一、项目背景
首先分析美国总统竞选也是个烂大街的项目 ,这里来自天池学习
https://tianchi.aliyun.com/competition/entrance/531837/introduction, 利用Pandas分析美国选民总统喜好度 ,上面也有不少学习资料和视频,
可以练手数据集的处理、数据探索与清洗、数据分析、数据可视化四部分 ,主要涉及pandas ,matplotlib 和wordcloud等库,
二、项目介绍
主要对美国总统选举的投票数据进行分析和可视化,绘制词云。
2.1 数据集来源介绍
所有候选人信息 该文件为每个候选人提供一份记录,并显示候选人的信息、总收入、从授权委员会收到的转账、付款总额、给授权委员会的转账、库存现金总额、贷款和债务以及其他财务汇总信息。 数据字段描述详细:https://www.fec.gov/campaign-finance-data/all-candidates-file-description/ 关键字段说明
CAND_ID 候选人ID
CAND_NAME 候选人姓名
CAND_PTY_AFFILIATION 候选人党派
数据来源:https://www.fec.gov/files/bulk-downloads/2020/weball20.zip
候选人委员会链接信息 该文件显示候选人的身份证号码、候选人的选举年份、联邦选举委员会选举年份、委员会识别号、委员会类型、委员会名称和链接标识号。 信息描述详细:https://www.fec.gov/campaign-finance-data/candidate-committee-linkage-file-description/ 关键字段说明
CAND_ID 候选人ID
CAND_ELECTION_YR 候选人选举年份
CMTE_ID 委员会ID
数据来源:https://www.fec.gov/files/bulk-downloads/2020/ccl20.zip
个人捐款档案信息 该文件包含有关收到捐款的委员会、披露捐款的报告、提供捐款的个人、捐款日期、金额和有关捐款的其他信息。 信息描述详细:https://www.fec.gov/campaign-finance-data/contributions-individuals-file-description/ 关键字段说明
CMTE_ID 委员会ID
NAME 捐款人姓名
CITY 捐款人所在市
State 捐款人所在州
EMPLOYER 捐款人雇主/公司
OCCUPATION 捐款人职业
数据来源:https://www.fec.gov/files/bulk-downloads/2020/indiv20.zip
三、项目准备
主要是python的开发环境即可,jupyter_notebook
需要进行pandas数据的读取,合并关联,再进行分组统计可视化等,使用的是matplotlib
另外需要下载安装词云的库,wordlcoud ,当然还有用于抠图的,也就是消除图片背景的库,这里偷懒使用的是removebg 提供的服务接口
!pip install wordcloud
!pip install removebg
登录 removebg获取api地址和key
https://www.remove.bg/zh
获取key
四、项目分析处理
数据读取处理
进行数据处理前,我们需要知道我们最终想要的数据是什么样的,因为我们是想分析候选人与捐赠人之间的关系,所以我们想要一张数据表中有捐赠人与候选人一一对应的关系,所以需要将目前的三张数据表进行一一关联,汇总到需要的数据。
由于候选人和委员会的联系表中无候选人姓名,只有候选人ID(CAND_ID),所以需要通过CAND_ID从候选人表中获取到候选人姓名,最终得到候选人与委员会联系表ccl。
# 导入相关处理包
import pandas as pd
# 读取候选人信息,由于原始数据没有表头,需要添加表头
candidates = pd.read_csv("weball20.txt", sep = '|',names=['CAND_ID','CAND_NAME','CAND_ICI','PTY_CD','CAND_PTY_AFFILIATION','TTL_RECEIPTS',
'TRANS_FROM_AUTH','TTL_DISB','TRANS_TO_AUTH','COH_BOP','COH_COP','CAND_CONTRIB',
'CAND_LOANS','OTHER_LOANS','CAND_LOAN_REPAY','OTHER_LOAN_REPAY','DEBTS_OWED_BY',
'TTL_INDIV_CONTRIB','CAND_OFFICE_ST','CAND_OFFICE_DISTRICT','SPEC_ELECTION','PRIM_ELECTION','RUN_ELECTION'
,'GEN_ELECTION','GEN_ELECTION_PRECENT','OTHER_POL_CMTE_CONTRIB','POL_PTY_CONTRIB',
'CVG_END_DT','INDIV_REFUNDS','CMTE_REFUNDS'])
# 读取候选人和委员会的联系信息
ccl = pd.read_csv("ccl.txt", sep = '|',names=['CAND_ID','CAND_ELECTION_YR','FEC_ELECTION_YR','CMTE_ID','CMTE_TP','CMTE_DSGN','LINKAGE_ID'])
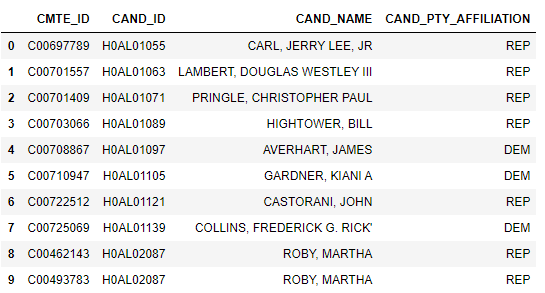
# 关联两个表数据
ccl = pd.merge(ccl,candidates)
# 提取出所需要的列
ccl = pd.DataFrame(ccl, columns=[ 'CMTE_ID','CAND_ID', 'CAND_NAME','CAND_PTY_AFFILIATION'])
可查看数据前10行
ccl.head(10)
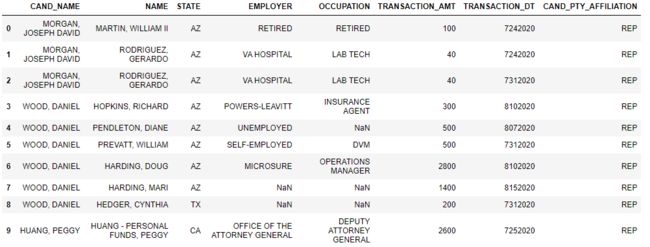
通过CMTE_ID将目前处理好的候选人和委员会关系表与人捐款档案表进行关联,得到候选人与捐赠人一一对应联系表cil。
# 读取个人捐赠数据,由于原始数据没有表头,需要添加表头
# 提示:读取本文件大概需要5-10s
itcont = pd.read_csv('itcont_2020_20200722_20200820.txt', sep='|',names=['CMTE_ID','AMNDT_IND','RPT_TP','TRANSACTION_PGI',
'IMAGE_NUM','TRANSACTION_TP','ENTITY_TP','NAME','CITY',
'STATE','ZIP_CODE','EMPLOYER','OCCUPATION','TRANSACTION_DT',
'TRANSACTION_AMT','OTHER_ID','TRAN_ID','FILE_NUM','MEMO_CD',
'MEMO_TEXT','SUB_ID'])
查看目前数据前10行
c_itcont.head(10)
数据探索与清洗
进过数据处理部分,我们获得了可用的数据集,现在我们可以利用调用shape属性查看数据的规模,调用info函数查看数据信息,调用describe函数查看数据分布。
#查看数据规模 多少行 多少列
c_itcont.shape
# 查看整体数据信息,包括每个字段的名称、非空数量、字段的数据类型
c_itcont.info()
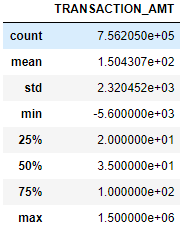
通过上面的探索我们知道目前数据集的一些基本情况,目前数据总共有756205行,8列,总占用内存51.9+MB,STATE、EMPLOYER、OCCUPATION有缺失值,另外日期列目前为int64类型,需要进行转换为str类型。
#空值处理,统一填充 NOT PROVIDED
c_itcont['STATE'].fillna('NOT PROVIDED',inplace=True)
c_itcont['EMPLOYER'].fillna('NOT PROVIDED',inplace=True)
c_itcont['OCCUPATION'].fillna('NOT PROVIDED',inplace=True)
# 对日期TRANSACTION_DT列进行处理
c_itcont['TRANSACTION_DT'] = c_itcont['TRANSACTION_DT'] .astype(str)
# 将日期格式改为年月日 7242020
c_itcont['TRANSACTION_DT'] = [i[3:7]+i[0]+i[1:3] for i in c_itcont['TRANSACTION_DT'] ]
c_itcont['TRANSACTION_DT']
再次查看数据信息
c_itcont.info()

查看数据表中数据类型的列的数据分布情况
c_itcont.describe()
4、数据分析
计算每个党派的所获得的捐款总额,然后排序,取前十位
c_itcont.groupby("CAND_PTY_AFFILIATION").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
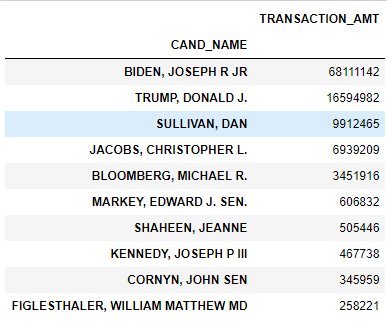
查看不同职业的人捐款的总额,然后排序,取前十位
c_itcont.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)

每个州获捐款的总额,然后排序,取前五位
c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False).head(5)

c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False).head(20)
4、数据可视化
首先导入相关Python库
导入matplotlib中的pyplot
import matplotlib.pyplot as plt
为了使matplotlib图形能够内联显示
%matplotlib inline
导入词云库
from wordcloud import WordCloud,ImageColorGenerator
4.1 按州总捐款数和总捐款人数柱状图
# 各州总捐款数可视化
st_amt = c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False)[:10]
st_amt=pd.DataFrame(st_amt, columns=['TRANSACTION_AMT'])
st_amt.plot(kind='bar')
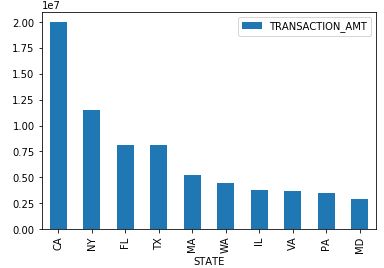
4.2 各州捐款总人数可视化
# 各州捐款总人数可视化,取前10个州的数据
st_amt = c_itcont.groupby('STATE').size().sort_values(ascending=False).head(10)
st_amt.plot(kind='bar')

4.3 热门候选人拜登在各州的获得的捐赠占比
# 从所有数据中取出支持拜登的数据
biden = c_itcont[c_itcont['CAND_NAME']=='BIDEN, JOSEPH R JR']
# 统计各州对拜登的捐款总数
biden_state = biden.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False).head(10)
# 饼图可视化各州捐款数据占比
biden_state.plot.pie(figsize=(10, 10),autopct='%0.2f%%',subplots=True)
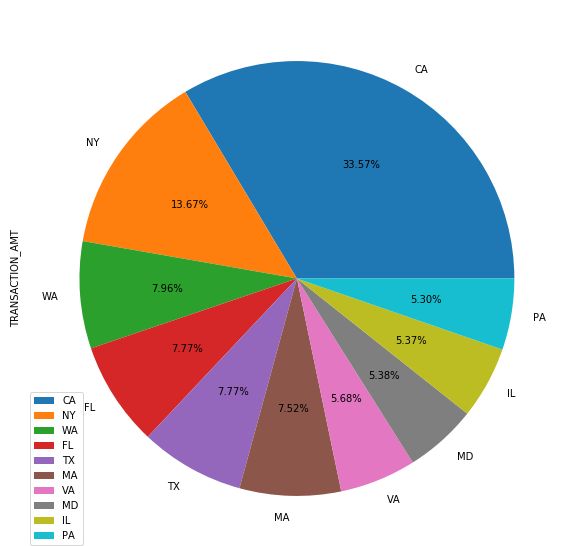
4.3 总捐最多的候选人捐赠者词云图
通过数据分析中获得捐赠总额前三的候选人统计中可以看出拜登在2020.7.22-2020.8.20这期间获得捐赠的总额是最多的,所以我们以拜登为原模型,制作词云图。
下载原图
!wget https://img.alicdn.com/tfs/TB1D0l4pBBh1e4jSZFhXXcC9VXa-298-169.jpg

根据上面获取的api key 进行抠图
具体是需要将人图像和背景颜色分离,然后用纯色填充
from removebg import RemoveBg
from PIL import Image
#import os
#抠图,抠出人像
rmbg = RemoveBg("xuheKF3SUFeNzZjhrAHk83Xu", "error.log") # 引号内是你获取的API,在官网获得
rmbg.remove_background_from_img_file("bidenyuan.jpg") #图片地址
#重命名为.jpg文件
img_path="bidenyuan.jpg_no_bg.png"
output_img_path="bidenyuan_no_bg.jpg"
#os.rename('bidenyuan.jpg_no_bg.png', 'bidenyuan_no_bg.jpg')
im = Image.open(img_path)
im = im.convert("RGB")
im.save(output_img_path)
img = Image.open('bidenyuan_no_bg.jpg')
#============2.处理图片============
#将图片分成小方块
img_array = img.load()
#遍历每一个像素块,并处理颜色
width, height = img.size#获取宽度和高度
for x in range(0,width):
for y in range(0,height):
rgb = img_array[x,y]#获取一个像素块的rgb
r = rgb[0]
g = rgb[1]
b = rgb[2]
if r>0 and g > 0 and b>0:#判断规则
img_array[x, y] = (0,234, 0)
if r==0 and g==0 and b==0:
img_array[x,y] = (255,255,255)
#============3.保存图片============
img.save("bidentest.jpg")
绘制词云
# 将所有捐赠者姓名连接成一个字符串
data = ' '.join(biden["NAME"].tolist())
# 读取图片文件
bg = plt.imread("bidentest.jpg")
# 生成
wc = WordCloud(# FFFAE3
background_color="white", # 设置背景为白色,默认为黑色
width=890, # 设置图片的宽度
height=600, # 设置图片的高度
mask=bg, # 画布
margin=10, # 设置图片的边缘
max_font_size=100, # 显示的最大的字体大小
random_state=20, # 为每个单词返回一个PIL颜色
).generate_from_text(data)
# 图片背景
bg_color = ImageColorGenerator(bg)
# 开始画图
plt.imshow(wc.recolor(color_func=bg_color))
# 为云图去掉坐标轴
plt.axis("off")
# 画云图,显示
# 保存云图
wc.to_file("biden_wordcloudtest.png")

词云参数:
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) //如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
min_font_size : int (default=4) //显示的最小的字体大小
font_step : int (default=1) //字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
max_words : number (default=200) //要显示的词的最大个数
stopwords : set of strings or None //设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default=”black”) //背景颜色,如background_color='white',背景颜色为白色。
max_font_size : int or None (default=None) //显示的最大的字体大小
mode : string (default=”RGB”) //当参数为“RGBA”并且background_color不为空时,背景为透明。
relative_scaling : float (default=.5) //词频和字体大小的关联性
color_func : callable, default=None //生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) //使用正则表达式分隔输入的文本
collocations : bool, default=True //是否包括两个词的搭配
colormap : string or matplotlib colormap, default=”viridis” //给每个单词随机分配颜色,若指定color_func,则忽略该方法。
fit_words(frequencies) //根据词频生成词云
generate(text) //根据文本生成词云
generate_from_frequencies(frequencies[, ...]) //根据词频生成词云
generate_from_text(text) //根据文本生成词云
process_text(text) //将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies) )
recolor([random_state, color_func, colormap]) //对现有输出重新着色。重新上色会比重新生成整个词云快很多。
to_array() //转化为 numpy array
to_file(filename) //输出到文件