Python爬虫学习笔记_DAY_28_Python爬虫之scrapy框架的工作原理与安装使用介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.scrapy框架的工作原理介绍
II.scrapy框架的安装
III.用scrapy框架搭建并运行第一个项目
I.scrapy框架的工作原理介绍
首先介绍一下scrapy框架是什么:
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
简单的说,scrapy给我们提供了更加简便、高效的爬虫体验,但与此同时它的工作方式和代码与之前学习的urllib库、requests库完全不同,我们需要重新学习。
接下来介绍一下scrapy框架的工作原理:
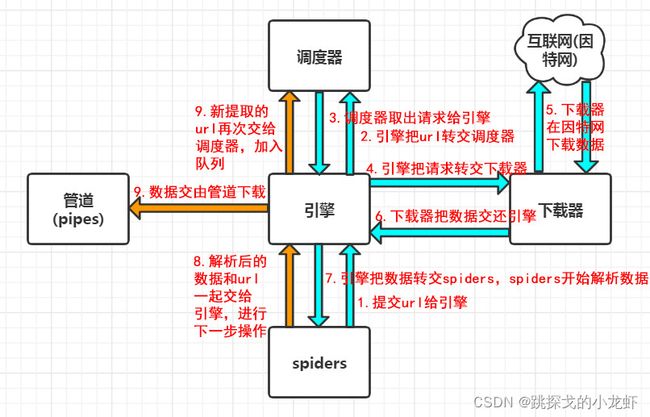
先上一张图,图上表示出了scrapy框架的几个组成部分:
1️⃣ spiders
spiders可以理解为代表了我们人的操作,我们在操作scrapy的时候,实际上就是以spiders的身份在操作,初始的url是我们定义的。
2️⃣ 引擎
引擎是scrapy框架的中枢,从图中可以看出,引擎与所有的其他组件交互,并且交互大多带有指令性的操作,可以理解成一个指挥官。
3️⃣ 调度器
调度器,顾名思义,它是用来做调度的,简单的说就是它会把所有请求的url放入一个队列中,每一次会从队列中取出一个url,这个过程叫做调度。
4️⃣ 下载器
下载器,是用来下载数据的,它下载的是原始数据,可以理解为网页源码,这些源数据通过引擎再次交给我们用户spiders做进一步解析处理。(下载器沟通因特网,数据来源也是因特网)
5️⃣ 管道
管道的工作是下载图片、文件,它的工作与调度器下载源数据不同,它下载的是经过解析后的具体的图片、文件等数据。
最后描述一段scrapy框架的工作过程:
首先,spiders想要在某个url对应的网页下下载图片,于是spiders向引擎递交url,之后引擎把url放入调度器排队;当这个url排到队首的时候,调度器取出这个url请求,交给引擎;这时候引擎把请求给下载器,下载器访问因特网,拿到源数据,交给引擎;引擎再把源数据给spiders。经过这一波操作,源数据被spiders拿到。之后spiders解析数据,并把里面的url和需要下载的数据分离,并一起交给引擎,引擎把url和需下载的数据分别交给调度器和管道,调度器继续重复上述操作,管道下载文件。
II.scrapy框架的安装
工作过程描述后,我们开始安装scrapy框架:
1️⃣ 首先进入pycharm,选择 File - - - > Settings:
之后选择 project - - - > Python Interpreter:
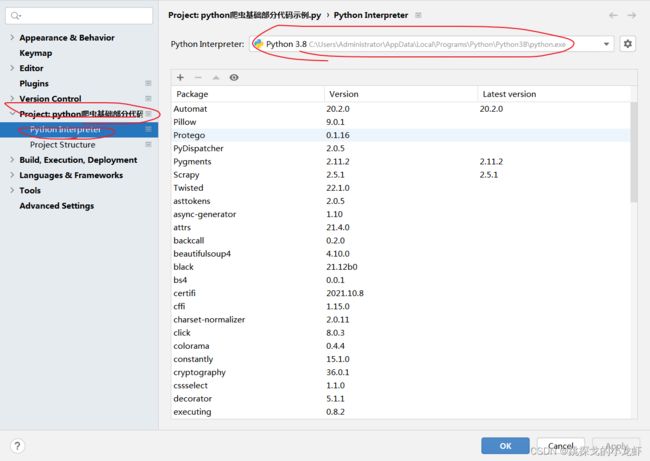
我们于是知道了python的安装目录。
2️⃣ 进入Python的安装目录:
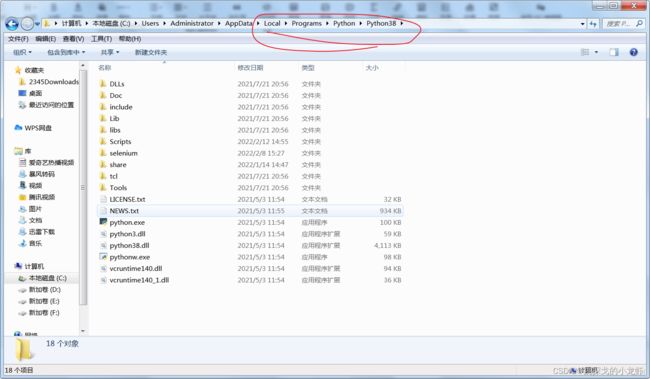
按Win + R,输入cmd打开终端:

之后输入cd,留一个空格,之后把python安装目录下的Scripts文件夹拖入,生成路径,并回车确认:
3️⃣ 输入安装指令,安装scrapy框架:
pip install scrapy -i https://pypi.douban.com/simple
III.用scrapy框架搭建并运行第一个项目
安装完成之后,我们开始用scrapy框架搭建第一个项目,要注意的是scrapy框架创建项目不同于平时用pycharm创建项目,它的操作不在pycharm中,而是在终端:
1️⃣ 首先,我们自己选择一个位置,新建一个空的文件夹,命名随意,这里我们创建一个名为scrapy-project的文件夹。
2️⃣ 之后,打开终端,用cd指令进入我们刚才新建的文件夹,方法还是把文件夹拖入cd后光标,自动生成路径:
3️⃣ 输入下面的指令,用scrapy框架生成一个新的项目:
scrapy startproject 项目名称名称任意取,我们这里起名为scrapy_demo1.
4️⃣ 到这里,还差一小步:新建spiders爬虫文件:
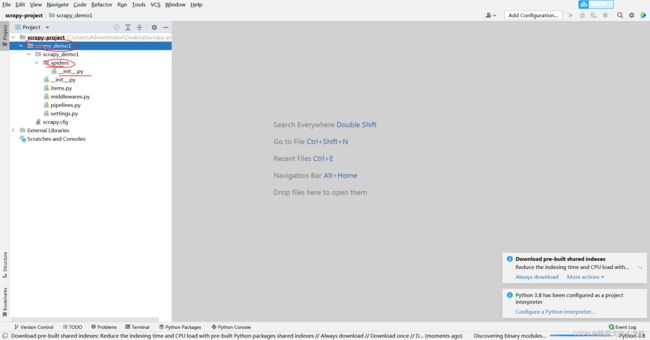
上图是我们打开项目文件后在pycharm中看到的结构,上面的结构中,spiders文件夹下,初始只有一个__init__文件,还差一个核心的爬虫文件,这个文件也需要指令生成,但在生成之前,我们需要先用指令进入spiders文件夹,这个文件夹的进入指令是这样的:
cd 项目名称/项目名称/spiders
我们需要cd后 两次输入项目名称中间用一个/隔开,最后加一个/spiders。
终端进入spiders文件夹后,输入下面的指令,生成爬虫文件:
scrapy genspider 爬虫文件的文件名 某个目的url文件名我们任意取,某个目的url我们这里可以用https://www.baidu.com来做演示,名称这里取的是scrapy_baidu。(注意爬虫文件名不能和项目名称一致)。于是我们生成了一个爬虫文件:
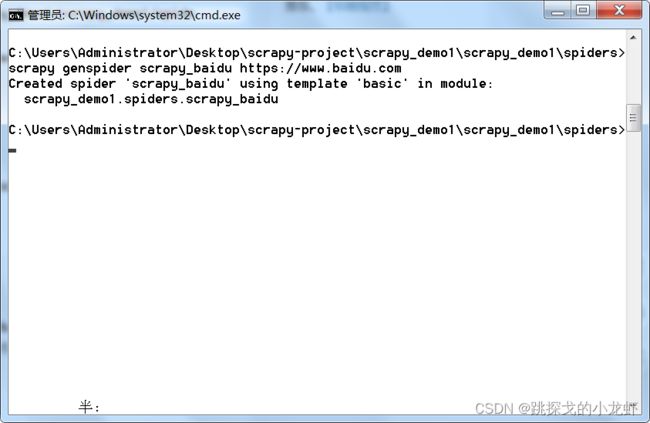
此时我们再次打开pycharm,可以看到这个文件:
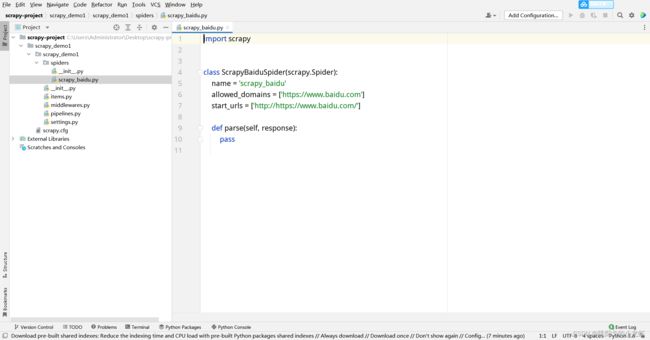
这时候,我们发现里面有一个start_urls和一个allowed_domains,本期篇幅有限,这部分先不介绍,但是我们按照常理思考,start_urls里多了一个http://,我们把http://删去,后面的部分是我们需要的url。
之后,我们打开settings文件,注释掉下面这句话:ROBOTSTXT_OBEY:
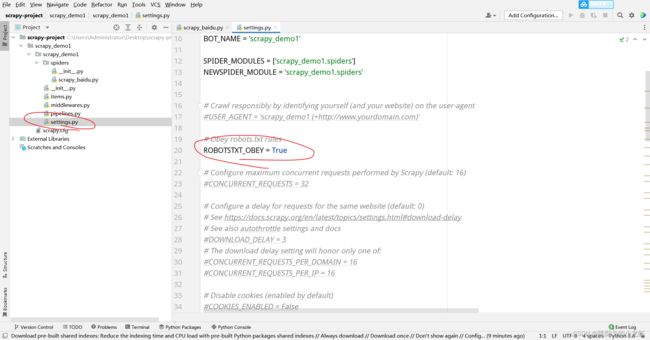
注释的原因本次也不做解释,注释之后,我们可以开始准备运行第一个项目了:
我们再次打开新建的爬虫文件:scrapy_baidu.py,注释掉parse函数下的pass,加上一句print代码,例如这里print一句'hello,scrapy'
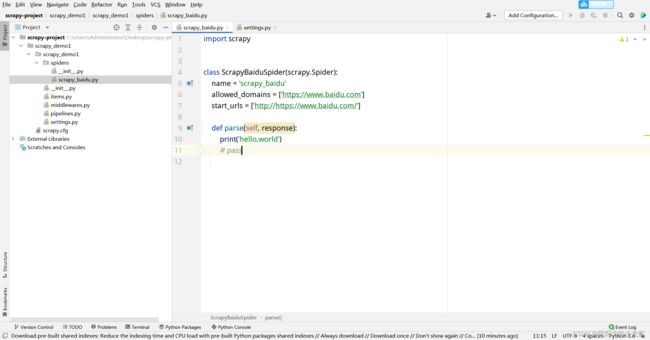
最后,我们来运行第一个项目:运行的方式不是点击pycharm的运行按钮,而是在终端输入这句指令:
scrapy crawl scrapy_baidu
最后一个参数是我们的爬虫文件文件名,如果起名不同,需要修改这句指令!
以下是运行结果:
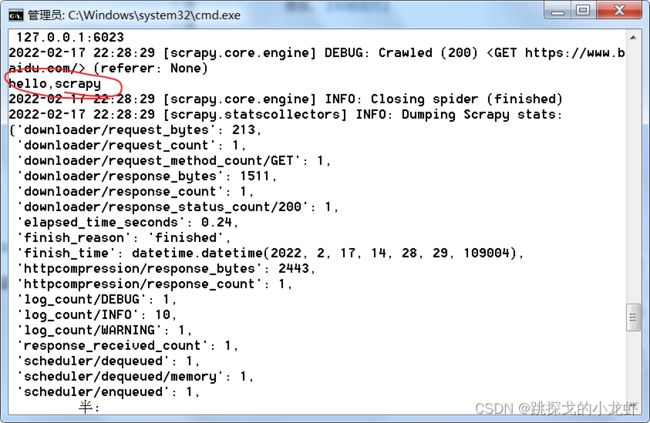
到这里,第一个scrapy项目运行成功!