问题,提出了一种新的正则化方法。语言建模和机器翻译的实验表明,该方法能有效地缓解表示退化问题,并获得比基线算法更好的性能。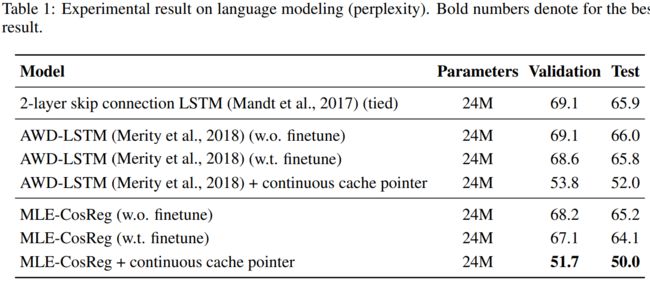

TILE: MaskGAN: Better Text Generation via Filling in the ___
Author: William Fedus, Ian Goodfellow, Andrew M. Dai.
Paper:https://openreview.net/pdf?id=ByOExmWAb
Code: None
论文简述: 介绍了一个有条件的GAN,它可以根据周围的环境条件来填充缺失的文本。我们从定性和定量两方面证明,与最大似然训练模型相比,这种方法可以生成更真实的文本样本。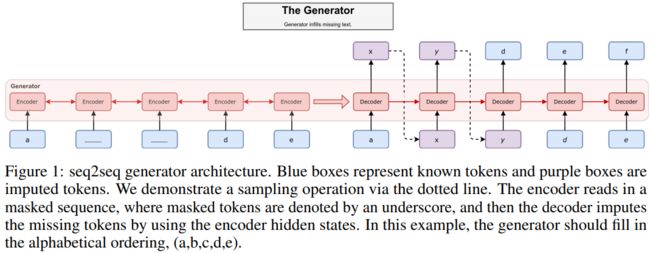
TILE: Leveraging Grammar and Reinforcement Learning for Neural Program Synthesis.
Author: Rudy Bunel, Matthew Hausknecht, Jacob Devlin, Rishabh Singh, Pushmeet Kohli.
Paper:https://openreview.net/pdf?id=H1Xw62kRZ
Code: None
论文简述: 程序合成的任务是自动生成符合规范的程序。本文呢在监督模型上执行强化学习,目标是显式地最大化生成语义正确的程序的可能性。然后我们引入了一个训练过程,它可以直接最大化生成满足规范的语法正确的程序的概率。
TILE: Syntax-Directed Variational Autoencoder for Structured Data.
Author: Hanjun Dai, Yingtao Tian, Bo Dai, Steven Skiena, Le Song.
Paper:https://openreview.net/pdf?id=SyqShMZRb
Code: None
论文简述: 如何生成语法上和语义上都正确的数据在很大程度上是尚未解决的问题。在编译器理论的启发下,通过引入随机惰性属性,提出了一种新的语法导向变分自动编码器(SD-VAE)。该方法将离线的SDT检测转化为实时生成的指导,用于约束解码器。

TILE: Emergent Translation in Multi-Agent Communication.
Author: Jason Lee, Kyunghyun Cho, Jason Weston, Douwe Kiela.
Paper:https://openreview.net/pdf?id=H1vEXaxA-
Code: None
论文简述: 本文提出的翻译模型通过将源语言和目标语言置于一个共享的视觉模式(visual modality)中来实现这一点,并且在单词级和句子级的翻译任务中都优于几个基线。

TILE: Generating Wikipedia by Summarizing Long Sequences.
Author: Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, Noam Shazeer.
Paper:https://openreview.net/pdf?id=Hyg0vbWC-
Code: None
论文简述: 【文章生成】本文证明了生成英文维基百科文章可以看作是源文档的多文档摘要。本文使用提取摘要来粗略地识别突出信息,并使用神经抽象模型来生成文章。
Attention
更多自然语言处理相关知识,还请关注 AINLPer公众号,极品干货即刻送达。