《深度学习入门:基于Python的理论与实现》读书笔记:第8章 深度学习
目录
8.1 加深网络
8.1.1 向更深的网络出发
8.1.2 进一步提高识别精度
8.1.3 加深层的动机
8.2 深度学习的小历史
8.2.1 ImageNet
8.2.2 VGG
8.2.3 GoogleNet
8.2.4 ResNet
8.3 深度学习的高速化
8.3.1 需要努力解决的问题
8.3.2 基于GPU的高速化
8.3.3 分布式学习
8.3.4 运算精度的位数缩减
8.4 深度学习的应用案例
8.4.1 物体检测
8.4.2 图像分割
8.4.3 图像标题的生成
8.5 深度学习的未来
8.5.1 图像风格变换
8.5.2 图像的生成
8.5.3 自动驾驶
8.5.4 Deep Q-Network(强化学习)
8.6 小结
8.1 加深网络
8.1.1 向更深的网络出发

这个网络使用He初始值作为权重的初始值,使用Adam更新权重参数,具有如下特点:
1.基于3x3的小型滤波器的卷积层;
2.激活函数是ReLU;
3.全连接层的后面使用Dropout层;
4.基于Adam的最优化;
5.使用He初始值作为权重初始值。
import sys, os
sys.path.append(os.pardir) # 为了导入父目录而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from deep_convnet import DeepConvNet
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr':0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!") 这次的深度CNN尽管识别精度很高,但是对于某些图像,也犯了和人类同样的“识别错误”。从这一点上,我们也可以感受到深度CNN中蕴藏着巨大的可能性。
这次的深度CNN尽管识别精度很高,但是对于某些图像,也犯了和人类同样的“识别错误”。从这一点上,我们也可以感受到深度CNN中蕴藏着巨大的可能性。
8.1.2 进一步提高识别精度
 对于MNIST数据集,层不用特别深就获得了(目前)最高的识别精度。一般认为,这是因为对于手写数字识别这样一个比较简单的任务,没有必要将网络的表现力提高到那么高的程度。因此,可以说加深层的好处并不大。而之后要介绍的大规模的一般物体识别的情况,因为问题复杂,所以加深层对提高识别精度大有裨益。
对于MNIST数据集,层不用特别深就获得了(目前)最高的识别精度。一般认为,这是因为对于手写数字识别这样一个比较简单的任务,没有必要将网络的表现力提高到那么高的程度。因此,可以说加深层的好处并不大。而之后要介绍的大规模的一般物体识别的情况,因为问题复杂,所以加深层对提高识别精度大有裨益。
Data Augmentation(数据扩充)基于算法“人为地”扩充输入图像(训练图像),对于输入图像,通过施加旋转、垂直和水平方向上的移动等微小变化,增加图像的数量,这在数据集的图像数量有限时尤其有效。
8.1.3 加深层的动机
 加深层的一个好处就是可以减少网络的参数数量。说得详细一点,就是与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。
加深层的一个好处就是可以减少网络的参数数量。说得详细一点,就是与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。
 叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(给神经元施加变化的某个局部空间区域 )。并且,通过叠加层,将ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(给神经元施加变化的某个局部空间区域 )。并且,通过叠加层,将ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
加深层的另一个好处就是使学习更加高效,与没有加深层的网络相比,通过加深层,可以减少学习数据,从而高效地进行学习。通过加深网络,就可以分层次地分解需要学习的问题,因此,各层需要学习的问题就变成了更简单的问题。通过加深层,可以分层次地传递信息,提取了边缘的层的下一层能够使用边缘的信息,所以应该能够高效地学习更加高级的模式。
8.2 深度学习的小历史
8.2.1 ImageNet

 8.2.2 VGG
8.2.2 VGG
VGG是由卷积层和池化层构成的基础的CNN,它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。VGG中需要注意的地方是,基于3x3的小型滤波器的卷积层的运算是连续进行的。虽然VGG在性能上不及GoogleNet,但因为VGG结构简单,应用性强,所以很多技术人员都喜欢使用基于VGG的网络。
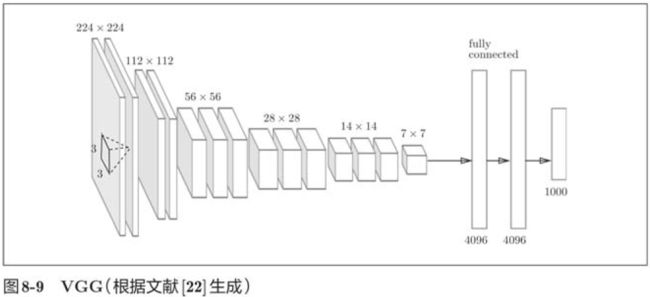
VGG重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理,最后经由全连接层输出结果。
8.2.3 GoogleNet

GoogleNet的特征是,网络不仅在纵向上有深度,在横向上也有深度(广度) 。GoogleNet在横向上有“宽度”,这称为“Inception结构”。

Inception结构使用了多个大小不同的滤波器(和池化) ,最后再合并它们的结果。GoogleNet的特征就是将这个Inception结构用作一个构建(构成元素)。
8.2.4 ResNet
ResNet的特征在于具有比以前的网络更深的结构。在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。ResNet中,为了解决这类问题,导入了“快捷结构”(也称为“捷径”或“小路”)。导入这个快捷结构后,就可以随着层的加深而不断提高性能了(当然,层的加深也是有限度的)。

在连续2层的卷积层中,将输入x跳着连接至2层后的输出,通过快捷结构,原来的2层卷积层的输出F(x)变成了F(x)+ x。通过引入这种快捷结构,即使加深层,也能高效地学习,反向传播时信号可以无衰减地传递。
因为快捷结构只是原封不动地传递输入数据,所以反向传播时会将来自上游的梯度原封不动地传向下游。这里的重点是不对来自上游的梯度的进行任何处理,将其原封不动地传向下游。因此,基于快捷结构,不用担心梯度会变小(或变大),能够向前一层传递“有意义的梯度”。通过这个快捷结构,之前因为加深层而导致的梯度变小的梯度消失问题就有望得到缓解。
 实践中经常会灵活应用使用ImageNet这个巨大的数据集学习到的权重数据,这称为迁移学习,将学习完的权重(的一部分)复制到其他神经网络,进行再学习。比如,准备一个和VGG相同结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
实践中经常会灵活应用使用ImageNet这个巨大的数据集学习到的权重数据,这称为迁移学习,将学习完的权重(的一部分)复制到其他神经网络,进行再学习。比如,准备一个和VGG相同结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
8.3 深度学习的高速化
8.3.1 需要努力解决的问题
 从图中可知,AlexNet中,大多数时间都被耗费在卷积层上。因此,如何高速、高效地进行卷积层中的运算是深度学习的一大课题。卷积层中进行的运算可以追溯至乘积累加运算,因此,深度学习的高速化的主要课题就变成了如何高速、高效地进行大量的乘积累加运算。
从图中可知,AlexNet中,大多数时间都被耗费在卷积层上。因此,如何高速、高效地进行卷积层中的运算是深度学习的一大课题。卷积层中进行的运算可以追溯至乘积累加运算,因此,深度学习的高速化的主要课题就变成了如何高速、高效地进行大量的乘积累加运算。
8.3.2 基于GPU的高速化
GPU原本是作为图像专用的显卡使用的,但最近不仅用于图像处理,也用于通用的数值计算。由于GPU可以高速地进行并行数值计算,因此GPU计算的目标就是将这种压倒性的计算能力用于各种用途。所谓GPU计算,是指基于GPU进行通用的数值计算的操作。
深度学习中需要进行大量的乘积累加运算(或者说大型矩阵的乘积运算)。这种大量的并行运算正是GPU所擅长的(反过来说,CPU比较擅长连续的、复杂的计算)。因此,与使用单个CPU相比,使用GPU进行深度学习的运算可以达到惊人的高速化。
GPU主要由NVIDIA和AMD两家公司提供,虽然两家的GPU都可以用于通用的数值计算,但与深度学习比较“亲近”的是NVIDIA的GPU。实际上,大多数深度学习框架只受益于NVIDIA的GPU,这是因为深度学习的框架中使用了NVIDIA提供的CUDA这个面向GPU计算的综合开发环境。

通过im2col可以将卷积层进行的运算转换为大型矩阵的乘积,这个im2col方式的实现对GPU来说是非常方便的实现方式。这是因为,相比按小规模的单位进行计算,GPU更擅长计算大规模的汇总好的数据。也就是说,通过基于im2col以大型矩阵的乘积的方式汇总计算,更容易发挥出GPU的能力。
8.3.3 分布式学习
为了创建良好的网络,需要反复进行各种尝试,这样一来就必然会产生尽可能缩短一次学习所需的时间的要求,于是,将深度学习的学习过程扩展开来的想法(也就是分布式学习)就变得重要起来。
为了进一步提高深度学习所需的计算的速度,可以考虑在多个GPU或者多台机器上进行分布式计算。现在的深度学习框架中,出现了好几个支持多个GPU或者多机器的分布式学习的框架。其中,Google的Tensorflow、微软的CNTK在开发过程中高度重视分布式学习,以大型数据中心的低延迟·高吞吐网络作为支撑,基于这些框架的分布式学习呈现出惊人的效果。
 关于分布式学习,“如何进行分布式计算”是一个非常难的课题,它包含了机器间的通信、数据的同步等多个无法轻易解决的问题,可以将这些难题都给TensorFlow等优秀的框架。
关于分布式学习,“如何进行分布式计算”是一个非常难的课题,它包含了机器间的通信、数据的同步等多个无法轻易解决的问题,可以将这些难题都给TensorFlow等优秀的框架。
8.3.4 运算精度的位数缩减
在深度学习的高速化中,除了计算量之外,内存容量、总线带宽等也有可能成为瓶颈。关于内存容量,需要考虑将大量的权重参数或中间数据放在内存中。关于总线带宽,当流经GPU(或者CPU)总线的数据超过某个限制时,就会成为瓶颈。考虑到这些情况,我们希望尽可能减少流经网络的数据的位数。
计算机中为了表示实数,主要使用64位或者32位的浮点数。通过使用较多的位来表示数字,虽然数值计算时的误差造成的影响变小了,但计算的处理成本、内存使用量却相应地增加了,还给总线带宽带来了负荷。
关于数值精度(用几位数据表示数值),我们已经知道深度学习并不那么需要数值精度的位数,这是神经网络的一个重要性质,这个性质是基于神经网络的健壮性产生的。这里所说的健壮性是指,比如,即便输入图像附有一些小的噪声,输出结果也仍然保持不变。可以认为,正是因为有了这个健壮性,流经网络的数据即便有所“劣化”,对输出结果的影响也较小。
import sys, os
sys.path.append(os.pardir) # 为了导入父目录而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from deep_convnet import DeepConvNet
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
network.load_params('deep_convnet_params.pkl')
sampled = 10000 # 为了实现高速化
x_test = x_test[:sampled]
t_test = t_test[:sampled]
print('calculate accuracy (float64) ... ')
print(network.accuracy(x_test, t_test))
# 转换为float16型
x_test = x_test.astype(np.float16)
for param in network.params.values():
param[...] = param.astype(np.float16)
print('calculate accuracy (float16) ... ')
print(network.accuracy(x_test, t_test))
8.4 深度学习的应用案例
深度学习并不局限于物体识别,还可以应用于各种各样的问题。此外,在图像、语音、自然语言等各个不同的领域,深度学习都展现了优异的性能。
8.4.1 物体检测
物体检测是从图像中确定物体的位置,并进行分类的问题。

物体检测是比物体识别更难的问题。之前介绍的物体识别是以整个图像为对象的,但是物体检测需要从图像中确定类别的位置,而且还有可能存在多个物体。
对于这样的物体检测问题,人们提出了多个基于CNN的方法,这些方法展示了非常优异的性能,并且证明了物体检测的问题上,深度学习是非常有效的。

8.4.2 图像分割
图像分割是指在像素水平上对图像进行分类,使用以像素为单位对各个对象分别着色的监督数据进行学习,然后,在推理时,对输入图像的所有像素进行分类。
 要基于神经网络进行图像分割,最简单的方法是以所有像素为对象,对每个像素执行推理处理。比如,准备一个对某个矩形区域中心的像素进行分类的网络,以所有像素为对象执行推理处理。
要基于神经网络进行图像分割,最简单的方法是以所有像素为对象,对每个像素执行推理处理。比如,准备一个对某个矩形区域中心的像素进行分类的网络,以所有像素为对象执行推理处理。
FCN方法通过一次forward处理,对所有像素进行分类。FCN的字面意思是“全部由卷积层构成的网络”。相对于一般的CNN包含全连接层,FCN将全连接层替换成发挥相同作用的卷积层。在物体识别中使用的网络的全连接层中,中间数据的空间容量被作为排成一列的节点进行处理,而只由卷积层构成的网络中,空间容量可以保持原样直到最后的输出。
 FCN的特征在于最后导入了扩大空间大小的处理,基于这个处理,变小了的中间数据可以一下子扩大和输入图像一样的大小。FCN最后进行的扩大处理是基于双线性插值法的扩大(双线性插值扩大)。FCN中,这个双线性插值扩大是通过去卷积(逆卷积运算)来实现的。
FCN的特征在于最后导入了扩大空间大小的处理,基于这个处理,变小了的中间数据可以一下子扩大和输入图像一样的大小。FCN最后进行的扩大处理是基于双线性插值法的扩大(双线性插值扩大)。FCN中,这个双线性插值扩大是通过去卷积(逆卷积运算)来实现的。
8.4.3 图像标题的生成
 有一项融合了计算机视觉和自然语言的有趣的研究,该研究如上图所示,给出一个图像后,会自动生成介绍这个图像的文字(图像的标题) 。
有一项融合了计算机视觉和自然语言的有趣的研究,该研究如上图所示,给出一个图像后,会自动生成介绍这个图像的文字(图像的标题) 。
一个基于深度学习生成图像标题的代表性方法是被称为NIC的模型。NIC由深层的CNN和处理自然语言的RNN构成。RNN是具有循环连接的网络,经常被用于自然语言、时间序列数据等连续型的数据上。
NIC基于CNN从图像中提取特征,并将这个特征传给RNN,RNN以CNN提取出的特征为初始值,循环地生成文本。NIC组合了两个神经网络(CNN和RNN)的简单结构,基于NIC,可以生成惊人的高精度的图像标题。我们将组合图像和自然语言等多种信息进行的处理称为多模态处理,多模态处理是近年来备受关注的一个领域。

RNN的R表示Recurrent(循环的) ,这个循环指的是神经网络的循环的网络结构。根据这个循环结构,神经网络会受到之前生成的信息的影响(换句话说,会记忆过去的信息),这是RNN的特征。比如,生成“我”这个词之后,下一个要生成的词受到“我”这个词的影响,生成了“要”;然后,再受到前面生成的“我要”的影响,生成了“睡觉”这个词。对于自然语言、时间序列数据等连续型的数据,RNN以记忆过去的信息的方式运行。
8.5 深度学习的未来
8.5.1 图像风格变换

有一项研究是使用深度学习来“绘制”带有艺术气息的画,如上图所示,输入两个图像后,会生成一个新的图像,两个输入图像中,一个称为“内容图像”,另一个称为“风格图像” 。在学习过程中使网络的中间数据近似内容图像的中间数据,这样一来,就可以使输入图像近似内容图像的形状。此外,为了从风格图像中吸收风格,导入了风格矩阵的概念,通过在学习过程中减小风格矩阵的偏差,就可以使输入图像接近梵高的风格。
8.5.2 图像的生成
现在有一种研究是生成新的图像时不需要任何图像(虽然需要先使用大量的图像进行学习,但在“画”新图像时不需要任何图像)。比如,基于深度学习,可以实现从零生成“卧室”的图像。

能画出以假乱真的图像的DCGAN会将图像的生成过程模型化,使用大量图像(比如,印有卧室的大量图像) 训练这个模型,学习结束后,使用这个模型,就可以生成新的图像。
DCGAN中使用了深度学习,其技术要点是使用了Generator(生成者)和Discriminator(识别者)这两个神经网络。Generator生成近似真品的图像,Discriminator判别它是不是真图像(是Generator生成的图像还是实际拍摄的图像)。像这样,通过让两者以竞争的方式学习,Generator会学习到更加精妙的图像作假技术,Discriminator则会成长为能以更高精度辨别真假的鉴定师。两者互相切磋、共同成长,这是GAN这个技术的有趣之处。在这样的切磋中成长起来的Generator最终会掌握画出足以以假乱真的图像的能力(或者说有这样的可能)。
之前我们见到的机器学习问题都被称为监督学习的问题,这类问题就像手写数字识别一样,使用的是图像数据和监督标签成对给出的数据集。不过这里讨论的问题,并没有给出监督数据,只给了大量的图像(图像的集合),这样的问题称为无监督学习。
8.5.3 自动驾驶
自动驾驶需要结合各种技术的力量来实现,比如决定行驶路线的路线计划技术、照相机或激光等传感技术等,在这些技术中,正确识别周围环境的技术据说尤其重要。这是因为要正确识别时刻变化的环境、自由来往的车辆和行人是非常困难的。

8.5.4 Deep Q-Network(强化学习)
就像人类通过摸索试验来学习一样,让计算机也在摸索试验的过程中自主学习,这称为强化学习,强化学习和有“教师”在身边教的“监督学习”有所不同。
强化学习的基本框架是,代理根据环境选择行动,然后通过这个行动改变环境,根据环境的变化,代理获得某种报酬。强化学习的目的是决定代理的行动方针,以获得更好的报酬。

 8.6 小结
8.6 小结
本章我们实现了一个(稍微)深层的CNN,并在手写数字识别上获得了超过99%的高识别精度。此外,还讲解了加深网络的动机,指出了深度学习在朝更深的方向前进。之后,又介绍了深度学习的趋势和应用案例,以及对高速化的研究和代表深度学习未来的研究案例。
深度学习领域还有很多尚未揭晓的东西,新的研究正一个接一个地出现。今后,全世界的研究者和技术专家也将继续积极从事这方面的研究,一定能实现目前无法想象的技术。
1.对于大多数的问题,都可以期待通过加深网络来提高性能;
2.在最近的图像识别大赛ILSVRC中,基于深度学习的方法独占鳌头,使用的网络也在深化;
3.VGG、GoogleNet、ResNet等是几个著名的网络;
4.基于GPU、分布式学习、位数精度的缩减,可以实现深度学习的高速化;
5.深度学习(神经网络)不仅可以用于物体识别,还可以用于物体检测、图像分割;
6.深度学习的应用包括图像标题的生成、图像的生成、强化学习等。最近,深度学习在自动驾驶上的应用也备受期待。