以下文章来源于人人都学大数据 ,作者Cassie
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址:http://github.com/apache/pulsar/
文章转自:人人都学大数据,作者:王嘉凌
文章内容整理自:中国移动云能力中心,移动云 Pulsar 产品负责人王嘉凌在 Pulsar Summit Asia 2021 的视频分享内容。
Pulsar Summit Aisa 2021 已在 2022 年 1 月 15-16 日于线上举办。会上,30 位嘉宾围绕 26 个议题,分享了最前沿的 Apache Pulsar 实践经验、场景案例、技术探究和运维故事。
下面我们将回顾来自移动云的王嘉凌工程师分享的 Apache Pulsar 在移动云智能运维平台的应用实践。

扫描下方图片查看完整版视频回顾:

移动云智能运维平台
移动云智能运维平台是集资源配置、告警指标、性能监控、日志管理、故障处理等功能为一体的企业级 DevOPS 平台,帮助运维、研发工作者快速掌握集群最新态势,提取关键信息,让运维工作更便捷。
平台旨在打造 N+31+X 的资源布局,面对近 5 万台物理机、9000 多网络设备,搭建这样一个系统会存在很多现实的问题包括:
- 物理机在哪个机房、哪个机柜、哪个机架?物理机有多少核、多少内存、多少存储?
- 这么多设备告警、性能数据怎么办?如何采集、处理?
- 设备出了故障,如何快速定位,如何调度故障处理人员?
- 大部分服务是分布式的,日志散落在不同的节点,如何快速检索日志去定位问题?
而这些问题都是需要移动云智能运维平台去解决或者探索的,智维平台肩负着智能化集中运维的重大使命。
移动云智能运维平台的总体架构如下:

其中起到承上启下作用的是运维数据平台。运维数据平台下层对接基础运维平台接收采集数据,上层对接运维能力层提供数据查询和分析的接口。
移动云团队选择 Pulsar 作为运维数据平台的核心技术,利用 Pulsar 作为数据管道实现数据接入、数据加工,数据消费和数据投递的能力。基于 Pulsar 的计算存储分离特性提供了可扩展的数据管道;基于 Pulsar Function 计算框架构建统一运维数据加工 DSL,实现高效数据集成;基于 Pulsar Sink 改造实现了运维数据投递功能,同时基于 PrestoDB 构建统一 SQL,实现 Elasticsearch、ClickHouse 的统一查询分析,并且通过 DSL 领域翻译服务提供运维专用查询分析语法,提高运维查询效率。

简而言之,Pulsar 在运维数据平台中的作用就是接收日志数据,进行加工后投递到 Elasticsearch 和 ClickHouse 中。后者再给上层提供数据查询和数据分析的能力。

相较于业界常用的 ELK 或者基于 Kafka 的数据管道方案,选择 Pulsar 存在明显的优势:一方面的话相较于 Kafka 有着更好的运维体验,这得益于 Pulsar 计算存储分离的架构以及租户隔离的机制,同时在稳定性,一致性方面也做了很大的改善;另一方面的话相较于 Logstash,利用 Pulsar Function 进行数据加工有着更好的灵活性和更高的性能。
基于 Pulsar Function 的日志加工 DSL 实现
Pulsar Function
Pulsar Function 实现了基于 Pulsar 的函数计算,本质上是一个独立运行的 Java 模块,从 input topic 中接收消息,在 Function 中对消息内容进行加工处理,并输出结果到 output topic 中。

开发者只需要实现 Function 接口提供消息的处理逻辑。

Function worker 是 Function 的配置,调度和运行时管理平台,提供线程,进程,以及 K8s 三种 Function 的运行状态。

日志加工的难题
Pulsar Function 只是提供了运行时的函数计算能力,在实际业务中如何利用 Function 对日志进行加工,仍然有很多难题:
- 日志源在不断增加,日志数据差异大。
- 日志加工逻辑的需求越来越复杂:结构化、清洗、脱敏、数据分发、多源汇聚、数据富化等等。
- 如何设计加工函数来动态加载不同的加工逻辑
为了解决这些难题,需要提供一套 DSL 语法,也就是日志加工专用语法,来灵活地控制并处理原始日志数据。基于日志加工逻辑的需求,需要这套 DSL 能够在计算上提供丰富的函数算子和场景化自定义逻辑,对于复杂需求则可以通过流程控制、条件判断实现逻辑组合和编排。

DSL 语法解析
实现 DSL 语法,需要用到语法解析器。移动云技术团队使用的是 Antlr4,这款语法解析器也在 Spark 计算引擎中用来解析 SQL,可以根据事先配置好的语法文件来解析 DSL 语言,为每条语句生成一个 Statement,整个 DSL 就会生成一个 Statement 列表。一个 Statement 包含两部分信息,语法关键字和参数列表。
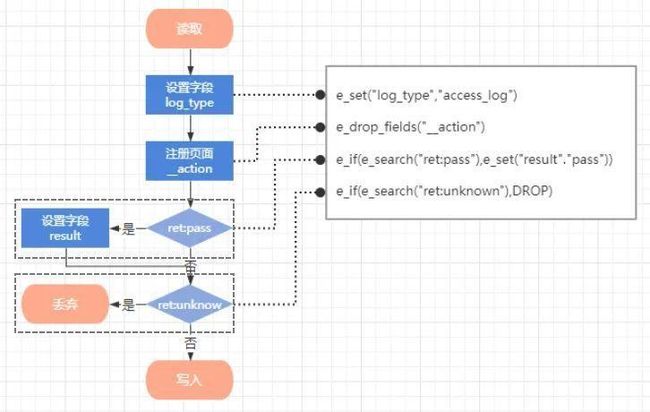
然后就可以给每个语法定义加工函数。FunctionArgs 是从 Statsment 中解析出来的加工参数列表,Context 是已经转为 json 格式的日志内容。
![]()
那么设置字段这个通用的语法,就可以实现为从 Context 中找出对于的字段然后替换掉值这样的简单的操作。加工函数的返回值定义为 Context 的 list 是因为存在日志分裂的场景需要将一条原始日志拆为多条日志再进行后续处理。
DAG 执行计划
完成 DSL 的语法解析之后,需要构建执行计划并进行运行时调度。这里采用了 DAG 图来建模,DAG 表示有向无环图,Spark 处理数据的时候会将计算转化为一个 DAG 图来进行调度,移动云技术团队参考了这种思路,将 DSL 解析生成的 Statement 列表转为 DAG 图,让加工过程分解为可并行计算的任务。
DSL 语句:
e_set(...);
e_drop_fields(...);
e_if_else(bool,e_set(...),e_set(...));
e_set(...);
e_output(...);DAG 图:
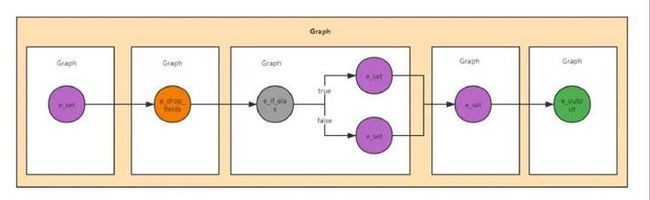
DAG 图中的每个节点对应一个 Statement,即包含了一个加工函数和对应的加工参数,那么 DSL 语句的执行就可以转化为遍历 DAG 图并依次执行每个节点对应的加工函数的操作。DAG 有向无环图的特性可以保证从根节点开始遍历的过程不会形成闭环,遍历完尾节点就表示加工处理结束。
DAG 执行调度
解析 DSL 语句并构建 DAG 任务后,下一步需要考虑如何在 Function 中实现调度。整体的设计思路是将加工 DSL 语句以自定义参数的形式传入 Function 配置参数,事先对 DSL 进行解析并构建出 DAG 任务,然后基于数据驱动流程的方式对每条消息进行加工。
为 Function 添加 onStart 和 onStop 接口,在启动 Function 时执行 DSL 解析以及全局资源初始化。
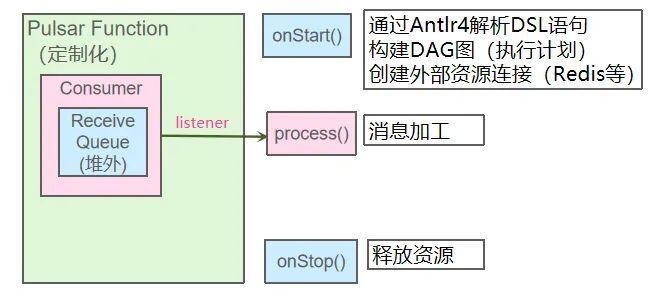
在 Function 的 Process 接口的实现中只是把消息内容和对应的 DAG 执行计划一起放入缓存队列,此时并不做消息结果投递和消息确认。消息加工和消息结果投递这两种相对比较耗时的处理放在异步的线程池里执行,完成后再确认消息。
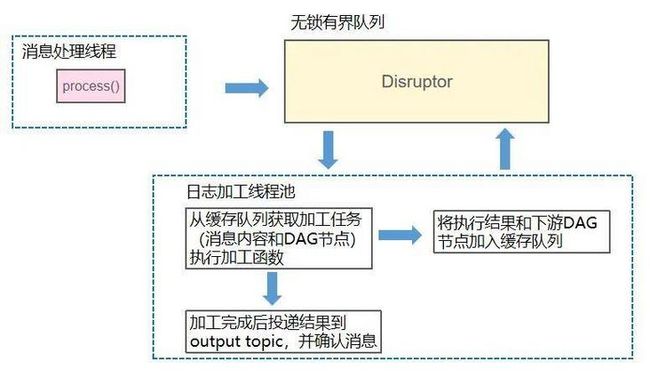
首先移动云技术团队选择了高性能无锁队列 Disruptor 作为缓存队列。Disruptor 使用一个环形数组 RingBuffer 作为队列,队列的生产者和消费者基于 CAS 操作申请可操作元素在数组中的位置,获取成功后写入或者读取该位置的数据,从而避开了锁竞争的问题。相比有锁队列在性能上有很大的优势。
最后,移动云技术团队选择的 DAG 执行调度方案是把单个 DAG 节点的处理作为日志加工线程的实现,一条消息进入日志加工线程后完成当前节点的加工处理,然后选取下游节点和当前消息加工的处理结果重新放回缓存队列,等待下一次调度。处理完尾结点后进行消息的投递和确认,希望可以重复利用线程池内部的线程来提高数据处理的效率。
以上就是移动云技术团队基于 Pulsar Function 的 DSL 日志加工处理的设计和实现过程,依托该能力,可以轻松构建面向数据规范化,结构化等复杂场景的日志预处理,为后续的日志查询分析阶段准备数据,同时也极大地降低了运维成本。
展望:基于 BookKeeper 打造全文索引,时序索引融合的分布式数据存储引擎
目前在 Pulsar Function 中加工完的数据会投递到 Elasticsearch 和 ClickHouse 中,分别建立索引以便后续的查询分析使用,加上 Pulsar 本身使用 BookKeeper 对数据的持久化,就会在数据存储上有很多冗余。另外虽然 Pulsar 提供了基于 Presto 的 SQL 查询,但面对海量数据源的场景下的查询性能无法满足要求。
BookKeeper 是一个非常完善的分布式数据存储引擎,期望能够结合写入 BookKeeper 的日志数据是经过了预处理加工的结构化数据,且不会有更新操作的特性,对 BookKeeper 中的数据建立全文索引和时序索引,让上层应用可以直接查询分析 BookKeeper 中存储的数据。并利用 BookKeeper 的横向扩展能力和分成存储的特性打造全文索引,时序索引融合的可无限扩容的分布式数据存储引擎。
相关阅读
关注公众号「Apache Pulsar」,获取更多技术干货
加入 Apache Pulsar 中文交流群

点击链接 ,观看视频回顾!