Python爬虫学习笔记_DAY_26_Python爬虫之requests库的安装与基本使用【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.requests库的介绍与安装
II.requests库的基本语法
III.requests库的GET请求
IV.requests库的POST请求
IV.requests库的代理ip方法
V.小结
I.requests库的介绍与安装
首先,了解一下什么是requests库:
它是一个Python第三方库,处理URL资源特别方便,可以完全取代之前学习的urllib库,并且更加精简代码量(相较于urllib库)。
那么话不多说,我们安装一下:
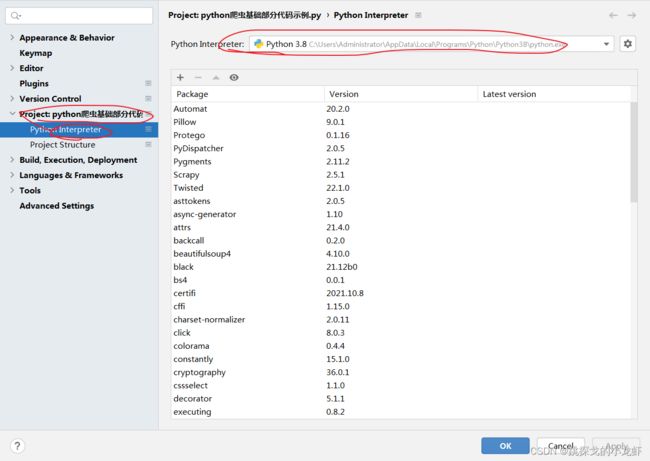
1️⃣ 首先,我们依旧是打开pycharm,查看一下自己的python解释器的安装位置:File - - - > Settings - - - > Project - - - > Python Interpreter
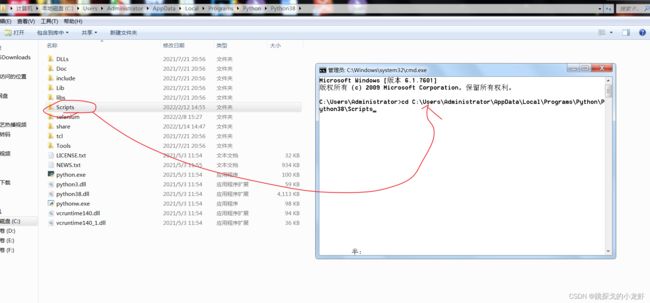
2️⃣ 进入python解释器安装目录下,打开终端: Win + R,输入cmd ,回车,之后输入指令 cd,把Scripts文件夹拖入cd后的光标中并执行切换:
3️⃣ 输入安装指令并执行:
pip install requests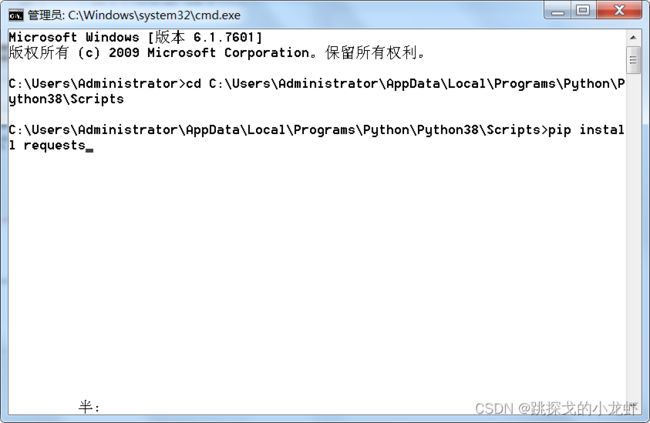
II.requests库的基本语法
接下来,介绍requests的基本语法,与urllib库类似,requests库的语法大致分为一种类型与六种属性:
首先回忆一下urllib库,在urllib库中,我们通过测试发现,它获取的服务器响应是HTTPResponse的类型,而requests库获取的服务器响应是requests.models.Response的类型。
然后我们用requests库模拟浏览器,向服务器发起一次普通的请求,这次请求只是为了辅助下面的六种属性:
import requests
url = 'http://www.baidu.com'
response = requests.get(url = url)用requests库时,我们发起请求是通过requests.get()函数进行的,传参是目的网页的url(后续会有其他的传参,暂时此处传入一个url),并且用response变量接受服务器的响应。
接下来是requests库的六种属性:
1️⃣ text属性:字符串形式返回网页源码(由于此时编码格式是gbk,中文部分可能会乱码,稍后解决)
# (1) text属性:以字符串形式返回网页源码
print(response.text) # 由于没有设置编码格式,中文会乱码2️⃣ encoding属性:设置相应的编码格式
# (2) encoding属性:设置相应的编码格式:
response.encoding = 'utf-8'这之后的response就不会出现中文乱码现象了。
3️⃣ url属性:返回url地址
# (3) url属性:返回url地址
url = response.url4️⃣ content属性:返回二进制的数据
# (4) content属性:返回二进制的数据
content_binary = response.content5️⃣ status_code属性:返回状态码 200是正常
# (5) status_code属性:返回状态码 200是正常
status_code = response.status_code6️⃣ headers属性:返回响应头
# (6) headers属性:返回响应头
headers = response.headersIII.requests库的GET请求
requests库的get请求的示例代码如下:
import requests
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'wd' : '跳探戈的小龙虾'
}
# 三个参数:
# url:请求路径
# params:请求参数
# kwargs:字典
# 不需要请求对象的定制
# 参数使用params进行传递
# 参数无需编码
# 同时不需要请求对象定制
# 请求路径的?字符可以加也可以省略
response = requests.get(url = url,params = data,headers = headers)
response.encoding = 'utf-8'
content = response.text
print(content)从上面可以看出来,requests最省代码的地方在于,它不需要进行请求对象的定制,如果换成urllib库,我们需要先封装一个request请求对象,而后把这个对象传入urllib.request.urlopen()函数中,而在requests库中,我们只需要把三个参数,即url、data和headers传入,即可完成get请求,十分方便!(上面的代码执行的是在百度中搜索‘跳探戈的小龙虾’返回的网页源码)
IV.requests库的POST请求
接下来是requests库的post请求:
# requests_post请求
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'kw' : 'eye'
}
# 四个参数:
# url:请求路径
# data:请求参数
# json数据
# kwargs:字典
response = requests.post(url = url,data = data,headers = headers)
content = response.text
import json
obj = json.loads(content.encode('utf-8'))
print(obj)如果说get请求requests库只比urllib库简单一点点的话,那么post请求绝对是requests库更加便捷,它不仅省去的请求对象的定制,而且省略了参数的编码和转码的操作,可以说非常方便,只需要和get请求一样把三个参数url、data和headers传入即可,因此post请求个人强烈推荐用requests库代替urllib库。
IV.requests库的代理ip方法
最后介绍一下requests使用代理ip的方式,它又简化了urllib库,回忆urllib库代理ip,我们需要创建handler处理器,还要定义opener对象,但requests库中,我们只需要把代理ip作为一个普通的参数,传入requests.get()/requests.post()函数即可(简直太方便了!)
# requests_ip代理
import requests
url = 'http://www.baidu.com/s'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'wd' : 'ip'
}
proxy = {
'http:' : '218.14.108.53'
}
response = requests.get(url = url, params = data,headers = headers,proxies = proxy)
content = response.textV.小结
最后,简单总结一下requests库,首先对于requests库,不再是六种方法,而是有六个属性;其次是对于get请求和post请求,requests库都不再需要请求对象的定制,而且post请求不再需要编解码操作;最后对于ip代理,不需要定义一些中间对象,直接传入代理ip,作为一个普通参数即可。同时,我们的requests.get()/requests.post()函数,能够传入四个参数:url、data、headers、ip代理。