React知识点总结(七)
React知识点总结(Fiber&Diff)
文章目录
- React知识点总结(Fiber&Diff)
- 一、Fiber模型是什么
-
- 1.代数效应
- 2.代数效应在React中的体现
- 3.React Fiber
- 4.Fiber的起源
- Fiber的结构
-
- (一)作为架构
- (二)作为静态的数据结构
- (三)作为动态的更新单元
- 二、Fiber树是如何构建/更新的
-
- 1.“递”与“归”
-
- “递”
- “归”
- 2.beginWork方法都做了什么?
- 3.completeWork做了什么?
- 三、Diff算法
-
- 单节点
- 多节点
-
- 第一轮
- 第二轮
-
- 1.newChildren与oldFiber同时遍历完
- 2.newChildren没遍历完,oldFiber遍历完
- 3.newChildren遍历完,oldFiber没遍历完
- 4.newChildren与oldFiber都没遍历完
- 四、状态更新
-
- 状态更新的流程图
- Update
-
- Update的分类
- Update与fiber的关系(class组件)
- 五、优先级
-
- 如何保证Update对象不丢失
- 如何保证状态依赖的连续性
- 六、commit阶段中的useEffect执行时机
一、Fiber模型是什么
1.代数效应
代数效应是函数式编程中的一个概念,是指将函数的副作用抽离出函数,只关心函数的功能。(可以简单理解为在不同使用场景像替代数字一样简单。。。在使用时使用规则不会变化,来限制使用)
2.代数效应在React中的体现
典型的例子就是React中的hooks,我们不需要关心内部实现,且在函数组件中使用时用法都相同,不会有什么副作用,只需关注业务逻辑即可。
function App() {
const [num, updateNum] = useState(0);
return (
<button onClick={() => updateNum(num => num + 1)}>{num}</button>
)
}
3.React Fiber
React Fiber是React一套状态更新机制,支持中断和恢复以及不同优先级,更新单元为React Element对应的Fiber对象。
4.Fiber的起源
在React15及以前,
Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,造成卡顿。
为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
Fiber的结构
(一)作为架构
每个Fiber对象是靠什么来构成Fiber树的呢,靠一下三个属性:
// 指向父级Fiber节点
this.return = null;
// 指向子Fiber节点
this.child = null;
// 指向右边第一个兄弟Fiber节点
this.sibling = null;
如:

(二)作为静态的数据结构
每个Fiber对象保存了DOM对象/组件相关的信息
// Fiber对应组件的类型 Function/Class/Host...
this.tag = tag;
// key属性
this.key = key;
// 大部分情况同type,某些情况不同,比如FunctionComponent使用React.memo包裹
this.elementType = null;
// 对于 FunctionComponent,指函数本身,对于ClassComponent,指class,对于HostComponent,指DOM节点tagName
this.type = null;
// Fiber对应的真实DOM节点
this.stateNode = null;
(三)作为动态的更新单元
每个Fiber对象保存了此次更新相关的信息:
// 保存本次更新造成的状态改变相关信息
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
// 保存本次更新会造成的DOM操作
this.effectTag = NoEffect;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
二、Fiber树是如何构建/更新的
这一过程发生在render阶段
1.“递”与“归”
通过遍历的方式实现可以中断的递归:
“递”
从rootFiber开始深度优先遍历,每一个Fiber对象都调用beginWork方法,这个方法会为传入的Fiber对象创建子Fiber对象,并将两者连接起来。当遍历到叶子节点(没有子组件了)就进入“归”阶段
“归”
在此阶段会调用completeWork方法,来处理Fiber对象。若当前对象还有兄弟节点,则处理完当前节点后会进入兄弟节点的“递”阶段。当执行到rootFiber时render阶段就结束了。
2.beginWork方法都做了什么?
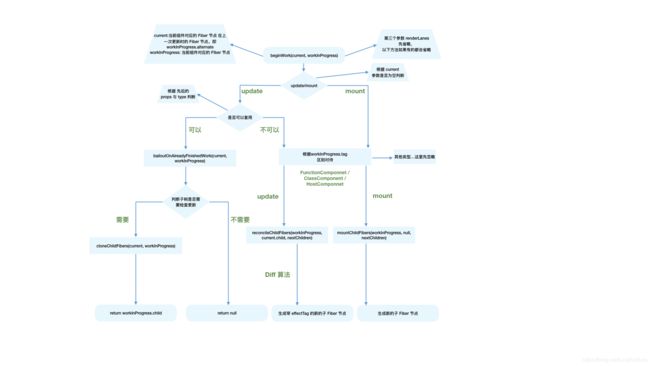
3.completeWork做了什么?

三、Diff算法
一般的Diff算法,时间复杂度在O(n3),React为了提升效率,提出了三个限制条件:
- 按层来比较元素,如果跨层则不会进行移动操作,而会重新生成元素。
- 不同的类型的节点会产生不同的树如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 使用
key属性来定位元素Diff前后位置的变化
可以将Diff算法分为两类:单节点和多节点(指的是workInProgressFiber,即新的fiber节点)。
单节点
React通过先判断key是否相同,如果key相同则判断type是否相同,只有都相同时一个DOM节点才能复用。
注意!
1.当child!==null且key相同且type不同时执行deleteRemainingChildren将child及其兄弟fiber都标记删除。
2.当child!==null且key不同时仅将child标记删除。
如:
// 当前页面显示的
ul > li * 3
// 这次需要更新的
ul > p
p的key和li的key不同,说明当前以及后面的兄弟元素都不可能有相同的key,则没有必要继续遍历,不可复用之前的节点,需生成新的节点。
多节点
分两轮遍历
第一轮
let i = 0,遍历newChildren,将newChildren[i]与oldFiber比较,判断DOM节点是否可复用。- 如果可复用,
i++,继续比较newChildren[i]与oldFiber.sibling,可以复用则继续遍历。 - 如果不可复用,分两种情况:
key不同导致不可复用,立即跳出整个遍历,第一轮遍历结束。
key相同type不同导致不可复用,会将oldFiber标记为DELETION,并继续遍历。 - 如果
newChildren遍历完(即i === newChildren.length -
1)或者oldFiber遍历完(即oldFiber.sibling === null),跳出遍历,第一轮遍历结束。
第二轮
1.newChildren与oldFiber同时遍历完
那就是最理想的情况:只需在第一轮遍历进行组件更新 。此时Diff结束。
2.newChildren没遍历完,oldFiber遍历完
已有的DOM节点都复用了,这时还有新加入的节点,意味着本次更新有新节点插入,我们只需要遍历剩下的newChildren为生成的workInProgress fiber依次标记Placement。
3.newChildren遍历完,oldFiber没遍历完
意味着本次更新比之前的节点数量少,有节点被删除了。所以需要遍历剩下的oldFiber,依次标记Deletion。
4.newChildren与oldFiber都没遍历完
这意味着有节点在这次更新中改变了位置。
用一个简单的Demo来看一下整个判断的过程
// 之前
abcd
// 之后
acdb
===第一轮遍历开始===
a(之后)vs a(之前)
key不变,可复用
此时 a 对应的oldFiber(之前的a)在之前的数组(abcd)中索引为0
所以 lastPlacedIndex = 0;
继续第一轮遍历...
c(之后)vs b(之前)
key改变,不能复用,跳出第一轮遍历
此时 lastPlacedIndex === 0;
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === cdb,没用完,不需要执行删除旧节点
oldFiber === bcd,没用完,不需要执行插入新节点
将剩余oldFiber(bcd)保存为map
// 当前oldFiber:bcd
// 当前newChildren:cdb
继续遍历剩余newChildren
key === c 在 oldFiber中存在
const oldIndex = c(之前).index;
此时 oldIndex === 2; // 之前节点为 abcd,所以c.index === 2
比较 oldIndex 与 lastPlacedIndex;
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动
并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
在例子中,oldIndex 2 > lastPlacedIndex 0,
则 lastPlacedIndex = 2;
c节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:bd
// 当前newChildren:db
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
oldIndex 3 > lastPlacedIndex 2 // 之前节点为 abcd,所以d.index === 3
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:b
// 当前newChildren:b
key === b 在 oldFiber中存在
const oldIndex = b(之前).index;
oldIndex 1 < lastPlacedIndex 3 // 之前节点为 abcd,所以b.index === 1
则 b节点需要向右移动
===第二轮遍历结束===
最终acd 3个节点都没有移动,b节点被标记为移动
四、状态更新
状态更新的流程图
触发状态更新(根据场景调用不同方法)
|
|
v
创建Update对象(给触发状态更新的fiber对象创建)
|
|
v
从fiber到root(`markUpdateLaneFromFiberToRoot`由于render阶段是从rootFiber向下执行的,为了得到rootFiber,从触发状态更新的fiber得到rootFiber,同时包含给不同的fiber标记优先级)
|
|
v
调度更新(`ensureRootIsScheduled`)
|
|
v
render阶段(`performSyncWorkOnRoot` 或 `performConcurrentWorkOnRoot` 同步更新还是异步更新)
|
|
v
commit阶段(`commitRoot`)
Update
Update的分类
- ReactDOM.render —— HostRoot
- this.setState —— ClassComponent
- this.forceUpdate —— ClassComponent
- useState —— FunctionComponent
- useReducer —— FunctionComponent
Update与fiber的关系(class组件)
fiber节点存在着updateQueue,updateQueue为保存更新对象的链表。
fiber.updateQueue.baseUpdate: u1 --> u2 --> u3 --> u4
接下来遍历updateQueue.baseUpdate链表,以fiber.updateQueue.baseState为初始state,依次与遍历到的每个Update计算并产生新的state。在遍历时如果有优先级低的Update会被跳过。
state的变化在render阶段产生与上次更新不同的JSX对象,通过Diff算法产生effectTag,在commit阶段渲染在页面上。
五、优先级
通过一张图来了解一下React的优先级:
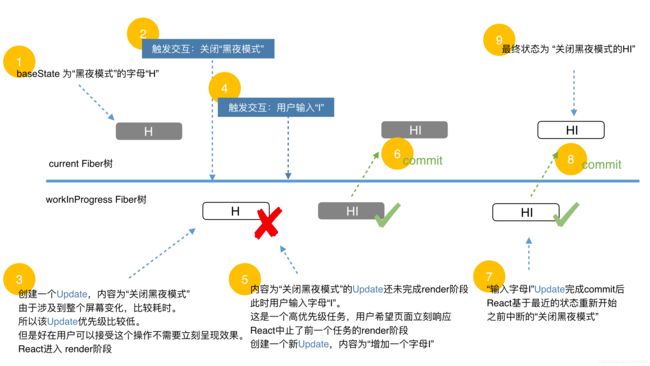
在这个例子中,u1的优先级较u2的优先级低,首先u1进入render阶段,当产生u2时,中断u1,u2进入render阶段。此时,该Update对象保存的链表是:
u1 -- u2
由于u1的优先级较低,u1会被跳过,u2会进入render-commit阶段。在commit阶段再调度一次更新,这次是基于baseState中firstBaseUpdate保存的u1,开启一次新的render阶段。
如何保证Update对象不丢失
在render阶段,shared.pending的环被剪开并连接在updateQueue.lastBaseUpdate后面。实际上shared.pending会被同时连接在workInProgress updateQueue.lastBaseUpdate与current updateQueue.lastBaseUpdate后面。
当开启一个新的render时,会基于current updateQueue克隆出workInProgress updateQueue,所以不会丢失。
如何保证状态依赖的连续性
当某个Update优先级低于当前优先级时,当前Update对象和之后的Update对象会被跳过,保存到baseUpdate中作为下次Update更新的Update。且当前的baseState为更新后的state,不是被跳过时的state。
六、commit阶段中的useEffect执行时机
before mutation阶段在scheduleCallback中调度flushPassiveEffectslayout阶段之后将effectList赋值给rootWithPendingPassiveEffectsscheduleCallback触发flushPassiveEffects,flushPassiveEffects内部遍历rootWithPendingPassiveEffects
参考文章:
React技术揭秘