Hadoop HA 原理概述:
原理概述部分参考自:https://www.cnblogs.com/qingyunzong/p/8634335.html
为什么会有 hadoop HA 机制呢?
HA:High Available,高可用,在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SPOF:A Single Point ofFailure)。 对于只 有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件升级),那么整个集群将无法使用,直到 NameNode 重新启动
那如何解决呢?
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点, 确保 NameNodes中只有一个处于 Active 状态,其他的处在 Standby 状态。其中 ActiveNameNode负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一 旦 ActiveNameNode 出现问题能够快速切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,ActiveNamenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一 致,如此这般,在紧急情况下 standby便可快速切为 active namenode。为了实现快速切换, Standby节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需 要配置 NameNodes的位置,并同时给他们发送文件块信息以及心跳检测。

HA版Hadoop集群搭建
会应用到上一篇文章的内容:https://www.jianshu.com/p/bf76dfedef2f
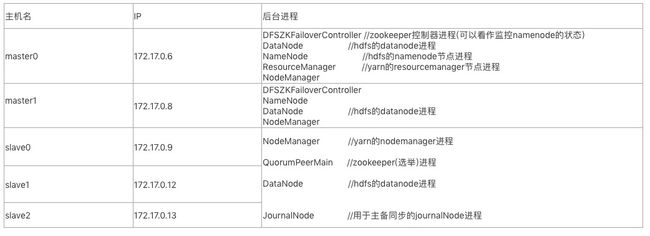
1.集群规划:
2.创建容器:
使用上一章(https://www.jianshu.com/p/bf76dfedef2f)中的镜像 centos6_hadoop创建容器
docker run -it -h --name hadoop_ha centos6_hadoop:2.8.2
3. 配置hadoop
core-site.xml 配置
hdfs-site.xml配置
yarn-site.xml配置
mapred-site.xml配置
at. If "local", then jobs are run in-process as a single map
and reduce task.
4.修改slaves文件
增加
master0
master1
slave0
slave1
slave2
5.保存镜像
docker commit hadoop_ha centos6_ha_hadoop:latest
6.对应规划创建五个容器(使用上面保存的镜像创建)
docker run -it -h master0 -p 50070:50070 -p 8088:8088 --name master0 centos6_ha_hadoop:latest
docker run -it -h master1 -p 50071:50070 -p 8089:8088 --name master1 centos6_ha_hadoop:latest
docker run -it -h slave0 -p 50070 -p 8088 --name slave0 centos6_ha_hadoop:latest
docker run -it -h slave1 -p 50070 -p 8088 --name slave1 centos6_ha_hadoop:latest
docker run -it -h slave2 -p 50070 -p 8088 --name slave2 centos6_ha_hadoop:latest
已经对应着我们的规划图创建好了五个容器
7.配置/etc/hosts文件
在每个容器中执行ifconfig查看ip
我的ip对应关系是:
172.17.0.6 master0
172.17.0.8 master1
172.17.0.9 slave0
172.17.0.12 slave1
172.17.0.13 slave2
在/etc/hosts文件中增加上述内容
8.在每个容器中执行 source /etc/profile
这样做的原因是 使用Docker commit 提交的镜像导致使用这个镜像创建容器时配置文件不生效。
9.配置免登陆
在master0和master1两个容器上分别执行如下命令:
cd ~/
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
10.Zookeeper下载安装(本小结配置均在 slave0,slave1,slave2)
在slave0,slave1,slave2三个容器中下载Zookeeper解压到 /usr.local目录下
配置环境变量:vim /etc/profile(配置好别忘记source)

修改zookeeper配置:
cd $ZK_HOME/conf
vim zoo.cfg
修改:dataDir=/usr/local/hadoop-2.8.2/zk_temp
在文件尾添加:
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
保存好配置后在上面配置的dataDir目录下创建myid文件:
touch dataDir/myid
在slave0容器中:
echo 1 > myid
在slave1容器中:
echo 2 > myid
在slave2容器中:
echo 3 > myid
启 动
1.在slave0,slave1,slave2上执行命令启动journalnode:hadoop-daemon.sh start journalnode
2.在master0上执行:hdfs namenode -format
3.在master0上执行:hadoop-daemon.sh start namenode
4.在master1上执行:hdfs namenode -bootstrapStandby
5.在slave0,slave1,slave2上执行:zkServer.sh start(启动zookeeper)
可以使用 zkServer.sh查看哪个是leader哪个是follower
6.只在master0上格式化ZKFC即可:hdfs zkfc -formatZK
7.最后在master0上执行
start-dfs.sh --启动分布式文件系统
start-yarn.sh --启动分布式计算
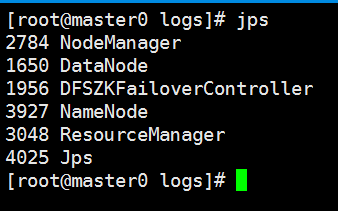
启动后各节点上的jps信息如下:
master0节点jps下进程:
2176 NodeManager //yarn的nodemanager进程
1539 NameNode //hdfs的namenode节点进程
1650 DataNode //hdfs的datanode进程
1956 DFSZKFailoverController //zookeeper控制器进程(可以看作监控namenode的状态)
3048ResourceManager //yarn的resourcemanager节点进程
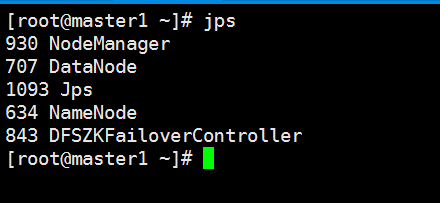
master1节点的jps下进程:
slave0,slave1,slave2jps下进程:
219 QuorumPeerMain //zookeeper(选举)进程
605 JournalNode //用于主备同步的journalNode进程

验证集群高可用性
首先向hdfs上传一个文件
hadoop fs -put /etc/hosts /
hadoop fs -ls /
kill -9 id(杀掉Active状态的namenode)
hadoop fs -ls / //仍然看到上传的hosts文件