PDF 生成插件 flying saucer 和 iText
最近的项目中遇到了需求,用户在页面点击下载,将页面以PDF格式下载完成供用户浏览,所以上网找了下实现方案。
在Java世界,要想生成PDF,方案不少,所以简单做一个小结吧。
在此之前,先来勾画一下我心中比较理想的一个解决方案。在企业应用中,碰到的比较多的PDF的需求,可能是针对某个比较典型的具备文档特性的内容,导出成为PDF进行存档。由于我们现在往往使用一些开源框架,诸如ssh来构建我们的应用,所以我们相对熟悉的方案是针对具体的业务逻辑设计实体,使用开源框架来实现我们的业务逻辑。而PDF的导出,最好不要破坏现有的程序框架,甚至能复用我们业务逻辑层的代码。因为如果把PDF作为一种特殊的表现形式的话,实际上它有点类似模板。最佳的情况,是我们能够通过编写某种模板,把PDF的大概样子确定下来,然后把数据和模板做一次整合,得到最后的结果
带着这个目标,开始在网上搜索解决方案。也找到了一些方案,下面简单小结一下:
Jasper Report
看到的市面上采用的最多的方案,是Jasper Report。相关的文档也很多,不过很杂,需要完全掌握,我认为还是有些坡度和时间的。这个时间和坡度我认为主要来自于对iReport这个IDE的反复尝试,对里面的每个属性的摸索。
Jasper Report的设计思路,本身是不违反我上面所说的初衷的。因为我们的努力方向是先生成模板,然后得到数据,最后将两者整合得到结果。但是Jasper Report的问题在于,其生成模板的方式过于复杂,即使有IDE的帮助,我们还是需要对其中的众多规则有所了解才行,否则就会给调试带来极大的麻烦。
所以,我认为Jasper Report是一个半调子方案,这种强依赖于IDE进行可视化编辑的方式令我很不爽。同时,由此带来的诸多的限制,相信也让很多使用者颇为头疼。在经历了一番痛苦的挣扎后,决定放弃使用这种方案。
iText
其实Jasper Report是基于iText的。于是有的人会说,那么直接使用iText不是一种倒退么?的确,直接使用iText似乎就需要直接使用原生的API进行编程了。不过幸好iText其实提供了一些方便的API,通过使用这些API,我们可以直接将HTML代码转化成iText可识别的Document对象,从而导出PDF文档。
java代码:
1 import java.io.FileOutputStream; 2 import java.io.FileReader; 3 import java.util.ArrayList; 4 5 import com.lowagie.text.Document; 6 import com.lowagie.text.Element; 7 import com.lowagie.text.html.simpleparser.HTMLWorker; 8 import com.lowagie.text.html.simpleparser.StyleSheet; 9 import com.lowagie.text.pdf.PdfWriter; 10 11 public class MainClass { 12 public static void main(String[] args) throws Exception { 13 Document document = new Document(); 14 StyleSheet st = new StyleSheet(); 15 st.loadTagStyle("body", "leading", "16,0"); 16 PdfWriter.getInstance(document, new FileOutputStream("html2.pdf")); 17 document.open(); 18 ArrayList p = HTMLWorker.parseToList(new FileReader("example.html"), st); 19 for (int k = 0; k < p.size(); ++k) 20 document.add((Element) p.get(k)); 21 document.close(); 22 } 23 }
这是从网上找到的一个例子。从代码中,我们可以看到,iText本身提供了一个简单的HTML的解析器,它可以把HTML转化成我们需要的PDF的document。
有了这个东西,基本上我的目标就能达成一大半了。接下来我的任务就是根据实际情况去编写HTML代码,然后扔进这个方法,就OK了。而真正的HTML代码,我们则可以在这里使用真正的模板技术,Freemarker或者Velocity去生成我们所需要的内容。当然,这已经是我们熟门熟路的东西了。
正当我觉得这个方案基本能符合我的要求的时候,我也同样找到了它的很多弱项:
1. 无法识别很多HTML的tag和attribute(应该是iText的HTMLParser不够强大)
2. 无法识别CSS
如果说第一点我还可以勉强接受的话,那么第二点我就完全不能接受了。无法识别简单的CSS,就意味着HTML失去了最基本的活力,也无法根据实际要求调整样式。
所以这种方案也必然无法成为我的方案。
flying sauser
在这种情况下,我几乎已经燃起了自己编写一个支持CSS解析的HTML Parser的想法。幸好,在一个非常偶然的情况下,我在google中搜到了这样一个开源项目,它能够满足我的一切需求。这就是flying sauser,项目主页是:https://xhtmlrenderer.dev.java.net/
项目的首页非常吸引人:An XML/XHTML/CSS 2.1 Renderer。这不正是我要的东西么?
仔细再看里面的文档:
完美了。这东西能解析HTML和CSS,而且能输出成image,PDF等格式。哇!我们来看看sample代码(代码丑陋,不过已经能说明问题了):
java代码:
运行,成功!实在太简单了!API帮你完成了一切!
有了这个东西,我们就可以将PDF的生成流程变成这样:
1) 编写Freemarker或者Velocity模板,打造HTML,勾画PDF的样式(请任意使用CSS)
2) 在你的业务逻辑层引入Freemarker的引擎或者Velocity的引擎,并将业务逻辑层中可以获取的数据和模板,使用引擎生成最终的内容
3) 将我上面的sample代码做简单封装后,调用,生成PDF
这样,我想作为一个web程序员来说,上面的3点,都不会成为你的绊脚石。你可以轻松驾驭PDF了。
在Flying Saucer的官方文档中,有一些Q&A,可以解决读者们大部分的问题。包括PDF的字体、PDF的格式、Image如何处理等等。大家可以尝试着去阅读。
还有一篇文章,好像是作者写的,非常不错:http://today.java.net/pub/a/today/2007/06/26/generating-pdfs-with-flying-saucer-and-itext.html
Freemarker+Flying sauser +Itext 整合生成PDF
Freemarker、Flying sauser 、Itext ,这三个框架的作用就不详细介绍了,google一下就知道了。
Itext提供了很多底层的API,让我们可以用java代码画一个pdf出来,但是很不灵活,布局渲染代码都hard code 进java类里面了。
当需求发生改变时,哪怕只需要更改一个属性名,我们都要重新修改那段代码,很不符合开放关闭的原则。想到用模版来做渲染,但自己实现起来比较繁琐,然后google了下,找到了用freemarker做模版,Flying sauser 照着模版做渲染,让Itext做输出生成PDF的方案。
freemarker和itext都比较熟悉了,Flying sauser 第一次听说,看完官方的user guide(http://flyingsaucerproject.github.com/flyingsaucer/r8/guide/users-guide-R8.html)后,自己着手做了个demo实践:

测试数据模型:
java代码:
1 package com.jeemiss.pdfsimple.entity; 2 3 public class User { 4 5 private String name; 6 private int age; 7 private int sex; 8 9 /** 10 * Constructor with all fields 11 * 12 * @param name 13 * @param age 14 * @param sex 15 */ 16 public User(String name, int age, int sex) { 17 super(); 18 this.name = name; 19 this.age = age; 20 this.sex = sex; 21 } 22 23 /////////////////////// getter and setter /////////////////////////////////////////// 24 25 public String getName() { 26 return name; 27 } 28 public void setName(String name) { 29 this.name = name; 30 } 31 public int getAge() { 32 return age; 33 } 34 public void setAge(int age) { 35 this.age = age; 36 } 37 public int getSex() { 38 return sex; 39 } 40 public void setSex(int sex) { 41 this.sex = sex; 42 } 43 }
java代码:
1 package com.jeemiss.pdfsimple.freemarker; 2 3 import freemarker.template.Configuration; 4 5 public class FreemarkerConfiguration { 6 7 private static Configuration config = null; 8 9 /** 10 * Static initialization. 11 * 12 * Initialize the configuration of Freemarker. 13 */ 14 static{ 15 config = new Configuration(); 16 config.setClassForTemplateLoading(FreemarkerConfiguration.class, "template"); 17 } 18 19 public static Configuration getConfiguation(){ 20 return config; 21 } 22 23 }
html生成器:
java代码:
1 package com.jeemiss.pdfsimple.generator; 2 3 import java.io.BufferedWriter; 4 import java.io.StringWriter; 5 import java.util.Map; 6 import com.jeemiss.pdfsimple.freemarker.FreemarkerConfiguration; 7 import freemarker.template.Configuration; 8 import freemarker.template.Template; 9 10 public class HtmlGenerator { 11 12 /** 13 * Generate html string. 14 * 15 * @param template the name of freemarker teamlate. 16 * @param variables the data of teamlate. 17 * @return htmlStr 18 * @throws Exception 19 */ 20 public static String generate(String template, Map<String,Object> variables) throws Exception{ 21 Configuration config = FreemarkerConfiguration.getConfiguation(); 22 Template tp = config.getTemplate(template); 23 StringWriter stringWriter = new StringWriter(); 24 BufferedWriter writer = new BufferedWriter(stringWriter); 25 tp.setEncoding("UTF-8"); 26 tp.process(variables, writer); 27 String htmlStr = stringWriter.toString(); 28 writer.flush(); 29 writer.close(); 30 return htmlStr; 31 } 32 33 }
pdf生成器:
java代码:
用来做测试的ftl模版,用到部分css3.0的属性来控制pdf强制分页和输出分页信息
html代码:
1 <html> 2 <head> 3 <title>${title}</title> 4 <style> 5 table { 6 width:100%;border:green dotted ;border-width:2 0 0 2 7 } 8 td { 9 border:green dotted;border-width:0 2 2 0 10 } 11 @page { 12 size: 8.5in 11in; 13 @bottom-center { 14 content: "page " counter(page) " of " counter(pages); 15 } 16 } 17 </style> 18 </head> 19 <body> 20 <h1>Just a blank page.</h1> 21 <div style="page-break-before:always;"> 22 <div align="center"> 23 <h1>${title}</h1> 24 </div> 25 <table> 26 <tr> 27 <td><b>Name</b></td> 28 <td><b>Age</b></td> 29 <td><b>Sex</b></td> 30 </tr> 31 <#list userList as user> 32 <tr> 33 <td>${user.name}</td> 34 <td>${user.age}</td> 35 <td> 36 <#if user.sex = 1> 37 male 38 <#else> 39 female 40 </#if> 41 </td> 42 </tr> 43 </#list> 44 </table> 45 </div> 46 </body> 47 </html>
最后写个测试用例看看:
java代码:
1 package com.jeemiss.pdfsimple.test; 2 3 import java.io.FileOutputStream; 4 import java.io.OutputStream; 5 import java.util.ArrayList; 6 import java.util.HashMap; 7 import java.util.List; 8 import java.util.Map; 9 import org.junit.Test; 10 import com.jeemiss.pdfsimple.entity.User; 11 import com.jeemiss.pdfsimple.generator.HtmlGenerator; 12 import com.jeemiss.pdfsimple.generator.PdfGenerator; 13 14 public class TestCase 15 { 16 @Test 17 public void generatePDF() { 18 try{ 19 String outputFile = "C:\\sample.pdf"; 20 Map<String,Object> variables = new HashMap<String,Object>(); 21 22 List<User> userList = new ArrayList<User>(); 23 24 User tom = new User("Tom",19,1); 25 User amy = new User("Amy",28,0); 26 User leo = new User("Leo",23,1); 27 28 userList.add(tom); 29 userList.add(amy); 30 userList.add(leo); 31 32 variables.put("title", "User List"); 33 variables.put("userList", userList); 34 35 String htmlStr = HtmlGenerator.generate("sample.ftl", variables); 36 37 OutputStream out = new FileOutputStream(outputFile); 38 PdfGenerator.generate(htmlStr, out); 39 40 }catch(Exception ex){ 41 ex.printStackTrace(); 42 } 43 44 } 45 }
到C盘下打开sample.pdf ,看看输出的结果:
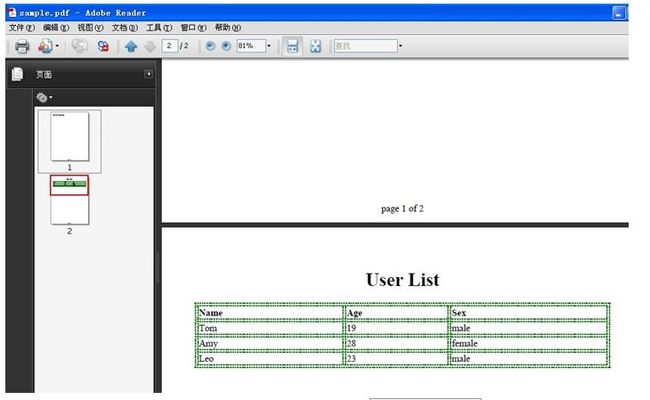
flying saucer 使用中的一些问题 (java导出pdf)
flying saucer(源代码托管在githubhttps://github.com/flyingsaucerproject/flyingsaucer)是java导出pdf的一种解决方案,最早是从downpour老大的文章里看到它:http://www.iteye.com/topic/509417 ,感觉比之前的iText好用许多,它可以解析css,即我将页面先设置好,然后传递给它,它既可以给我生成一个pdf出来,跟页面一样,当时感觉很酷,于是就研究了一下,现在项目中也用到了,效果还不错。
优点很明显,之前也提到了,可以解析css,这样很方便,大大的减少了工作量。pdf加水印也变得很简单——只需为body设置一个background-image即可。
说说使用中需要注意的一些问题吧:
[list=1]
- 中文换行问题
老外做的东西,没有考虑到中文问题。默认提供的包里,中文不会换行,有人修改了源代码,解决了这个问题,重新编译好的包在附件里,可以下载。需要注意的是,在官网提供的jar包里,有两个包,一个是core-renderer.jar,另一个是core-renderer-minimal.jar。引用时,只需引用前者就行。有人曾经说用这个重新编译后的包替换了原来的包之后,不起作用,原因就在此。中文换行包下载地址:http://community.csdn.net/detail/shanliangliuxing
另外,想要中文换行,如果是table,那么table 的style必须加上这句话html代码:
css路径问题
在一个java project里,使用相对css路径是可以的,效果也都不错。但在java web project里,使用css相对路径是不可以的(最起码这里困扰了我很久,差点就放弃flying saucer了)。例如,我有一个模板叫addOne.jsp,里面引用到了某个css,就应该这样写(windows)jHTML代码:
-
1 <link href="file:///D|/project/WebContent/commons/css/module-pdf.css" rel="stylesheet" type="text/css" />
-
只有这样写了之后,它才能找到这个css,很诡异。每次换了机器之后都要改路径,很麻烦。
- 中文字体问题
downpour老大在它那篇文章里提到了怎样处理中文字体的,他可能高估了许多人的水平。其实说起来,很简单,就两点:一是在java代码里引用字体,二是在页面上引用字体。 - 引用字体:
-
java代码: -
1 // 解决中文支持问题 2 ITextFontResolver fontResolver = renderer.getFontResolver(); 3 fontResolver.addFont("C:/Windows/Fonts/arialuni.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
这里引用了arialuni.ttf字体,它位于C盘windows/fonts文件夹下,将它引用后,还需要在页面上使用这个字体
html代码:
这里的Arial Unicode MS 即刚才 的arialuni.ttf字体的名字,换了其它字体后要注意修改这里的名称。这样才可以在pdf中显示中文。
许多人有这样一个问题——按照以上两个步骤做了之后,页面中还是没有中文,这时,请检查你引用的css文件,其中一定设置了其它字体,只需将它去掉即可
缺点:
我在使用中发现,flying saucer不支持富文本,如果用到了KindEditor此类富文本编辑器,
还要将其中的内容转化成pdf,那对flying saucer来说就是个灾难。会报一堆错误,目前我还没有找到解决方案。还好这次项目中不是必须使用富文本编辑器,对于有此类需求的同学来说,请慎重选择flying saucer。另外,flying saucer严格遵守html规则,一个小小的错误,都会导致它报错。诸如
html代码:
此类的html代码在jsp中是不会有问题的,可是flying saucer却会报错,曾经这个问题导致我花了一小时时间来寻找问题所在。不过很难说这到底是缺点还是优点
最后贴一个较完整的例子:
我使用spring mvc,在controller里
java代码:
1 @RequestMapping("/pdf/{projectId}") 2 public ModelAndView generatePdf(HttpServletRequest request, 3 HttpServletResponse response, @PathVariable 4 String projectId) { 5 Project project = this.projectService.getProjectById(projectId); 6 ModelAndView mav = new ModelAndView(); 7 if (project == null) { 8 mav.setViewName("forward:/error/page-not-found"); 9 return mav; 10 } 11 //中文需转义 12 String pdfName = "pdfName"; 13 14 response.setHeader("Content-disposition", "attachment;filename="+pdfName; 15 response.setContentType("application/pdf"); 16 OutputStream os = response.getOutputStream(); 17 ITextRenderer renderer = new ITextRenderer(); 18 //指定模板地址 19 renderer.setDocument("http://localhost/project/preview/"+projectId); 20 21 ITextFontResolver fontResolver = renderer.getFontResolver(); 22 if (StringUtils.isOSWindow()) 23 fontResolver.addFont("C:/Windows/Fonts/ARIALUNI.TTF", 24 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 25 else 26 fontResolver.addFont("/usr/share/fonts/TTF/ARIALUNI.TTF", 27 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 28 renderer.layout(); 29 renderer.createPDF(os); 30 os.close(); 31 32 return null; 33 } 34 35 @RequestMapping("/preview/{projectId}") 36 public ModelAndView pdf(@PathVariable 37 String projectId) { 38 Project project = this.projectService.getProjectById(projectId); 39 ModelAndView mav = new ModelAndView(); 40 if (project == null) { 41 mav.setViewName("forward:/error/page-not-found"); 42 return mav; 43 } 44 mav.setViewName("pdf"); 45 mav.addObject("project",project); 46 return mav; 47 }
jsp页面如下
html代码:
1 @RequestMapping("/pdf/{projectId}") 2 public ModelAndView generatePdf(HttpServletRequest request, 3 HttpServletResponse response, @PathVariable 4 String projectId) { 5 Project project = this.projectService.getProjectById(projectId); 6 ModelAndView mav = new ModelAndView(); 7 if (project == null) { 8 mav.setViewName("forward:/error/page-not-found"); 9 return mav; 10 } 11 //中文需转义 12 String pdfName = "pdfName"; 13 14 response.setHeader("Content-disposition", "attachment;filename="+pdfName; 15 response.setContentType("application/pdf"); 16 OutputStream os = response.getOutputStream(); 17 ITextRenderer renderer = new ITextRenderer(); 18 //指定模板地址 19 renderer.setDocument("http://localhost/project/preview/"+projectId); 20 21 ITextFontResolver fontResolver = renderer.getFontResolver(); 22 if (StringUtils.isOSWindow()) 23 fontResolver.addFont("C:/Windows/Fonts/ARIALUNI.TTF", 24 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 25 else 26 fontResolver.addFont("/usr/share/fonts/TTF/ARIALUNI.TTF", 27 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); 28 renderer.layout(); 29 renderer.createPDF(os); 30 os.close(); 31 32 return null; 33 } 34 35 @RequestMapping("/preview/{projectId}") 36 public ModelAndView pdf(@PathVariable 37 String projectId) { 38 Project project = this.projectService.getProjectById(projectId); 39 ModelAndView mav = new ModelAndView(); 40 if (project == null) { 41 mav.setViewName("forward:/error/page-not-found"); 42 return mav; 43 } 44 mav.setViewName("pdf"); 45 mav.addObject("project",project); 46 return mav; 47 }
使用flyingsaucer将网页转换为pdf之中文问题彻底解决
前几天遇到个导出pdf的需求,在网络上查找了一下java导出pdf的方案.多数人推荐使用iText,研究了一下,感觉直接写pdf的方法太笨,可维护性差,一旦pdf格式要变化改起来很费劲.还有一个方案,可以先预先定义一个pdf作为模板文件,然后用业务数据进行填空.是个不错的方案,只可惜不适合我的需求.需求中有些行是动态加行的,这个方案无法实现.后来发现有可以将网页直接转成pdf的开源包flyingsaucer(中文名:灰碟),逐将注意力转移到这上面,发现是个不错的选择.只要写网页就可以了,而且pdf格式变化维护起来也方便,代码也会比较干净.只是它对中文支持的不好,但这不是无法解决的.下面就来说说这个flyingsaucer.
java代码:
改成:
java代码:
1 try { 2 cb.setFontAndSize(BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED), _font.getSize2D()/_dotsPerPoint); 3 } catch (Exception e) { 4 }
Ok,改了以后我们终于可以看到pdf里有中文了.但是别高兴的太早哦,问题并没有完全解决.如果一段标签中有且只有中文字符的时候,导出pdf后内容便会消失.比如<div>中文</div>,这样的代码将什么也输出不了,而<div>中文a</div>则会将标签内容全部输出.通过测试我们发现,纯中文是无法输出的,但是加上一点点英文、数字或符号就可以输出了.有同学可能要说我们把纯中文后面加上空格不就行了?我只能说很不幸,加空格是不管用的.如果你的页面上纯中文的地方可以随便让你加字母/数字/符号,那可以不必往下看了.但是我觉得大多数的人恐怕不会这么干的,即使我们想客户也不让啊.那就要解决这个问题.
java代码:
于是我照做了.杯具的是情况没有任何好转.即使有好转这个绝对路径的字体引入方式也很让人不舒服吧.所以这个不是我们想要的解决方案.
java代码:
java代码:
-
1 ·········10········20········30········40········50········60········70········80········90········100·······110·······120·······130·······140·······15001.if (char1 < 128 || (char1 >= 160 && char1 <= 255)) 2 02. total += widths[char1]; 3 03.else if ((char1 >= 19968) && (char1 <= 40869)) // 如果是中文字符加宽度500 4 04. total += 500; 5 05.else 6 06. total += widths[PdfEncodings.winansi.get(char1)];
再次测试,通过.至此,使用flyingsaucer将网页导出成pdf的中文问题总算解决了.可是总觉得这个解决的方法有点不太正宗,因为修改了父类嘛.但又没有找到其他正宗的解决方案,只能先这样解决一下了.发出此文,只当抛砖引玉,如果有哪位高人有更好的解决方案请不吝赐教啊.
附件提供修改了的flyingsaucer-R8的两个jar包: core-renderer.jar和iText2.0.8.jar另有一个iText亚洲语言包.
下载修改源码后的jar包地址:http://download.csdn.net/detail/shanliangliuxing/3640286
下面是我自己利用flying saucer技术生成pdf文档的实现代码:
Servlet方式:
html代码:
java代码:
Struts1形式:
html代码:
java代码:
1 public void viewExportPDF(ActionMapping mapping, ActionForm form, 2 HttpServletRequest request, HttpServletResponse response) 3 throws Exception { 4 ServletContext sc = request.getSession().getServletContext(); 5 String rootpath = sc.getRealPath(""); //值为D:\apache-tomcat-6.0.26\webapps\webmonitor 6 //把路径中的反斜杠转成正斜杠 7 rootpath = rootpath.replaceAll("\\\\", "/"); //值为D:/apache-tomcat-6.0.26/webapps/webmonitor 8 //临时存储目录 9 String pdfPathName = rootpath + "/WebReport.pdf"; 10 ArrayList<String> list = new ArrayList<String>(); 11 for(int i=0;i<outstreamlist.size();i++) { 12 list.add(outstreamlist.get(i)); 13 } 14 //调用方法 15 boolean flag = createPdf(list, pdfPathName, request, response); 16 if (flag == true) { 17 //要实现另存为下载,必须满足两个条件:导入commons-upload.jar包,表单提交 18 try { 19 OutputStream out = response.getOutputStream(); 20 byte by[] = new byte[1024]; 21 File fileLoad = new File(pdfPathName); 22 response.reset(); 23 response.setContentType("application/pdf"); 24 response.setHeader("Content-Disposition", 25 "attachment; filename=WebReport.pdf"); 26 long fileLength = fileLoad.length(); 27 String length1 = String.valueOf(fileLength); 28 response.setHeader("Content_Length", length1); 29 FileInputStream in = new FileInputStream(fileLoad); 30 int n; 31 while ((n = in.read(by)) != -1) { 32 out.write(by, 0, n); 33 } 34 in.close(); 35 out.flush(); 36 37 } catch(Exception e) { 38 e.printStackTrace(); 39 } 40 } else { 41 renderText(response, ERR_MESSAGE); 42 } 43 return ; 44 45 } 46 47 //生成pdf 48 public boolean createPdf(ArrayList<String> list, String pdfPathName, 49 HttpServletRequest request, HttpServletResponse response) 50 throws Exception { 51 52 /** 53 * 用rootpath指定目录也可以生成pdf文件,只不过不能在myeclipse的左边导航窗口中看不到而已 54 * 左边导航窗口对应C盘目录下的workspace目录下程序 55 * 用rootpath指定的目录是D盘Tomcat目录 56 */ 57 ServletContext sc = request.getSession().getServletContext(); 58 String rootpath = sc.getRealPath(""); //值为D:\apache-tomcat-6.0.26\webapps\webmonitor 59 //把路径中的反斜杠转成正斜杠 60 rootpath = rootpath.replaceAll("\\\\", "/"); //值为D:/apache-tomcat-6.0.26/webapps/webmonitor 61 62 boolean flag = false; 63 String outputFile = pdfPathName; 64 //指定目录导出文件 65 OutputStream os = new FileOutputStream(outputFile); 66 ITextRenderer renderer = new ITextRenderer(); 67 StringBuffer html = new StringBuffer(); 68 //组装成符合W3C标准的html文件,否则不能正确解析 69 html.append("<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\" \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">"); 70 html.append("<html xmlns=\"http://www.w3.org/1999/xhtml\">") 71 .append("<head>") 72 .append("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\" />") 73 .append("<style type=\"text/css\" mce_bogus=\"1\">body {font-family: SimSun;}</style>") 74 .append("<style type=\"text/css\">img {width: 500px;}</style>") 75 .append("<style type=\"text/css\">table {font-size:13px;}</style>") 76 .append("</head>") 77 .append("<body>"); 78 html.append("<center>"); 79 html.append("<h1>统计报表</h1>"); 80 for(int i=0;i<list.size();i++) { 81 html.append("<div>" + list.get(i) + "</div>"); 82 } 83 html.append("</center>"); 84 html.append("</body></html>"); 85 try { 86 renderer.setDocumentFromString(html.toString()); 87 // 解决图片的相对路径问题,图片路径必须以file开头 88 renderer.getSharedContext().setBaseURL("file:/" + rootpath); 89 renderer.layout(); 90 renderer.createPDF(os); 91 os.close(); 92 flag = true; 93 } catch (Exception e) { 94 flag = false; 95 e.printStackTrace(); 96 } 97 return flag; 98 }
原文地址:http://blog.csdn.net/shanliangliuxing/article/details/6833471