前言
上一篇讲述了KunlunDB的查询优化原理(KunlunDB 查询优化(一)),本篇讲述Project和Filter下推演示。
一、测试表基本信息
1.1 测试环境
本次测试演示投影和过滤操作的下推。
测试环境的数据库集群共有四个数据节点(DN), 配置为两个shard (shard1和shard2),每个shard节点由一个主节点和一个从节点构成(shard1两个节点为数据复制关系,shard2两个节点也是数据复制关系,shard1 和shard2 存放数据表的不同分片数据)。如下图: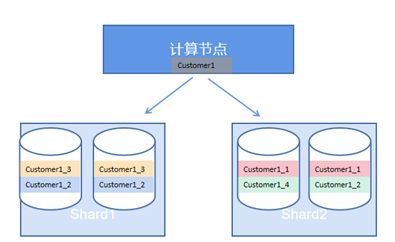
可以通过下面语句显示集群环境的节点信息
select t1.name, t2.shard_id, t2.hostaddr, t2.port,
t2.user_name, t2.passwd from pg_shard t1, pg_shard_node t2
where t2.shard_id=t1.id;结果如下图:

1.2 表结构
本次测试的表结构如下图:

1.3 分片信息
表Customer1依据c_id字段,按范围分区,对应的分区表分别是:
Customer1_1,Customer1_2,Customer1_3,Customer1_4。 4个分片数据分别存在两个shard里:
select t1.nspname, t2.relname,t2.relshardid, t2.relkind
from pg_namespace t1 join pg_class t2 ont1.oid = t2.relnamespace
where t2.relshardid != 0 and relkind='r' and relname like
'%customer1%' order by t2.relname;结果如下图:

1.4 数据分布
数据根据分片规则落于不同的分片存储里
四个分区的数据分布如下图: 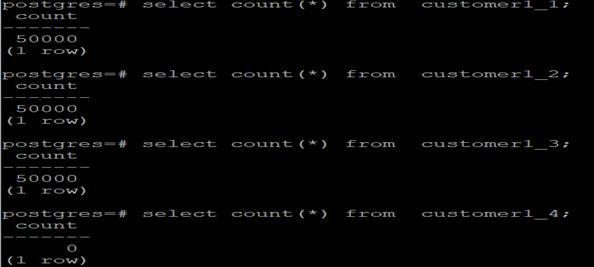
二、查询过程
2.1 过滤
过滤是对查询范围的定位,通过过滤, 可以减少数据块的读写数量。
执行过程:计算节点对SQL 语句解释后,根据查询的目标表customer1 的分片信息,RemoteScan将查询语句下推到对应的存储节点执行(过滤不相关的分片),存储节点将查询结果返回到计算节点。
计算节点采取异步操作的模式做查询下推,多个存储节点可以并行执行。
下列语句,根据分片键值范围,SQL语句对下推到对应的存储节点(shard2)(这是SQL 执行引擎的第一过滤)。
explain select c_id,c_first,c_middle from customer1
where c_id=4;结果如下图:

标记处即为执行计划中的过滤操作。
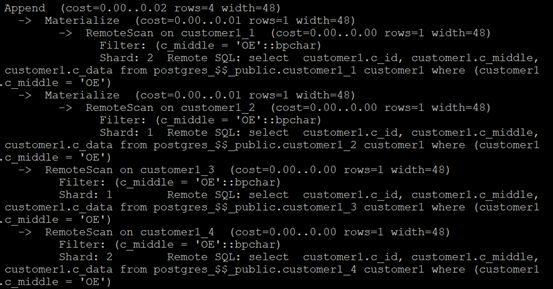
如果查询条件没有带由分片关键字,RemoteScan会将语句下发到所有的分片节点,在分片结果根据查询条件过滤。
explain select c_id ,c_middle,c_data from customer1
where c_middle='OE';结果如下图:
KunlunDB 支持在查询条件中使用函数及各种复杂的条件
explain select count(*) from customer1
where sqrt(c_discount)>0.5;结果如下图:

2.2 Project投影
计算节点对SQL 语句解释后, 根据查询的目标表customer1 的分片信息, RemoteScan将查询语句下推到各个存储节点执行,存储节点将查询结果行中部分的字段(投影)返回到计算节点。
Project操作减少了返回到计算节点的实际字段数量(只返回查询需要的,不相关的字段不会被读入计算节点的内存中去)。
执行过程参考下图:
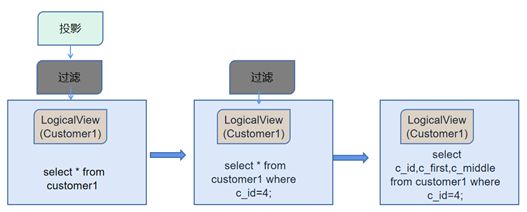
explain select c_id,c_first,c_middle from customer1;结果如下图:

上面语句执行过程,remoteScan只返回字段c_id,c_first,c_middle数据到计算节点。
KunlunDB支持字段上的函数及各种复杂条件的Project
explain selectc_balance + c_ytd_payment from customer1
where c_id =20;结果如下图:

存储节点只返回c_balance+c_ytd_payment 的结果到计算节点。
2.3 分片的好处
分布式数据库在数据库层透明的将数据库分布在不同的存储节点,由此带来的好处:
- 对应用程序透明,即应用程序不需要做任何修改就可以访问数据。
- 存储节点对数据做读取及投影操作,减少计算节点的负载(更少的CPU 和内存消耗)。
- 数据分布在不同的存储节点上,方便系统弹性扩展IO 能力及避免IO 的热点竞争。
- 投影和过滤操作,减少数据块读写范围 ,可以提高查询效率。
三、性能比对
在同一个环境里建一个与customer1完全相同数据(量)的数据表,然后执行相同的查询,对比查询的效率。
3.1 对分片表的查询
select now(); select count(*) from customer1
where c_id between 4 and 10;select now();结果如下图:

耗时:0.05s
3.2 对非分片表查询
创建表:
CREATE TABLEcustomer1temp (like customer1);
insert intocustomer1temp select * From customer1结果如下图:

查询时间:
select now(); select count(*) from customer1temp
where c_idbetween 4 and 10 ;select now();结果如下图: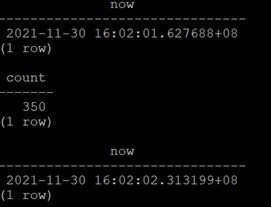
耗时:0.69s
结论
通过Project和Filter的利用,表分片可以提高数据查询效率。
*KunlunDB项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
END