数学建模之层次分析法(AHP)
文章目录
-
- 1 问题的提出
-
-
- 1.1.问题的提出
- 1.2.应用场景
-
- 2.层次分析法步骤
-
-
- 2.1.建立系统递阶层次结构
- 2.2.对准则层和方案层构造判断矩阵
- 2.3.一致性检验
- 2.4.一致矩阵权重计算
- 2.5.根据权重矩阵计算得分,进行方案优劣排序
-
- 3.层次分析法的推广
- 4.层次分析法的局限性
- 附录:层次分析法代码
1 问题的提出
1.1.问题的提出
日常生活中有很多的决策问题。决策是指在面临多种方案时需要依据一定的标准选择某一种方案。日常生活中有许多决策的问题。比如:
买钢笔,一般要依据质量、颜色、实用性、价格、外形等方面的因素选择某一支钢笔。
假期旅游,是去风光秀丽的苏州,还是去迷人的北戴河,或者是去山水甲天下的桂林,那一般会依据景色、费用、食宿条件、旅途等因素来算着去哪个地方。
面临各种各样的方案,要进行比较、判断、评价、直至最后的决策。这个过程中都是一些主观的因素,这些因素可能由于个人情况的不同,有相应不同的比重,所以这样主观因素给数学方法的解决带来了很多的不便。
评价、决策类问题:
1.2.应用场景
- 我们评价的 目标 是什么?
- 为了达到这个目标有几种可选方案?
- 评价得准则或者指标是什么?
指标选择:根据背景材料、常识以及网上收集的资料进行结合筛选。
2.层次分析法步骤
我们以选择旅游地为例,来解释层次分析法的步骤
问题:小明同学想出去旅游。在查阅了网上的攻略后,他初步选择了苏杭、北戴河和桂林三地之一作为目标景点。
请你确定评价指标、形成评价体系来为小明同学选择最佳的方案。
指标确定:假如我们查询了资料后选择了以下五个指标:
①景点景色
②旅游花费
③居住环境
④饮食情况
⑤交通便利程度
2.1.建立系统递阶层次结构

2.2.对准则层和方案层构造判断矩阵
我们采取分而治之的思想,将两两指标进行比较,最终根据两两比较结果来推算出权重。
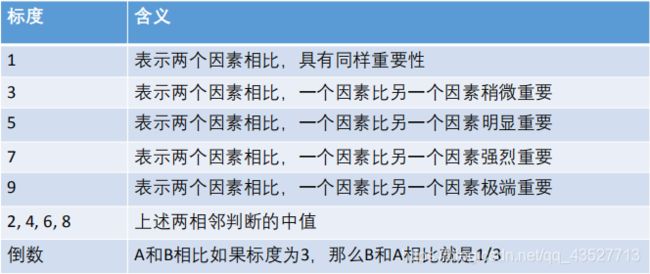
注:重要性可以理解为满意度
根据重要性我们可以的到两两指标之间的重要性比值
我们可以得到准则层的判断矩阵:
上述方阵有以下特点:
- a i j a_{ij} aij表示 i i i对指标 j j j的重要程度。
- 当 i = j i=j i=j两指标标度为1
- 正互反矩阵 : a i j > 0 且 a i j × a j i = 1 a_{ij}>0且a_{ij}×a_{ji}=1 aij>0且aij×aji=1
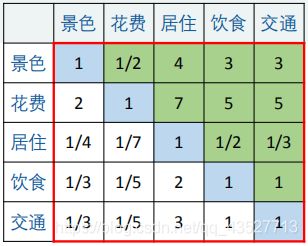
准则层—方案层的判断矩阵的数值要结合实际来填写,如果题目中有其他数据,可以考虑利用这些数据进行计算。
不同地区同一指标的计算方法也与上类似:
我们可以得到不同方案对于同一指标的判断矩阵。
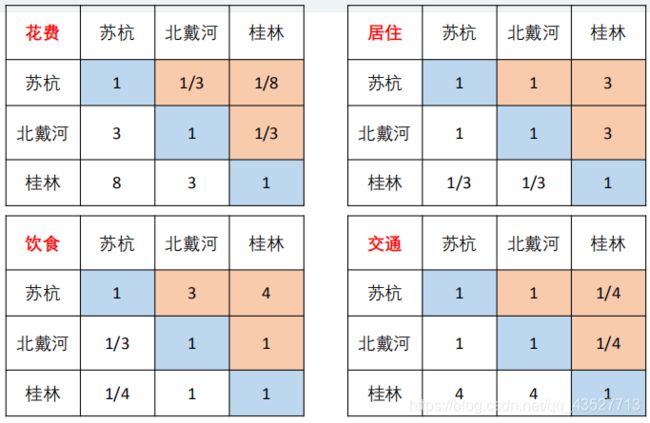
2.3.一致性检验
但是,对于上面得到的矩阵,可能会出现不一致现象,例如:
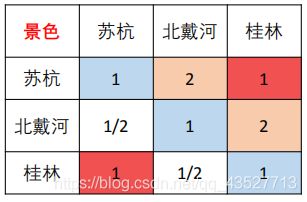
在上图中,苏杭>北戴河,北戴河>桂林,但是又苏杭=桂林,出现了不一致矛盾。
因此,我们需要判断一致性。
一致矩阵判定方法:
充要条件:正互反矩阵满足 a i k = a i j × a j k a_{ik}=a_{ij}×a_{jk} aik=aij×ajk
一般判定条件:各行(各列)之间呈倍数关系。
当然,如果不是一致性矩阵,满足一致性检验条件时候,也是可以用的。
下面我们介绍一致性检验:
线代知识回顾:
引理:若A为n阶方阵,且 r ( A ) = 1 r(A)=1 r(A)=1则A有一个特征值为 t r ( A ) tr(A) tr(A),其余特征值为0.
结论:一致性矩阵有一个特征值为 n n n,其余全为 0 0 0.
特征值为 n n n时,对应的特征向量刚好为 k [ 1 a 11 , 1 a 12 , … , 1 a 1 n ] T ( k ≠ ) k[\frac{1}{a_{11}},\frac{1}{a_{12}},…,\frac{1}{a_{1n}}]^T(k\neq) k[a111,a121,…,a1n1]T(k=)
引理: n n n阶正互反矩阵 A A A为一致矩阵时当且仅当 λ m a x = n λ_{max}=n λmax=n;且当非一致时, λ m a x > n λ_{max}>n λmax>n,越不一致,相差越大。
一致性检验步骤:
- 计算一致性指标: C I = λ m a x − n n − 1 CI=\frac{{λ_{max}-n}}{n-1} CI=n−1λmax−n
- 查找对应得到平均随机一致性指标 RI

- 计算一致性比例 CR
C R = C I R I CR=\frac{CI}{RI} CR=RICI
若 C R < 0.1 CR<0.1 CR<0.1,则一致性可以接受,否则修正判断矩阵。
CR>1如何修正?
尽量调到各行成倍数关系
2.4.一致矩阵权重计算
1.绝对一致矩阵:(满足各行各列倍数关系)

权重为第一列的归一化处理:

2.满足一致性的矩阵(但不绝对一致)
我们有三种方法计算权重:
方法一:算数平均法
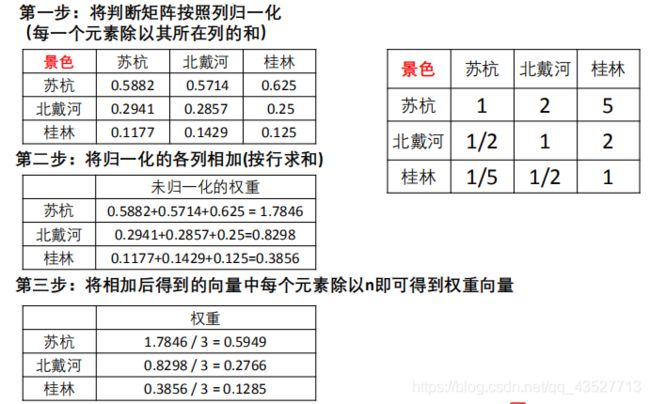 方法二:几何平均法
方法二:几何平均法
第一步:将A的元素按照行相乘得到一个新的列向量
第二步:将新的向量的每个分量开n次方
第三步:对该列向量进行归一化即可得到权重向量
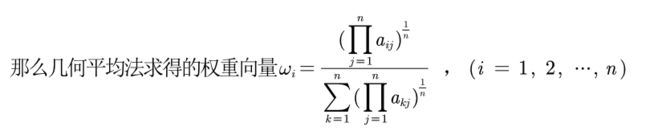
方法三:特征值法
假如我们的判断矩阵一致性可以接受,那么我们可以仿照一致矩阵权重的求法。
第一步:求出矩阵A的最大特征值以及其对应的特征向量
第二步:对求出的特征向量进行归一化即可得到我们的权重
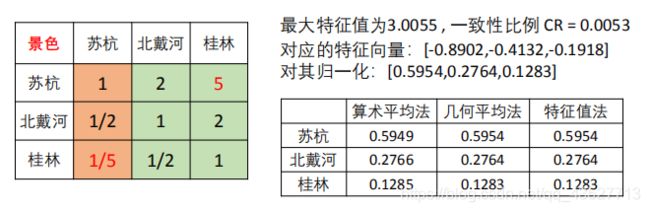
一般来说,我们用特征值法求出的权重来作为最后的结果,当然,我们强烈建议将三种方法的权值都计算出来,进行比较分析。避免单一方法偏差
2.5.根据权重矩阵计算得分,进行方案优劣排序
最后求出来的权重矩阵如下:
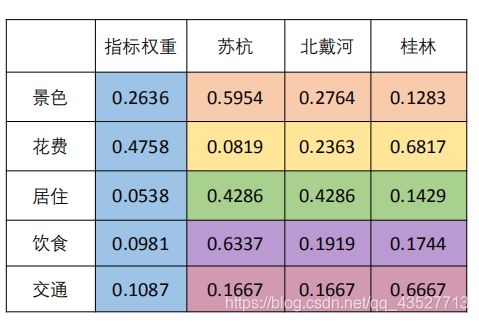
最后用指标权重和对应方案权重相乘在求和便得到该方案的得分,例如:苏杭得分
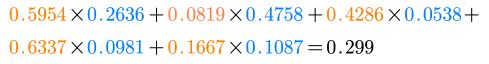
类似我们得到北戴河0.245分,桂林0.455分,因此我们选择最佳方案:桂林
3.层次分析法的推广
当有些指标在不同方案之间并不是公用的,那我们只需要将该方案相对于该指标的权值设为0,即可用层次分析法继续求解。
4.层次分析法的局限性
1.决策层不能太多,一般 n < 15 n<15 n<15
2.如果决策层指标得到数据已知,可以利用Topsis方法使评价更准确。
附录:层次分析法代码
%% 注意:在论文写作中,应该先对判断矩阵进行一致性检验,然后再计算权重,因为只有判断矩阵通过了一致性检验,其权重才是有意义的。
%% 在下面的代码中,我们先计算了权重,然后再进行了一致性检验,这是为了顺应计算过程,事实上在逻辑上是说不过去的。
%% 因此大家自己写论文中如果用到了层次分析法,一定要先对判断矩阵进行一致性检验。
%% 而且要说明的是,只有非一致矩阵的判断矩阵才需要进行一致性检验。
%% 如果你的判断矩阵本身就是一个一致矩阵,那么就没有必要进行一致性检验。
%% 输入判断矩阵
clear;clc
disp('请输入判断矩阵A: ')
% A = input('判断矩阵A=')
A =[1 1 4 1/3 3;
1 1 4 1/3 3;
1/4 1/4 1 1/3 1/2;
3 3 3 1 3;
1/3 1/3 2 1/3 1]
% matlab矩阵有两种写法,可以直接写到一行:
% [1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1]
% 也可以写成多行:
[1 1 4 1/3 3;
1 1 4 1/3 3;
1/4 1/4 1 1/3 1/2;
3 3 3 1 3;
1/3 1/3 2 1/3 1]
% 两行之间以分号结尾(最后一行的分号可加可不加),同行元素之间以空格(或者逗号)分开。
%% 方法1:算术平均法求权重
% 第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)
Sum_A = sum(A)
[n,n] = size(A) % 也可以写成n = size(A,1)
% 因为我们的判断矩阵A是一个方阵,所以这里的r和c相同,我们可以就用同一个字母n表示
SUM_A = repmat(Sum_A,n,1) %repeat matrix的缩写
% 另外一种替代的方法如下:
SUM_A = [];
for i = 1:n %循环哦,这一行后面不能加冒号(和Python不同),这里表示循环n次
SUM_A = [SUM_A; Sum_A]
end
clc;A
SUM_A
Stand_A = A ./ SUM_A
% 这里我们直接将两个矩阵对应的元素相除即可
% 第二步:将归一化的各列相加(按行求和)
sum(Stand_A,2)
% 第三步:将相加后得到的向量中每个元素除以n即可得到权重向量
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2) / n)
% 首先对标准化后的矩阵按照行求和,得到一个列向量
% 然后再将这个列向量的每个元素同时除以n即可(注意这里也可以用./哦)
%% 方法2:几何平均法求权重
% 第一步:将A的元素按照行相乘得到一个新的列向量
clc;A
Prduct_A = prod(A,2)
% prod函数和sum函数类似,一个用于乘,一个用于加 dim = 2 维度是行
% 第二步:将新的向量的每个分量开n次方
Prduct_n_A = Prduct_A .^ (1/n)
% 这里对每个元素进行乘方操作,因此要加.号哦。 ^符号表示乘方哦 这里是开n次方,所以我们等价求1/n次方
% 第三步:对该列向量进行归一化即可得到权重向量
% 将这个列向量中的每一个元素除以这一个向量的和即可
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
%% 方法3:特征值法求权重
% 第一步:求出矩阵A的最大特征值以及其对应的特征向量
clc
[V,D] = eig(A) %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0)
Max_eig = max(max(D)) %也可以写成max(D(:))哦~
% 那么怎么找到最大特征值所在的位置了? 需要用到find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。
% 那么问题来了,我们要得到最大特征值的位置,就需要将包含所有特征值的这个对角矩阵D中,不等于最大特征值的位置全变为0
% 这时候可以用到矩阵与常数的大小判断运算
D == Max_eig
[r,c] = find(D == Max_eig , 1)
% 找到D中第一个与最大特征值相等的元素的位置,记录它的行和列。
% 第二步:对求出的特征向量进行归一化即可得到我们的权重
V(:,c)
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% 我们先根据上面找到的最大特征值的列数c找到对应的特征向量,然后再进行标准化。
%% 计算一致性比例CR
clc
CI = (Max_eig - n) / (n-1);
RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR < 0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end