分水岭算法java,OpenCV 学习笔记 04 深度估计与分割——GrabCut算法与分水岭算法...
1 使用普通摄像头进行深度估计
1.1 深度估计原理
这里会用到几何学中的极几何(Epipolar Geometry),它属于立体视觉(stereo vision)几何学,立体视觉是计算机视觉的一个分支,它从同一物体的两张不同图像提取三维信息。
极几何的工作原理:
它跟踪从摄像头到图像上每个物体的虚线,然后再第二张图像做同样的操作,并根据同一物体对应的线的交叉来计算距离。
在使用 OpenCV 如何使用极几何来计算所谓的视差图,它是如图像中检测到不同深度的基本表示,这样就能够提取出一张图片的前景部分而抛弃其余部分。
注意:进行深度估计需要同一物体在不同视角下拍摄的两幅图像,但是要注意这两幅图像是距物体相同距离,否则计算将会失败,视差图也就没有意义。
下图为工作原理示意图

1.2 深度估计函数 StereoSGBM
下面例子是使用同一物体的两幅图像来计算视差图,距离摄像头近的点在视差图中会有更明亮的颜色,黑色区域代表两幅图像的差异部分。
import numpy as np
import cv2
def update(val = 0):
# disparity range is tuned for 'aloe' image pair
stereo.setBlockSize(cv2.getTrackbarPos('window_size','disparity'))
stereo.setUniquenessRatio(cv2.getTrackbarPos('uniquenessRatio','disparity'))
stereo.setSpeckleWindowSize(cv2.getTrackbarPos('speckleWindowsize','disparity'))
stereo.setSpeckleRange(cv2.getTrackbarPos('speckleRange','disparity'))
stereo.setDisp12MaxDiff(cv2.getTrackbarPos('disp12MaxDiff','disparity'))
print('computing disparity...')
disp = stereo.compute(imgL, imgR).astype(np.float32) / 16.0
# cv2.imshow('left', imgL)
cv2.imshow('disparity', (disp-min_disp) / num_disp)
if __name__ == '__main__':
window_size = 5
min_disp = 16
num_disp = 192 - min_disp
blockSize = window_size
uniquenessRatio = 1
speckleRange = 3
speckleWindowSize = 3
disp12MaxDiff = 200
P1 = 600
P2 = 2400
# 加载两幅图
imgL = cv2.imread('tsukuba_right.jpg')
imgR = cv2.imread('tsukuba_left.jpg')
cv2.namedWindow('disparity')
cv2.createTrackbar('speckleRange','disparity',speckleRange,50,update)
cv2.createTrackbar('window_size','disparity',window_size,21,update)
cv2.createTrackbar('speckleWindowSize','disparity',speckleWindowSize,200,update)
cv2.createTrackbar('uniquenessRatio','disparity',uniquenessRatio,50,update)
cv2.createTrackbar('disp12MaxDiff','disparity',disp12MaxDiff,250,update)
# 创建一个StereoSGBM实例,是一种计算视图差的算法
# 并创建几个跟踪条来调整算法参数,然后调用update函数
# update函数将跟踪条的值传给StereoSGBM实例
# StereoSGBM是semiglobal block matching 的缩写
stereo = cv2.StereoSGBM_create(
minDisparity = min_disp,
numDisparities = num_disp,
blockSize = window_size,
uniquenessRatio = uniquenessRatio,
speckleRange = speckleRange,
speckleWindowSize = speckleWindowSize,
disp12MaxDiff = disp12MaxDiff,
P1 = P1,
P2 = P2
)
update()
cv2.waitKey()
1 GrabCut算法
1.1 GrabCut算法简介
GrabCut是一种基于图切割的图像分割方法。GrabCut算法是基于Graph Cut算法的改进。
基于要被分割对象的指定边界框开始,使用高斯混合模型估计被分割对象和背景的颜色分布(注意,这里将图像分为被分割对象和背景两部分)。简而言之,就是只需确认前景和背景输入,该算法就可以完成前景和背景的最优分割。
该算法利用图像中纹理(颜色)信息和边界(反差)信息,只要少量的用户交互操作就可得到较好的分割效果,和分水岭算法比较相似,但计算速度比较慢,得到的结果比较精确。若从静态图像中提取前景物体(例如从一个图像剪切到另外一个图像),采用GrabCut算法是最好的选择。
1.2 GrabCut函数参数及返回值
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) -> mask, bgdModel, fgdModel
参数:
img - 8 位 3 通道图像。这也说明输入的为彩色图像
mode - 操作模式,可以是 GrabCutModes 模式中的一种。枚举值enmu
GC_INIT_WITH_RECT(=0),用矩形窗口初始化GRabCut;
GC_INIT_WITH_MASK(=1),用掩码图像初始化GrabCut;
GC_EVAL(=2),执行分割
引用原语句
enum
cv::GrabCutModes {
cv::GC_INIT_WITH_RECT = 0,
cv::GC_INIT_WITH_MASK = 1,
cv::GC_EVAL = 2
}
详细内容
Enumerator
GC_INIT_WITH_RECT
The function initializes the state and the mask using the provided rectangle. After that it runs iterCount iterations of the algorithm.
该函数使用提供的矩形初始化状态和掩码。之后,它运行算法的iterCount迭代
GC_INIT_WITH_MASK
The function initializes the state using the provided mask. Note that GC_INIT_WITH_RECT and GC_INIT_WITH_MASK can be combined. Then, all the pixels outside of the ROI are automatically initialized with GC_BGD .
该函数使用提供的掩码初始化状态。请注意,可以组合GC_INIT_WITH_RECT和GC_INIT_WITH_MASK。然后,使用GC_BGD自动初始化ROI外部的所有像素。
GC_EVAL
The value means that the algorithm should just resume.
该值意味着算法应该恢复
参考:
mask - 输入/输出 8 位单通道掩码, 当mode = GC_INIT_WITH_RECT时,该函数初始化掩码。若使用掩码进行初始化,那么 mask 保存初始化掩码信息,在执行分割的时候,也将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
GCD_BGD(=0),背景;
GCD_FGD(=1),前景;
GCD_PR_BGD(=2),可能的背景;
GCD_PR_FGD(=3),可能的前景。
rect - 包含分割对象的矩形ROI(Region of Interesting,ROI,感兴趣区域),ROI外部的像素标记为背景,ROI内部的像素标记为前景。该参数仅在mode=GC_INIT_WITH_RECT情况下使用。(用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理)。注意,矩形的形式为(x, y, 宽, 高 ) 。
bgdModel - 背景模型的临时数组。 处理同一图像时,请勿修改它。
fgdModel - 前景模型的临时数组。 处理同一图像时,请勿修改它。
iterCount - 返回结果之前算法应该进行的迭代次数。 请注意,可以使用mode == GC_INIT_WITH_MASK或mode == GC_EVAL进一步调用结果。
1.3 GrabCut 算法的实现步骤
1.在图片中定义含有(一个或者多个)物体的矩形
2.矩形外的区域被自动认为是背景
3.对于用户定义的矩形区域,可用背景中的数据来区别它里面的前景和背景区域
4.用高斯混合模型来对背景和前景建模,并将未定义的像素标记为可能的前景或背景
5.图像中欧冠的每一个像素都被看作通过虚拟边与周围像素相连接,而每条边都有一个属于前景或背景的概率,这基于它与周围颜色上的相似性
6.每一个像素(即算法中的节点)会与一个前景或背景节点链接
7.在节点完成链接后,若节点之间的边属于不同终端,则会切断它们之间的边,这就能将图像各部分分割出来
1.4 代码示例
import numpy as np
import cv2
from matplotlib import pyplot as plt
#使用分水岭和GrabCut算法进行物体分割
img = cv2.imread('small.jpg')
# img.shape=(1039, 690, 3)
# img.shape[0:2]=(1039, 690)
mask = np.zeros(img.shape[:2],np.uint8)
# 背景色bgdModel,前景色fgdModel
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
# 感兴趣区域ROI的x,y,宽度,高度
rect = (100,1,500,1000)
# 获得返回值mask、bgdModel、fgdModel。
# 目标图像、掩码、感兴趣区域,背景、前景、算法迭代次数、操作模式
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
# 经过图像分割法grabCut处理之后,
# print(set(mask.ravel())) -> {0,2,3}
# mask的掩码元素{0}->{0,2,3}
# where(condition,x,y),condition为array_like或bool
# 真yield x,假yield y
# mask==0背景、==1前景、==2可能的背景、==3可能的前景
# 当为背景/可能是背景时赋0,当为前景/可能背景赋1
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
# mask2.shape=(1039,690),
# img.shape=(1039,690,3)
# 两者乘积则报错:
# 操作数无法与形状一起广播
# ValueError: operands could not be broadcast together with shapes (1039,690,3) (1039,690)
# 为了保持数形一致,增加np.newaxis
# mask2[:,:,np.newaxis].shape=(1039,690,1)
# 这样当行列值不相等时可进行广播计算
# 经过计算后,将背景色赋值为0,即为黑色
img = img*mask2[:,:,np.newaxis]
# subplot(121)创建1行2列,当前位置为1
plt.subplot(121), plt.imshow(img)
plt.title("grabcut"), plt.xticks([]), plt.yticks([])
# subplot(122)当前位置为2
plt.subplot(122), plt.imshow(cv2.cvtColor(cv2.imread('small.jpg'), cv2.COLOR_BGR2RGB))
plt.title("original"), plt.xticks([]), plt.yticks([])
plt.show()
运行

1.5 GrabCut算法参考文章:
2 分水岭算法 watershed algorithm 图像分割
分水岭算法 watershed algorithm方法是一种基于边界点的分割算法。
2.1 分水岭简介
任何灰度图都可以看成带有等高线的地形图,灰度值越高,其海拔越高。若向该地貌中注水,则海拔低处优先被淹没,同时水也会汇集,为了防止水的汇集,则筑坝对不同区域的水源进行分割,此时的坝就是区域的边界。

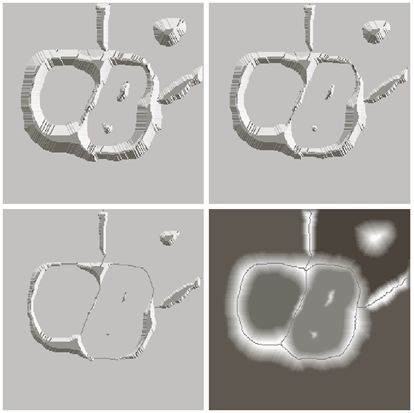
从上述较为形象化的分析可以看出:由于灰度值图像中的噪声和局部的不规则性,该方法可能会造成过度分割
针对上述的缺点进行优化 - 分水岭的标记控制 Marker-controlled watershed。该方法可以有效地防止过度分割。
详细内容参看
2.2 watershed函数参数及返回值
作用:基于标记的分水岭算法进行图像分割
cv2.watershed(image, markers) -> markers
参数:
image - 8 位 3通道图像
markers - 输入 / 输出标记的32位单通道图像(映射),它应该与图像大小相同。
注意:
图像 image 参数必须提前处理,使用正(\>0)索引粗略勾画图像标记中的所需区域。因此,每个区域被表示为具有像素值1,2,3等的一个或多个连通分量。 可以使用# findContours 和 # drawContours 从二进制掩码中检索此类标记(请参阅watershed.cpp演示)。标记是未来图像区域的“种子”。标记中的所有其他像素(其与轮廓区域的关系未知且应由算法定义)应设置为0。 在函数输出中,标记中的每个像素设置为“种子”组件的值,或者设置为区域之间的边界处的-1。
2.3 分水岭算法流程
从代码和最终结果里可以大致的看出算法的流程:
1.进行灰度化
2.高斯滤波以消除噪声的干扰
3.用canny算子检测边缘
4.用findcontours查找轮廓
5.利用轮廓特征,实现图像分割
2.4 分水岭算法代码示例
这段代码没有验证。直接复制。
import numpy as np
import cv2
from matplotlib import pyplot as plt
#使用分水岭算法进行图像分割
img = cv2.imread('timg.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#将颜色转为灰度后,可为图像设一个阈值,将图像分为两部分:黑色部分和白色部分
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# noise removal 噪声去除,morphologyEx是一种对图像进行膨胀之后再进行腐蚀的操作
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2)
# sure background area 确定背景区域,图像进行膨胀操作
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area,通过distanceTransform来获取确定的前景区域
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)
# Marker labelling
ret, markers = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0
markers = cv2.watershed(img,markers)
img[markers == -1] = [255,0,0]
plt.imshow(img)
plt.show()
运行
该代码没有调试,没有深究代码中的逻辑关系,部分不理解的函数作用及参数、返回值没有深究。
附原图:

2.5 分水岭算法参考
OpenCV 学习笔记 04 深度估计与分割
本章节主要是使用深度摄像头的数据来识别前景区和背景区,这样就可以分别对前景和背景做不同的处理. 1 创建模块
(转) OpenCV学习笔记大集锦 与 图像视觉博客资源2之MIT斯坦福CMU
首页 视界智尚 算法技术 每日技术 来打我呀 注册 OpenCV学习笔记大集锦 整理了我所了解的有关OpenCV的学习笔记.原理分析.使用例程等相关的博文.排序不分先后,随机整理的 ...
opencv学习笔记(一)IplImage, CvMat, Mat 的关系
opencv学习笔记(一)IplImage, CvMat, Mat 的关系 opencv中常见的与图像操作有关的数据容器有Mat,cvMat和IplImage,这三种类型都可以代表和显示图像,但是,M ...
OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
OpenCV 学习笔记 02 使用opencv处理图像
1 不同色彩空间的转换 opencv 中有数百种关于不同色彩空间的转换方法,但常用的有三种色彩空间:灰度.BRG.HSV(Hue-Saturation-Value) 灰度 - 灰度色彩空间是通过去除彩 ...
【opencv学习笔记五】一个简单程序:图像读取与显示
今天我们来学习一个最简单的程序,即从文件读取图像并且创建窗口显示该图像. 目录 [imread]图像读取 [namedWindow]创建window窗口 [imshow]图像显示 [imwrite]图 ...
OpenCV学习笔记3
OpenCV学习笔记3 图像平滑(低通滤波) 使用低通滤波器可以达到图像模糊的目的.这对与去除噪音很有帮助.其实就是去除图像中的高频成分(比如:噪音,边界).所以边界也会被模糊一点.(当然,也有一些模 ...
opencv学习笔记(七)SVM+HOG
opencv学习笔记(七)SVM+HOG 一.简介 方向梯度直方图(Histogram of Oriented Gradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子 ...
opencv学习笔记(六)直方图比较图片相似度
opencv学习笔记(六)直方图比较图片相似度 opencv提供了API来比较图片的相似程度,使我们很简单的就能对2个图片进行比较,这就是直方图的比较,直方图英文是histogram, 原理就是就是将 ...
随机推荐
position属性absolute与relative 详解
最近一直在研究javascript脚本,熟悉DOM中CSS样式的各种定位属性,以前对这个属性不太了解,从网上找到两篇文章感觉讲得很透彻,收藏下来,唯恐忘记.一.解读absolute与relative ...
Yii中的错误及异常处理
Yii中的错误及异常处理 Yii已经默认已经在CApplication上实现了异常和错误的接管,这是通过php的set_exception_handler, set_error_handler实现的. ...
linq 和 , 并 , 差 ,交
假如: A = [--.], B = [-.] A 并 B = 全部 linq : a.union(b) A 交 B = 中间那块 linq: a.Intersect(b) ...
请问set JAVA_OPTS的各项參数是什么意思?
http://topic.csdn.net/u/20090910/10/20c6ba01-28ac-482e-94b2-bfce0a952f77.html 请问set JAVA_OPTS的各项參数是什 ...
CodeRush Xpress的菜单在VS2008SP1中不显示的解决方法
将HKEY_LOCAL_MACHINE\SOFTWARE\Developer Express\CodeRush for VS\9.1中的HideMenu设置为0.若HideMenu不存在就创建个DWO ...
idea之debug