1. pg_bulkload介绍
PostgreSQL提供了一个copy命令的便利数据加载工具,copy命令源于PostgreSQL数据库,copy命令支持文件与表之间的数据加载和表对文件的数据卸载。pg_bulkload是一种用于PostgreSQL的高速数据加载工具,相比copy命令。最大的优势就是速度。优势在让我们跳过shared buffer,wal buffer。直接写文件。pg_bulkload的direct模式就是这种思路来实现的,它还包含了数据恢复功能,即导入失败的话,需要恢复
2. pg_bulkload架构图
pg_bulkload主要包括两个模块:reader和writer。reader负责读取文件、解析tuple,writer负责把解析出的tuple写入输出源中。pg_bulkload最初的版本功能很简单,只是加载数据。3.1版本增加了数据过滤的功能。
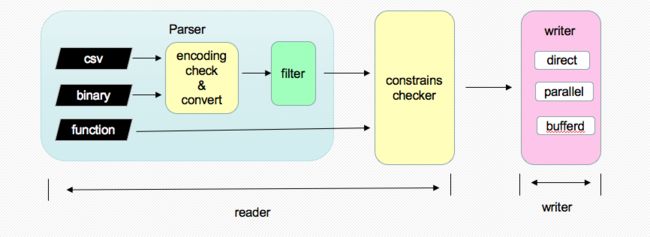
pg_bulkload.png
3. pg_bulkload安装
该工具不是PostgreSQL系统自带;需要下载安装;
[root@Postgres201 ~]# unzip pg_bulkload-VERSION3_1_10.zip
[root@Postgres201 ~]# cd pg_bulkload-VERSION3_1_10
[root@Postgres201 pg_bulkload-VERSION3_1_10]# make
[root@Postgres201 pg_bulkload-VERSION3_1_10]# make install
安装完成;要使用它需要建extension
[postgres@Postgres201 ~]$ psql lottu lottu
psql (9.6.0)
Type "help" for help.
lottu=# create extension pg_bulkload;
CREATE EXTENSION
4. pg_bulkload参数和控制文件
[postgres@Postgres201 ~]$ pg_bulkload --help
pg_bulkload is a bulk data loading tool for PostgreSQL
Usage:
Dataload: pg_bulkload [dataload options] control_file_path
Recovery: pg_bulkload -r [-D DATADIR]
Dataload options:
-i, --input=INPUT INPUT path or function
-O, --output=OUTPUT OUTPUT path or table
-l, --logfile=LOGFILE LOGFILE path
-P, --parse-badfile=* PARSE_BADFILE path
-u, --duplicate-badfile=* DUPLICATE_BADFILE path
-o, --option="key=val" additional option
Recovery options:
-r, --recovery execute recovery
-D, --pgdata=DATADIR database directory
Connection options:
-d, --dbname=DBNAME database to connect
-h, --host=HOSTNAME database server host or socket directory
-p, --port=PORT database server port
-U, --username=USERNAME user name to connect as
-w, --no-password never prompt for password
-W, --password force password prompt
Generic options:
-e, --echo echo queries
-E, --elevel=LEVEL set output message level
--help show this help, then exit
--version output version information, then exit
除了在命令行上指定参数外,还可以在控制文件中指定参数,下面介绍控制文件里的参数。
- TYPE=CSV|BINARY|FIXED|FUNCTION:输入数据的类型,默认是CSV。
CSV:从CSV格式的文本文件里加载数据。
BINARY|FIXED:从二进制文件里加载数据。
FUNCTION:从函数输出中加载数据。 - INPUT|INFILE=path|stdin|function_name: 数据源,必须指定,类型不同,它的值不一样
path:此处就是路径,可以是相对路径,pg服务器必须有读文件的权限
stdin:pg_bulkload将从标准输入读取数据。
SQL FUNCTION:指定SQL函数,用这个函数返回插入数据,可以是内建的函数,也可以是用户自定义的函数 - WRITER=DIRECT|PARALLEL|BUFFERED|BINARY:加载数据的方式,默认是DIRECT
DIRECT:直接把数据写入表中,绕过了共享内存并且不写日志,需要提供恢复函数。
BUFFERED:把数据写入共享内存,写日志,利用pg的恢复机制。
PARALLEL:并行处理模式,速度比DIRECT更快
BINARY:把输入数据转换成二进制数据,然后加载。 - OUTPUT|TABLE=table_name|outfile 输出源,即把数据导到哪里。
表:把数据导入到数据库的表里。
文件:指定文件的路径,把数据导入到文件里。 - LOGFILE=path 日志文件的路径 ,执行过程中会记录状态。
- MULTI_PROCESS=YES|NO 若设置了此值,会开启多线程模式,并行处理数据导入。若没设置,单线程模式,默认模式是单线程模式。
- SKIP|OFFSET=n 跳过的行数,默认是0,不能跟"TYPE=FUNCTION"同时设置。
- LIMIT|LOAD 限制加载的行数,默认是INFINITE,即加载所有数据,这个选项可以与"TYPE=FUNCTION"同时设置。
- ON_DUPLICATE_KEEP = NEW | OLD 对表存在唯一约束是保留最新的记录还是现有的记录
- PARSE_BADFILE = path 用来记录写入所有失败的记录。
- TRUNCATE = YES | NO 用来truncate目标表现有所有的记录。
- DELIMITER = delimiter_character 文件的分隔符
5. pg_bulkload的使用
创建测试表tbl_lottu和测试文件tbl_lottu_output.txt
[postgres@Postgres201 ~]$ psql lottu lottu
psql (9.6.0)
Type "help" for help.
lottu=# create table tbl_lottu(id int,name text);
CREATE TABLE
[postgres@Postgres201 ~]$ seq 100000| awk '{print $0"|lottu"}' > tbl_lottu_output.txt
- 不使用控制文件使用参数
[postgres@Postgres201 ~]$ pg_bulkload -i /home/postgres/tbl_lottu_output.txt -O tbl_lottu -l /home/postgres/tbl_lottu_output.log -P /home/postgres/tbl_lottu_bad.txt -o "TYPE=CSV" -o "DELIMITER=|" -d lottu -U lottu
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
100000 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
[postgres@Postgres201 ~]$ cat tbl_lottu_output.log
pg_bulkload 3.1.9 on 2018-07-12 13:37:18.326685+08
INPUT = /home/postgres/tbl_lottu_output.txt
PARSE_BADFILE = /home/postgres/tbl_lottu_bad.txt
LOGFILE = /home/postgres/tbl_lottu_output.log
LIMIT = INFINITE
PARSE_ERRORS = 0
CHECK_CONSTRAINTS = NO
TYPE = CSV
SKIP = 0
DELIMITER = |
QUOTE = "\""
ESCAPE = "\""
NULL =
OUTPUT = lottu.tbl_lottu
MULTI_PROCESS = NO
VERBOSE = NO
WRITER = DIRECT
DUPLICATE_BADFILE = /data/postgres/data/pg_bulkload/20180712133718_lottu_lottu_tbl_lottu.dup.csv
DUPLICATE_ERRORS = 0
ON_DUPLICATE_KEEP = NEW
TRUNCATE = NO
0 Rows skipped.
100000 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
Run began on 2018-07-12 13:37:18.326685+08
Run ended on 2018-07-12 13:37:18.594494+08
CPU 0.14s/0.07u sec elapsed 0.27 sec
- 导入之前先清理表数据
[postgres@Postgres201 ~]$ pg_bulkload -i /home/postgres/tbl_lottu_output.txt -O tbl_lottu -l /home/postgres/tbl_lottu_output.log -P /home/postgres/tbl_lottu_bad.txt -o "TYPE=CSV" -o "DELIMITER=|" -o "TRUNCATE=YES" -d lottu -U lottu
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
100000 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
[postgres@Postgres201 ~]$ psql lottu lottu -c "select count(1) from tbl_lottu;"
count
--------
100000
(1 row)
- 使用控制文件
新建控制文件lottu.ctl
INPUT = /home/postgres/lotu01
PARSE_BADFILE = /home/postgres/tbl_lottu_bad.txt
LOGFILE = /home/postgres/tbl_lottu_output.log
LIMIT = INFINITE
PARSE_ERRORS = 0
CHECK_CONSTRAINTS = NO
TYPE = CSV
SKIP = 5
DELIMITER = |
QUOTE = "\""
ESCAPE = "\""
OUTPUT = lottu.tbl_lottu
MULTI_PROCESS = NO
WRITER = DIRECT
DUPLICATE_BADFILE = /home/postgres/tbl_lottu.dup.csv
DUPLICATE_ERRORS = 0
ON_DUPLICATE_KEEP = NEW
TRUNCATE = YES
使用控制文件进行加载操作
pg_bulkload /home/postgres/lottu.ctl -d lottu -U lottu
[postgres@Postgres201 ~]$ pg_bulkload /home/postgres/lottu.ctl -d lottu -U lottu
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
5 Rows skipped.
95 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
6.总结
pg_bulkload是一种用于PostgreSQL的高速数据加载工具,相比copy命令。最大的优势就是速度。优势在让我们跳过shared buffer,wal buffer。直接写文件。pg_bulkload的direct模式就是这种思路来实现的。不足的是;表字段的顺序要跟导入的文件报错一致。希望后续版本能开发。