io_uring 用法分析 II :io_uring 原理和系统调用初步介绍
这个为了方便,之后还要总结一下这个全部的用法摘要,方便查阅。所以分为 3 篇内容(其实前面还有一篇讲异步 IO 的也算吧io_uring 用法分析 I :异步 IO ,Windows IOCP 接口与 Proactor 模式_我说我谁呢 --CSDN博客),第一个是 io_uring 的简单原理分析和 raw interfaces,第二篇是讲 liburing 以及高性能 polling 机制,第三篇是接口以及各选项的总结摘要(这个还没写好之前先参考 manual 和 liburing 的头文件吧,liburing 也自带了 system call 的 manual)。
前情提要
读者应该具备 IO 模型的基础。
对于什么是异步 IO 同步 IO 这个之前我有一个笔记:基础服务器 IO 模型 Proactor 模型 Reactor 模型 IO 多路复用 异步 IO 模型 Linux 服务器开发 网络编程服务器模型_我说我谁呢 --CSDN博客

从 2019 开始 Linux kernel 5.1 引入了 io_uring 取代了之前拉跨的各种 aio,并且 5.3 开始 io_uring 支持 socket api 了,看了一下自己的 Ubuntu kernel 版本已经是 5.13 了。
如果 io_uring 性能真的像各种中英文资料的测试那样和 epoll 比以及和旧的 aio 比都有至少 10 %的提升的话,那么说Proactor 以及在 Reactor 里面用上异步 IO 的好日子来了。
在此之前,各种网络库使用的异步 IO 模型一般比较出名的是 Windows 下的 IOCP,比如 nginx 和 boost 的 asio 库,在 windows 平台下的高性能保障都是通过 IOCP 实现的。对于 IOCP 这个可以在 MSDN 找到。
第一篇笔记就是对 Linux 以前的异步 IO 以及 windows 的 IOCP 的介绍:io_uring 用法分析 I :异步 IO ,Windows IOCP 接口与 Proactor 模式_我说我谁呢 --CSDN博客
主要的 io_uring 的资料有这些:io_uring.pdf (kernel.dk) ,作者 Axboe 的整一系列的设计详细细节看这个邮件列表:[PATCHSET v5] io_uring IO interface - Jens Axboe (kernel.org),LWN 的新闻(评论区也有好看的):Ringing in a new asynchronous I/O API [LWN.net],
中文内容,比较完整的有这个:
《操作系统与存储:解析Linux内核全新异步IO引擎——io_uring设计与实现》(一) - 知乎 (zhihu.com)(文章的主要内容也还是根据 io_uring.pdf (kernel.dk) 的个人理解配一些源码上的分析。结果看到一半还是有些不明白的地方直接看 pdf 了,作为补充吧)。
本来想先看了这个再去看原来的 pdf。还有这个讲接口的文章 一篇文章带你读懂 io_uring 的接口与实现 - 知乎 (zhihu.com)。结果还是回去看 pdf 了,因为作者二三手信息的确有个人的理解和上下文,导致可能别人看不懂。下面的内容为了简要而且摘录源码不如直接看能搜索和跳转,所以涉及源码部分的配合源码看吧。
然后 manual 目前系统都没有更新,liburing 里面自带了 manual,附上 arch 的 manual page 连接方便查阅好了:io_uring(7) — Arch manual pages (archlinux.org)。
为了简要下面就不贴接口和函数签名以及源码 io_uring.c - fs/io_uring.c - Linux source code (v5.12.10) - Bootlin 了,对照着看吧。
以前的 IO
首先是 write read 的一个问题,由于硬是把 offset 放在文件里面,结果是多线程无法读取多个 offset (线程共享 fd)。于是搞出了 pread pwrite。由于有时候需要分散读写多个 offset 段落 ( DB 尤其) 所以引发了 readv 和 writev 用来一次提交多个区间读写,而避免引发多次 syscall (特别是 meltdown & spectre 之后)。当然,各种要求的排列组合也要做,于是做了 preadv pwritev。结果这两个没有做 flag,于是后来又补上了 flag 的版本 preadv2 pwritev2. (真的太离谱了,为什么不一次就做好他呢!只能说是不断实践才能指导好设计)。
Linux 原生 AIO 的引入,然而 AIO 有问题,对于 IO 提交必须涉及相关结构体的 copyin copyout,实现不支持 buffer 要 O_DIRECT(对硬盘来说反而更慢了),还有系统调用开销(submit + wait),只能说他的实现不靠谱,网络库就没有用 aio 的,boost 的 asio 是 epoll 用户态模拟 proactor。
io_uring 的队列与实现
了解了 window 下的 IOCP 接口和 Proactor 模式之后应该大致知道异步 IO 最主要提供的功能就是异步 IO 多路复用器,即 windows IOCP 的 GetQueuedCompletionStatus 等同于 epoll (epoll 是同步 IO 多路复用器),即一个是等待感兴趣事件就绪,一个是等待委托办理事件的完成。
下面的内容对照源码阅读:io_uring.c - fs/io_uring.c - Linux source code (v5.12.10) - Bootlin , io_uring.h - include/uapi/linux/io_uring.h - Linux source code (v5.12.10) - Bootlin。链接全部其在源码对应的链接指向行数(结构体定义在头文件),也可以用搜索的方法定位。
epoll 的实现尽管高效了,但是他的对于 ready 的描述符的数据结构传递还是要拷贝一次内存,如果能用内存映射来做就能减少很多拷贝了。这次提出通过映射一块内存来做 ring buffer ,这样的话就减少了内存复制的开销。当然实现要进行一些只读只写的限制。结构体 io_ring 管理一个 q 只需要一个 head 和一个 tail (内核是 Submit Q 的 head + Completion Q 的 tail)。 io_rings 结构体里面就有一个 sq 和一个 cq (两个 q 很容易理解,结构体 io_uring 的两个成员就是 head 和 tail ),柔性数组是 cqe (completion queue entries 的意思)通过 mmap 分享。
struct io_uring_sqe 的成员很复杂,因为要精准地描述一个请求,也支持了前面说的向量读,这样是集大成了,免得后期还要改。这个东西在哪里稍后再讲。
然后是 cqe 的成员只有三个,一个是 data 指针 passed back,一个是返回结果 res (等同于直接调用同步 read write 的结果),一个是标记位。
下面这里说的这些结构体是实现的文件内定义结构体(在 c 文件不在头文件),外面是看不到的,所以看到 liburing 的时候可能会有一些同名的结构体。问题不大。
前面说了 io_rings 结构体里面有 cqes 柔性数组 而没有 sqes,然后又有 sq 和 sq ,他实际是内存的承载体,实际使用肯定还是要用一个结构体来管理实际的对象的,因为一个(io_rings)是数组载体定义,一个是上下文信息(io_ring_ctx)。总之这个结构体肯定是能访问到全部的 cqe 和 sqe 的(因为他有 head 和 tail 索引)。
所以还有 io_ring_ctx (context) 结构体,这个东西就很复杂了,里面包括了各种成员,各种给系统调用提供的钩子(比如侵入式链表指针),当然还有一个 io_rings 指针和一个 sqe 结构体的指针(sqe 为什么不用整个载体呢?这个其实是为了减少系统调用的,因为 sq 是引发系统调用的入口,所以这里做了一个 indirection(有两个数组指针),具体之后再讲)。
io_uring 的系统调用 (对照 manual)
有三个系统调用(系统调用一般是汇编语句由语言库提供,函数签名看 manual 就行了,不过这里应该和源码的签名一致),分别负责准备,提交和收割,高级的固定 sqe 用法。他们三个都是 io_uring 前缀:分别是 setup,enter 和 register(这个要最后才讲到)。
首先是 mmap 的指定,很前面提到 epoll 的那个如果用 mmap 做就好了,这次真的实现了,然后之前讲了 sqe 的结构体里面有两个数组指针,实际是用来实现批处理的,而 cqe 是直接在结构体上定义的,这个是为了提供一个非连续队列的功能。(这里写的有点不清楚,下面会具体讲原因,第一个知乎链接 里面那个 cqes 内容 和 sqes 内容 都指向 SQE 的图片应该是错的,只有 sqes 的内容是间接索引)。
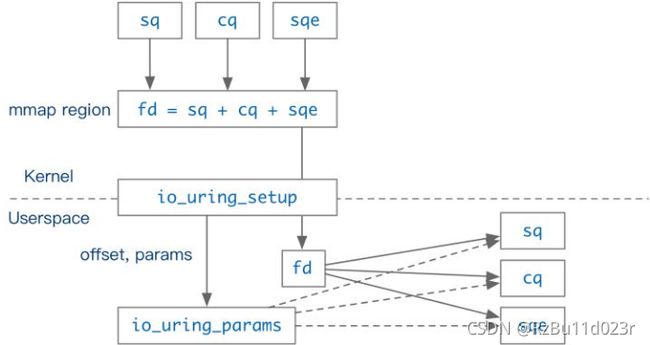
先看 setup 的函数,两个参数,一个是数量,一个是参数-值传递的结构体。函数会返回一个 fd。这个 fd 是为了给应用层 mmap,因为 mmap 只能通过 map fd 实现,也是一种 convention 了,避免引入更多的使用复杂性,这个是这次做 io_uring 的设计目标。而具体的结构体就要从返回值里面选 offset 去进行 mmap 。 下文会具体介绍怎么做这个 offset 的计算(获取)。(图是迟用户的文章的)
至于这个 sqe 为什么要自己搞一套是提供一个 indirection 这个时候我还没搞明白,但是根据根据 io_uring 作者 Axboe 的提交邮件的说明有一个用途(第二个下面会讲):[PATCH 3/3] io_uring: add support for sqe links - Jens Axboe (kernel.org):
With SQE links, we can create chains of dependent SQEs. One example would be queueing an SQE that's a read from one file descriptor, with the linked SQE being a write to another with the same set of buffers.
这个做法的好处是可以让一个 SQE 出现在不同的请求队列中(一个读一个写)而不用重复生成 SQE (毕竟 SQE 是非常复杂的一个结构体)。而这个是在 [PATCHSET 0/3] io_uring: support for linked SQEs - Jens Axboe (kernel.org) 这个之后引入的,这个的 作用是提供了一个 barrier operation,能够进行有依赖关系的单个读写请求(即 SQE),这个功能在比如复制上会有用:
We currently support a barrier operation, which ensures that previous commands have finished before they are executed. This patchset introduces support for linked commands. Linked commands form a dependency between commands, but not for the execution pipeline in
general. Example:
[[ ReadA, WriteA], [ReadB, WriteB], [ReadC, WriteC]]
This is a weak ascii attempt at showing a series of reads and writes, where each write depends on the previous read. WriteA will not be started before ReadA is complete. Think of a copy like operation, where ReadA is "read X bytes from file Y at offset Z" and WriteB is then "write X bytes to file A at offset B", with the two sharing the same iovec. While WriteA depends on the completion of ReadA, there are no dependencies between ReadA and ReadB, and they may execute in parallel.
下面开始直接看 pdf 的内容做笔记了(基本是人肉翻译和摘抄而已,要是英语敏感不如直接看 pdf 了):
为什么 SQE 要间接索引
首先是 cqe 和 sqe 的寻址机制是不一样的。cqe 完全就是连续数组做的循环队列,这个队列的目标是让kernel 和应用都能看和修改(其实还是指通过队列的接口方式访问)。为了求模不用除法,很自然地规定了队列 长度是 2 的幂。
对 sqe 来说,角色反过来,是应用 update kernel consumes (and update),这一引入了一个 indirection。Some applications may embed request units inside internal data structures, and this allows them the flexibility to do so while retaining the ability to submit multiple sqes in one operation. That in turns allows for easier conversion of said applications to the io_uring interface. 这个说法我想了很久都不明白,io - Why does io_uring have a layer of indirection for the submission queue? - Unix & Linux Stack Exchange 后来找到这个说明,总算明白了。其实就是说有些应用可能会总是需要进行一些 IO 的,这样的话每次都要进行一堆数据的填写(sqe 的数据特别多)然后提交,这样不如直接划分几个 slot 给他,让他占有他们,这样更方便一点。(只能说我编程经验还不够)。
使用 mmap 获取结构体概述
然后 mmap 的对应结构体在 io_uring 的 fd offset 也提供好了(避免冲突吧其实主要目的)
这些灰底图来自 PPT

这样 mmap 的整个过程是这样的(只举例了 sq 的,而 cq 的话参考类似):


讲解一下,mmap 给 sq_ring 的 fd length 自然就是整个 sqring 数组(sq ring 是一串 indirect index )啊。如果 map cq ring 的话计算会复杂一些。
然后是 enter 调用,enter 这个 system call 做的是告诉 kernel 提交了一些请求。(这个是可以批处理的)。
unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t sig
这些参数的内容分别是 uring fd,提交的请求数量,要求唤醒的时候至少要完成这么多才通知上层。 flags 有一个必须提交的如果想要阻塞:IORING_ENTER_GETEVENTS 如果要使用 min_complete 并且进行等待的话。理论上 min 设置 0 不就是 non-blocking 了吗? pdf 说有例外情况所以必须这样设置。
Raw API 的总结
总结一下这部分的内容(PPT 搬运):
- io_uring_setup(2) will create an io_uring instance of the given size.
- With that setup, the application can start filling in sqes and submitting them with io_uring_enter(2) .
- Completions can be waited for with the same call, or they can be done separately at a later time.
- Unless the application wants to wait for completions to come in, it can also just check the cq ring tail for availability of any events.
- The kernel will modify CQ ring tail directly, hence completions can be consumed by the application without necessarily having to call io_uring_enter(2) with IORING_ENTER_GETEVENTS set.
IO 请求选项
下面是一些 sqe 的 flag。
manual SQE 的 flag
Drain 的意义,之前看别的文章看到 drain 的 flag 大致知道强制同步的意思,但是的确没想到是用来实现带依赖的读写。(full pipeline barrier)。然后 linked sqes 这个前面也讲了。
IORING 的 OP 有一个 timeout,这个是用来控制等待 completion 的超时的。
内存屏障
对于内存 barrier
If you're happy using the simplified io_uring API exposed through the liburing library, then you can safely
ignore this section and skip to the liburing library section instead. If you have an interest in using the raw interface,
understanding this section is important.
实际这个内容很容易理解的,就是之前学这个一致性和 reorder 的时候读写的重排序问题,内存屏障对于多核的分析我专门写了一篇笔记。这里补充一下单核的情况,首先是 CPU 才不管你什么 context switch 的,他只看到一堆指令。。。。
失败了,我不理解。 load store 指令都是用物理地址缓存下来的,tomasulo 最后根据时序和依赖性发射或者分支预测抛弃。然后复习一下之前分析 TLB 和 Cache ,他们是同步查(因为低地址是一样的)的,然后比对失败才进行 Cache 重载的。但是google 了一下发现实际指令到了 tomasulo dock 再到 store buffer 的时候会有 both Physical Addr 和 Virtual A(因为 VA 要用来流水线里 fast forwarding 解决部分的读写依赖问题,差点忘了这)。那么 context switch 了,TLB flushes 之后,地址空间完全不一样的,所有的物理地址都没用的,难道不应该 flush 整个 load buffer 和 store buffer 吗?这下有点迷糊了。
Wikipedia 说:In 2008, both Intel (Nehalem)[24] and AMD (SVM)[25] have introduced tags as part of the TLB entry and dedicated hardware that checks the tag during lookup. Even though these are not fully exploited[needs update?], it is envisioned[by whom?] that in the future[when?]。如果这个是真的的话,那么就神奇了,这样的确可以解释必须做 memory barrier。最后我的答案是这个东西过于复杂,是 implementation define 的,没有办法深究了,毕竟有些超强内存模型的 CPU 里 barrier 的编译指令可能就是 NOP,但是这个工作是必须要做的,没办法了属于。故事再一次告诉我不要去猜任何东西,看不到实现(在具备足够的资料和知识之前)之前任何推敲和思想实验都不靠谱(这里这些东西想的应该都是错的我感觉)。
总之要保证更新队列的头尾指针的时候需要做以下内存读写屏障。
继续看吧,还差 register 系统调用和 lib 没看完
在内核中保留固定的文件描述符
首先是 register 系统调用,这个是用来提前注册一系列文件读写的(因为对于具体实现是环形队列每次提交 fd 以及操作,这些 fd 需要让内核 maintain 一份,但是异步 IO 完成之后又要丢掉,这些操作都要 atomic 实现,所以如果要频繁对同一个文件 IO 的话,可以保留一个 fd 实例而不是每次抹去又建回来)。
unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args
通过 IORING_REGISTER_FILES 来注册 fds,然后这样的话 arg 就是传一个 fd 数组了。然后要用这些 fd 的话以后要这样提交 sqe:使用 IOSQE_FIXED_FILE,然后 fd 就不再用真实的 fd 了,而是用这个 fd 数组的 indirect 索引。当然如果不想浪费资源也可以之后手动清理:use IORING_UNREGISTER_FILES in the opcode for io_uring_register(2) 。
总结
到这里讲完了系统调用的设计原因和用法,可能还是有一些模糊,这里总结梳理一下,首先是 sq ring 和 cq ring 分别代表着两个列表,一个是 Submit Queue,一个是 Completion Queue,然后 kernel 和 user program 分别管理一个的头和一个的尾巴作为此生产者彼消费者。ring 主要保存的信息是队列的 meta 信息,然后具体的 sq 的成员是 sqe,Submit Queue Entry 通过间接索引组成队列,不是连续数组。cq 的成员是 cqe 是直接索引访问,连续数组。
三个系统调用分别是初始化;提交,同时还担任了阻塞的功能;注册特定的 fd 保存在内核里减少开销。
应用获取队列数据的方法是根据约定,把 io_uring fd 文件(实际也是 VFS) 的某个 offset 通过 mmap 映射到用户态上来。
由于 io_uring 的队列是单生产者单消费者无锁的(一方只读一方只写),所以应用层可以直接通过访问判断是否有新的 entry 可以消费。多线程访问需要自己加锁。