(四)训练用于口罩检测的YOLOv5模型
目录
介绍
准备训练和验证数据
在Colab Notebook上训练YOLOv5模型
在Google Colab上测试模型
下一步
在这里,我们将训练和测试用于口罩检测的YOLOv5模型。
介绍
在本系列的上一篇文章中,我们标记了一个口罩数据集。现在是该项目最激动人心的部分——模型训练。
准备训练和验证数据
与其他任何模型一样,YOLOv5需要一些验证数据来确定训练过程中和训练后推论的质量。这就是为什么我们需要将图像集分为带有相应的.txt文件的train和val数据集。通常,训练比例分配率为80%,验证比例分配率为20%,并且分配比例必须如下分配:
Dataset
|
| -- images
| | -- train
| | -- val
|
| -- labels
| | -- train
| | -- val
|
| -- dataset.yaml我手动分割数据;我将前3,829张图像放置在images/train目录中,将其余955张放置在images/val目录中。然后,我将相应的.txt文件复制到相应的label/train和labels/val中。
该dataset.yaml文件告诉模型数据集是如何分布的,有多少个类别的,他们的名字是什么。在我们的例子中,文件的外观如下:

这些功能是:
- 第1行表示训练图像集的相对路径
- 第2行指示验证集的相对路径
- 第6行指出数据集包含多少个类
- 第9行定义每个类的名称
每次训练YOLOv5模型时,都必须手动创建此文件。幸运的是,这不是一个复杂的任务。
在Colab Notebook上训练YOLOv5模型
我们不会将您的本地计算机推到极限,因为那里有多种云计算选项。让我们使用一个非常强大且易于使用的解决方案Google Colab Notebook。
在继续之前,我需要提到一些重要的事情。YOLOv5模型在PyTorch之上运行,PyTorch是一个ML框架,需要太多的计算资源才能在小型设备上运行。有个变通办法,请听我说。
YOLOv5和其他YOLO版本都是由Ultralytics开发的,它维护一个Git repo,您可以在其中获取使用这些模型所需的所有文件。即使它是官方的存储库,它仍然缺少一些重要的改进。一些重要的功能将会在2021年初加入。该存储库将包含将PyTorch自定义模型转换为TensorFlow和TensorFlow Lite兼容版本所需的函数。当谈到CPU/内存受限的设备上的ML时,最后一种被认为是最优的解决方案。
上述改进是由Ultralytics的重要贡献者开发的,可在此存储库中找到。这是我们将在本项目中使用的这个库。采用此路径的原因是,Ultralytics管道中没有明确定义当前的PyTorch – TensorFlow Lite转换。您将需要将.pt文件手动转换为.onnx,然后获取TensorFlow权重才能最终将其转换为TensorFlow Lite权重。在过程的中间很容易出错,并使生成的模型不稳定。
好吧,让我们开始吧!喝杯咖啡,然后启动您的Google Colab Notebook(我的在这里)。
让我们从设置GPU实例类型开始。
首先,在屏幕顶部的菜单中,选择“编辑” >“Notebook设置” >“GPU”,并确保将“硬件加速器”设置为GPU。
接下来,选择“运行时” >“更改运行时类型” >“硬件加速器” >“GPU”。必须选择两个下拉列表,如下所示:
您的Notebook将需要一些时间来初始化——请等待几分钟。
Notebook计算机启动并运行后,请设置初始配置:
import torch # Keep in mind that YOLOv5 runs on top of PyTorch, so we need to import it to the notebook
from IPython.display import Image #this is to render predictions
#!git clone https://github.com/ultralytics/yolov5 # Use this if you want to keep the official Ultralytics scripts.
!git clone https://github.com/zldrobit/yolov5.git
%cd yolov5
!git checkout tf-android上面的代码行将导入基本库,将包含该模型的YOLOv5存储库以及PyTorch-TensorFlow Lite转换所需的关键文件克隆到/content目录。
下一步是安装一些必需的组件并更新当前Notebook的TensorFlow版本:
!pip install -r requirements.txt
!pip install tensorflow==2.3.1 #Keep this version of TF as YOLOv5 works well with it.
print('All set. Using PyTorch version %s with %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))让我们将口罩数据集导入到Notebook中。我已经将其上传到github,所以运行以下几行:
%cd /content
!git clone https://github.com/sergiovirahonda/FaceMaskDataset克隆完所有文件后,您需要将数据集的dataset.yaml文件移动到/content/yolov5/data目录。使用左侧的文件浏览器,然后将文件从/content/FaceMaskDataset手动拖动到/content/yolov5/data。如前所述,此文件包含YOLO所需的信息,以在自定义数据上训练模型。如果要检查文件,请运行以下命令:
%cd /content
!git clone https://github.com/sergiovirahonda/FaceMaskDataset现在是时候在自定义数据上训练模型了。首先,导航到train.py文件所在的/yolov5目录。实施脚本时,请牢记以下注意事项:
- 您必须以像素为单位指示图像尺寸(在本例中为415)。该模型会将每个图像的步幅扩展到416像素,因为415并非预定义的最大步幅32的倍数。
- 指示批次大小。在这种情况下,我们将其保持在16。
- 您必须指出纪元数。纪元数越大,置信度越高。过度拟合可能会在某个时候发生,如果数据集相对较小,它将很快发生。现在30个纪元就足够了,否则您会发现有些过度拟合。
- 通过--data参数,您引用包含数据集配置的.yaml文件。
- 您需要为训练管道指定预训练模型才能使用。请记住,可用的选项是YOLOv5s(yolov5s)、YOLOv5m(yolov5m)、YOLOv5l(yolov5l)和YOLOv5x(yolov5x)。在我们的案例中,第一个选择是最好的,因为我们需要一个非常轻便的模型。
- 最后,--nosave仅用于保存最终检查点,--cache使管道能够缓存图像以减少训练时间。我也想保持最佳指标,因此我不会使用--nosave。
在训练过程中,要了解其运行状况,请留意[email protected]指标(平均平均精度)。如果接近1,该模型将取得出色的效果!
要训练模型,请运行以下命令:
%cd /yolov5
!python train.py --img 415 --batch 16 --epochs 30 --data dataset.yaml --weights yolov5s.pt --cache上面几行对我们的数据集执行基本检查,缓存图像,并覆盖其他配置。他们输出一个模型体系结构摘要(检查一下以了解模型是由什么组成的),然后开始训练。
在训练结束后,两个文件应该被保存在/content/yolov5/runs/train/exp/weights:last.pt和best.pt。我们将使用best.pt。
如果您想探索训练期间记录的指标,建议您使用TensorBoard,这是一种非常互动的探索工具:
%load_ext tensorboard
%tensorboard --logdir runs这将加载如下内容:
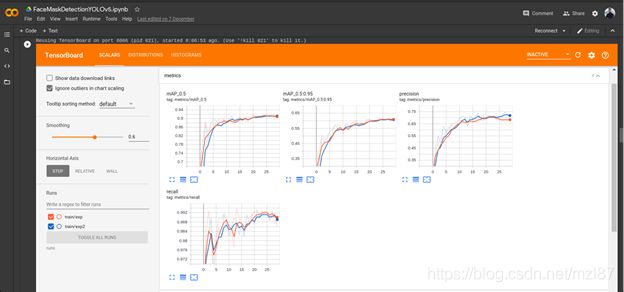
请注意,在25个纪元后,mAP和精度如何达到最大值。这就是为什么将模型训练超过30个纪元没有意义的原因。
在Google Colab上测试模型
现在让我们探讨一下我们的模型有多自信。我们可以绘制训练期间获得的验证批次,并检查每个标签的置信度得分:
Image(filename='runs/train/exp/test_batch0_pred.jpg', width=1000)这将绘制以下内容:
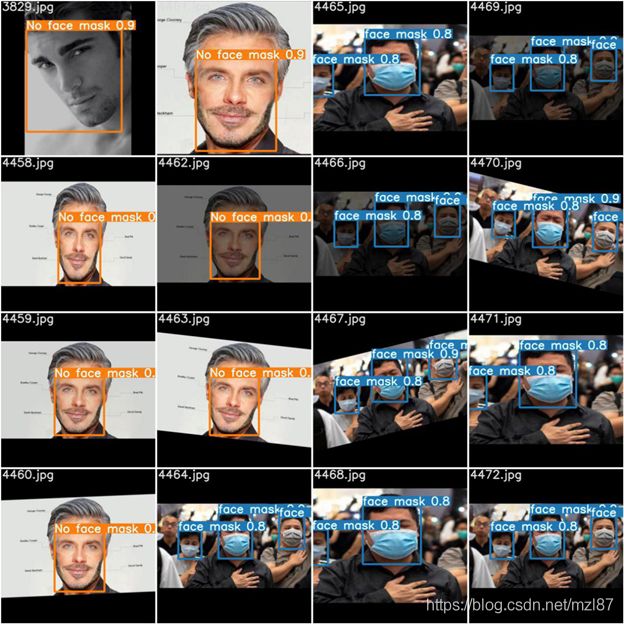
尽管0.8不是一个很好的分数,但是在这些类型的模型中它仍然不错。请记住,YOLOv5牺牲了检测速度的准确性。
我们现在有一个训练有素的模型。要在看不见的新图像上对其进行测试,请手动创建一个新目录(例如/content/test_images),上传一些图像,然后运行以下代码:
%load_ext tensorboard
%tensorboard --logdir runs您将以best.pt权重和416x416像素的图像尺寸来实现detect.py脚本(遵守该规则非常重要)。结果将保存到run/detect/exp。要显示结果,请运行以下代码:
#Plotting the first image
Image(filename='runs/detect/exp/testimage1.jpg', width=415)结果:

看起来很有前途,你不觉得吗?
下一步
在接下来的文章中,我们将让我们的模型理解的TensorFlow精简版,TensorFlow的轻量级版本专门开发小型设备上运行。敬请关注!
https://www.codeproject.com/Articles/5293074/Training-a-YOLOv5-Model-for-Face-Mask-Detection