精通Redis2、Redis底层数据结构分析(一)
目录
- 一.String 底层数据结构
-
- 1.1sds 优点
- 1.2 sds 的实现
- 1.3惰性空间释放
- 1.4二进制安全
- 1.5 兼容部分C 字符串函数
- 二、Redis 内部编码
-
-
- INT 编码格式
- EMBSTR编码格式
- RAW 编码格式
-
- 三、链表
- 四、字典
-
- 4.1实现数据库键空间 key space
- 4.2用作 Hash 类型键的其中一种底层实现
- 4.3字典的定义
-
- 字典的实现
- 哈希表实现
- 4.4 hash 算法
- 4.5 rehash
-
- 扩容代码:
- 收缩代码:
一.String 底层数据结构
Sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示,它被用
在几乎所有的 Redis 模块中。
Sds 在 Redis 中的主要作用有以下两个:
- 实现字符串对象(StringObject);
- 在 Redis 程序内部用作 char* 类型的替代品;
1.1sds 优点
在 C 语言中,字符串可以用一个 \0 结尾的 char 数组来表示。
比如说, hello world 在 C 语言中就可以表示为 “hello world\0” 。
这种简单的字符串表示在大多数情况下都能满足要求,但是,它并不能高效地支持长度计算和
追加(append)这两种操作:
- 每次计算字符串长度(strlen(s))的复杂度为 θ(N) 。
- 对字符串进行 N 次追加,必定需要对字符串进行 N次内存重分配(realloc)。
在 Redis 内部,字符串的追加和长度计算并不少见,而 APPEND 和 STRLEN 更是这两种操
作在 Redis 命令中的直接映射,这两个简单的操作不应该成为性能的瓶颈。
另外, Redis 除了处理 C 字符串之外,还需要处理单纯的字节数组,以及服务器协议等内容,
所以为了方便起见, Redis 的字符串表示还应该是二进制安全的:程序不应对字符串里面保存
的数据做任何假设,数据可以是以 \0 结尾的 C 字符串,也可以是单纯的字节数组,或者其他
格式的数据。
考虑到这两个原因, Redis 使用 sds 类型替换了 C 语言的默认字符串表示: sds 既可以高效地
实现追加和长度计算,并且它还是二进制安全的。
1.2 sds 的实现
在前面的内容中,我们一直将 sds 作为一种抽象数据结构来说明,实际上,它的实现由以下两
部分组成:
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
其中,类型 sds 是 char * 的别名 (alias),而结构 sdshdr 则保存了 len 、 free 和 buf 三个
属性。
作为例子,以下是新创建的,同样保存 hello world 字符串的 sdshdr 结构:
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0"; // buf 的实际长度为 len + 1
};
通过 len 属性, sdshdr 可以实现复杂度为 θ(1) 的长度计算操作。
另一方面,通过对 buf 分配一些额外的空间,并使用 free 记录未使用空间的大小, sdshdr 可
以让执行追加操作所需的内存重分配次数大大减少,下一节我们就会来详细讨论这一点。
当然, sds 也对操作的正确实现提出了要求——所有处理 sdshdr 的函数,都必须正确地更新
len 和 free 属性,否则就会造成 bug 。
Redis数据库,经常被用作速度要求严苛、数据频繁修改的场合,如果每次修改字符串长度都需要执行一次内存分配的话,那么光是执行内存分配的时间就会占去字符串修改所用时间的一大部分,若是这样,可能对性能产生影响。
为了避免C字符串的这种缺陷,SDS通过未使用的空间解除字符串长度和底层之间的关联,在SDS中,buf数组的长度一定就是字符串数量加一,数组里可以包含未使用的字节,这些字节的数量就是SDS中free中属性的记录。
注意:当分配空间不足时是,修改len 小于1Mb,free 等于Len
空间总是翻倍,len大于1mb,free等于1MB.
例子:若修改之后,SDS的len将变成13字节,那么程序也会分配13个字节的未使用空间,sds数组的实际长度会是13+13+1=27字节
若SDS 的len修改之后将大于等于1MB ,以30MB为例子,那么sds的数组的实际长度会是 30mb +1mb +1byte.
这点需要注意String 中的命令
APPEND key value
如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
如果大规模频繁的最字符串进行扩容操作,则注意Redis 服务器的内存情况
这种思路就是利用空间换取时间,线上分析问题的时候注意时间段,空间。
通过这种预分配策略,SDS将连续增长N次所需的内存分配次数从必定N次降低为最多N次
代码分析:
代码版本6.0.8
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {sdshdr
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
可以看到容量成倍增加,注释中解释sdshdr5 is never used。
- len:字符串的长度(实际使用的长度)
- alloc:分配内存的大小
- flags:标志位,低三位表示类型,其余五位未使用
- buf:字符数组
1.3惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作:当SDS的API需要缩短SDS保存的字符串时,程序并不是立即使用内存重分配来回收缩短多出来的字节,而是使用free属性将这些字节的数量记录起来,并等待将来使用。
SDS提供了相应的API,让我们在需要时,真正释放SDS的未使用空间。
1.4二进制安全
C字符串的字符必须符合某种编码,并且除了字符串的末尾之外,字符串里边不能包含空字符串,否则最先被程序读入的空字符串被误认为字符串的结尾,C只能保存文本数据。而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
SDS的API都是二进制安全的 binzry-safe
,所有SDS API 都会处理二进制的方式来处理SDS buffer数组里的数据
1.5 兼容部分C 字符串函数
二、Redis 内部编码
对于 Redis的常用 5 种数据类型(String、Hash、List、Set、sorted set),每种数据类型都提供了 最少两种 内部的编码格式,而且每个数据类型内部编码方式的选择 对用户是完全透明的,Redis会根据数据量自适应地选择较优化的内部编码格式。
如果想查看某个键的内部编码格式,可以使用 OBJECT ENCODING keyname 指令来进行,比如:
127.0.0.1:6379>
127.0.0.1:6379> set foo bar
OK
127.0.0.1:6379>
127.0.0.1:6379> object encoding foo // 查看某个Redis键值的编码
"embstr"
127.0.0.1:6379>
127.0.0.1:6379>
Redis 的每个键值内部都是使用一个名字叫做 redisObject 这个 C语言结构体保存的,其代码如下:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
解释如下:
- type:表示键值的数据类型,包括 String、List、Set、ZSet、Hash
- encoding:表示键值的内部编码方式,从 Redis源码看目前取值有如下几种:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
refcount:表示该键值被引用的数量,即一个键值可被多个键引用
INT 编码格式
命令示例: set foo 123
当字符串键值的内容可以用一个 64位有符号整形 来表示时,Redis会将键值转化为 long型来进行存储,此时即对应 OBJ_ENCODING_INT 编码类型。
OBJ_ENCODING_INT 编码类型内部的内存结构可以形象地表示如下:
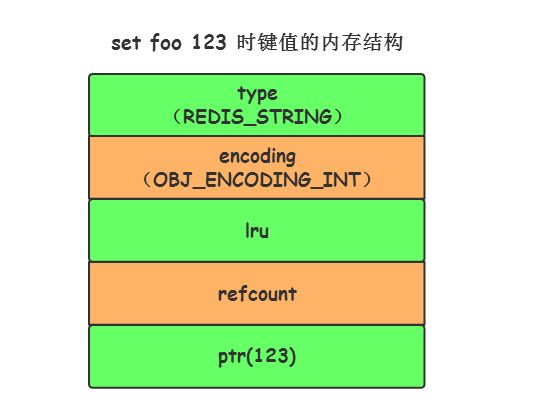
set foo 123 时键值的内存结构
而且 Redis 启动时会预先建立 10000 个分别存储 0~9999 的 redisObject 变量作为共享对象,这就意味着如果 set字符串的键值在 0~10000 之间的话,则可以 直接指向共享对象 而不需要再建立新对象,此时键值不占空间!
因此,当执行如下指令时:
set key1 100
set key2 100
其实 key1 和 key2 这两个键值都直接引用了一个 Redis 预先已建立好的共享 redisObject 对象,就像下面这样:
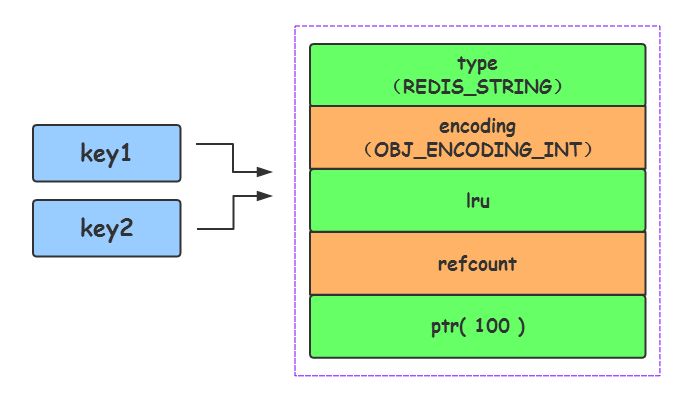
共享对象
源码之前,了无秘密,我们再对照下面的源码,来理解一下上述过程

INT编码的源码
EMBSTR编码格式
命令示例: set foo abc
Redis 在保存长度小于 44 字节的字符串时会采用 OBJ_ENCODING_EMBSTR 编码方式,口说无凭,我们来瞅瞅源码:

EMBSTR编码的判断条件
从上述代码中很容易看出,对于长度小于 44的字符串,Redis 对键值采用OBJ_ENCODING_EMBSTR 方式,EMBSTR 顾名思义即:embedded string,表示嵌入式的String。从内存结构上来讲 即字符串 sds结构体与其对应的 redisObject 对象分配在 同一块连续的内存空间,这就仿佛字符串 sds 嵌入在 redisObject 对象之中一样,这一切从下面的代码即可清楚地看到:

embedded string
因此,对于指令 set foo abc 所设置的键值,其内存结构示意图如下:
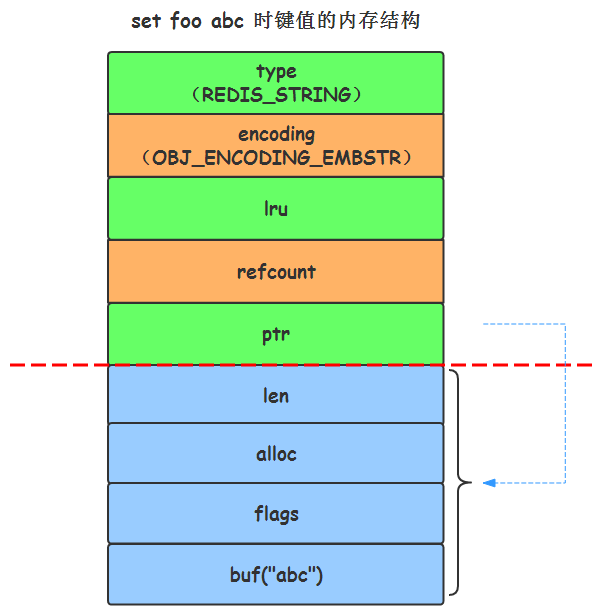
set foo abc时的键值内存结构
RAW 编码格式
指令示例: set foo abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx
正如指令示例,当字符串的键值为长度大于 44 的 超长字符串 时,Redis 则会将键值的内部编码方式改为 OBJ_ENCODING_RAW 格式,这与上面的 OBJ_ENCODING_EMBSTR 编码方式的不同之处在于 此时动态字符串 sds 的内存与其依赖的 redisObject 的 内存不再连续 了,以 set foo abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx 为例,其键值的内存结构如下所示:

set foo abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx时键值的内存结构
到此就讲完了最基本的String数据类型的内部编码情况,怎么样,还是挺好理解的吧!
后续我们将继续剖析 Redis 中 Hash 数据类型的内部编码格式。
参考资料:https://www.jianshu.com/p/666452a22855
三、链表
链表作为数组之外的一种常用序列抽象,是大多数高级语言的基本数据类型,因为 C 语言本身
不支持链表类型,大部分 C 程序都会自己实现一种链表类型, Redis 也不例外——它实现了一
个双端链表结构。
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
学校里的C语言,暂时不能调试redis源码
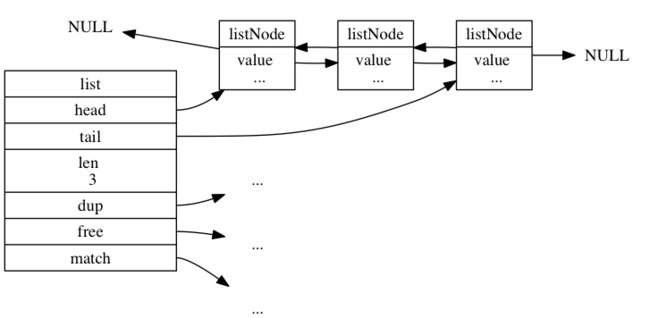
- 作为列表键的底层实现之一:当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
- 除此之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息, 以及使用链表来构建客户端输出缓冲区。
-
双向链表从
listNode 的结构我们可以看到,包含了前直接点和后置节点。所以可以很方便的进行正向和反向的遍历。 -
无环链表
表头结点的 prev 指针和表尾结点的 next 指针都指向 null, 所以 Redis 的链表是一个无环链表。 -
带有头指针和尾指针
在 list 结构中,保存了当前链表的表头指针和表尾指针,因此可以快速的从头进行遍历或者从尾部开始遍历。 -
带有长度计数器
list 结构中保存了当前链表长度的长度,因此对链表长度的统计时间复杂度是 O(1).
四、字典
字典(dictionary),又名映射(map)或关联数组(associative array), 它是一种抽象数据结
构,由一集键值对(key-value pairs)组成,各个键值对的键各不相同,程序可以将新的键值对
添加到字典中,或者基于键进行查找、更新或删除等操作。
C语言并没有内置这种数据结构,Redis 实现了自己的字典。
字典的主要用途有以下两个:
- 实现数据库键空间(key space);
- 用作 Hash 类型键的其中一种底层实现;
4.1实现数据库键空间 key space
Redis 是一个键值对数据库,数据库中的键值对就由字典保存:每个数据库都有一个与之相对
应的字典,这个字典被称之为键空间(key space)。
当用户添加一个键值对到数据库时(不论键值对是什么类型),程序就将该键值对添加到键空
间;当用户从数据库中删除一个键值对时,程序就会将这个键值对从键空间中删除;等等。
举个例子,执行 FLUSHDB 可以清空键空间上的所有键值对数据:
redis> FLUSHDB
OK
执行 DBSIZE 则返回键空间上现有的键值对:
redis> DBSIZE
(integer) 0
还可以用 SET 设置一个字符串键到键空间,并用 GET 从键空间中取出该字符串键的值:
redis> SET number 10086
OK
redis> GET number
"10086"
redis> DBSIZE
(integer) 1
4.2用作 Hash 类型键的其中一种底层实现
Redis 的 Hash 类型键使用以下两种数据结构作为底层实现:
- 字典;
- 压缩列表;
因为压缩列表比字典更节省内存,所以程序在创建新 Hash 键时,默认使用压缩列表作为底层
实现,当有需要时,程序才会将底层实现从压缩列表转换到字典。
当用户操作一个 Hash 键时,键值在底层就可能是一个哈希表:
redis> HSET book name "The design and implementation of Redis"
(integer) 1
redis> HSET book type "source code analysis"
(integer) 1
redis> HSET book release-date "2013.3.8"
(integer) 1
redis> HGETALL book
1) "name"
2) "The design and implementation of Redis"
3) "type"
4) "source code analysis"
5) "release-date"
6) "2013.3.8"
《哈希表》章节给出了关于哈希类型键的更多信息,并介绍了压缩列表和字典之间的转换条件。
介绍完了字典的用途,现在让我们来看看字典数据结构的定义。
4.3字典的定义
字典的实现
实现字典的方法有很多种:
- • 最简单的就是使用链表或数组,但是这种方式只适用于元素个数不多的情况下;
• 要兼顾高效和简单性,可以使用哈希表;
• 如果追求更为稳定的性能特征,并且希望高效地实现排序操作的话,则可以使用更为复
杂的平衡树;
在众多可能的实现中, Redis 选择了高效且实现简单的哈希表作为字典的底层实现。
dict.h/dict 给出了这个字典的定义
/*
*字典
*/
typedef struct dict {
dictType *type;
void *privdata;
//hash表个数
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
ht属性是一个包含了两个项的数组,数组的每个项都是一个dictht
哈希表,一般情况下字典只使用ht[0]哈希表,ht[1]哈希表只是在ht[0]哈希表进行rehash时使用。
rehashidx 记录rehash 的进度,如果没有进行 值为-1
哈希表实现
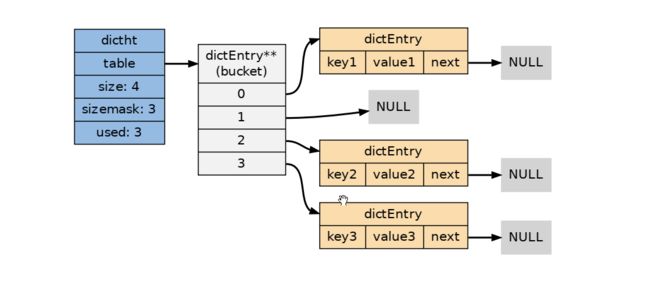
字典所使用的哈希表实现由 dict.h/dictht 类型定义:
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶, bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
table 属性是一个数组,数组的每个元素都是一个指向 dictEntry 结构的指针。
每个 dictEntry 都保存着一个键值对,以及一个指向另一个 dictEntry 结构的指针:
/*
*哈希节点
*/
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e6II8y7a-1601172888918)(https://i.imgrpost.com/imgr/2020/09/26/FoxitReader_VIM1v3M0Nt.png)]
4.4 hash 算法
Redis 目前使用两种不同的哈希算法:
- MurmurHash2 32 bit 算法:这种算法的分布率和速度都非常好,具体信息请参考 MurmurHash 的主页: http://code.google.com/p/smhasher/ 。
- 基 于 djb 算 法 实 现 的 一 个 大 小 写 无 关 散 列 算 法: 具 体 信 息 请 参 考
该方法在dictGenHashFunction中实现
unsigned int dictGenHashFunction(const void *key, int len) { //用于计算字符串的哈希值的哈希函数
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//m和r这两个值用于计算哈希值,只是因为效果好。
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //初始化
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//将字符串key每四个一组看成uint32_t类型,进行运算的到h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
http://www.cse.yorku.ca/~oz/hash.html 。
使用哪种算法取决于具体应用所处理的数据:
• 命令表以及 Lua 脚本缓存都用到了算法 2 。
• 算法 1 的应用则更加广泛:数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。
在哈希表实现中,当两个不同的键拥有相同的哈希值时,我们称这两个键发生碰撞(collision),
而哈希表实现必须想办法对碰撞进行处理。
字典哈希表所使用的碰撞解决方法被称之为链地址法:这种方法使用链表将多个哈希值相同的
节点串连在一起,从而解决冲突问题。
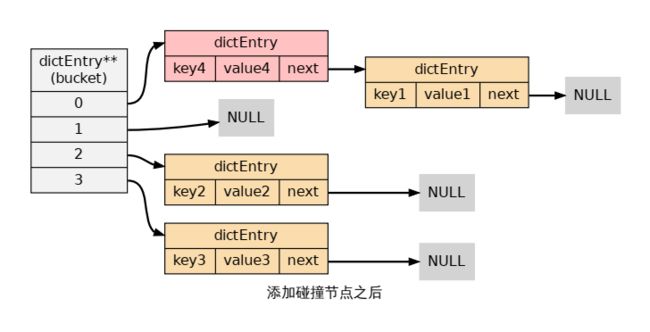
考虑到速度,节点总是被添加到链表头部位置,复杂度为O(1)
这里可以对比Java的hashMap 对比记忆。
4.5 rehash
当哈希表的大小不能满足需求,就可能会有两个或者以上数量的键被分配到了哈希表数组上的同一个索引上,于是就发生冲突(collision).
在Redis中解决冲突的办法是链接法(separate chaining)。但是需要尽可能避免冲突,希望哈希表的负载因子(load factor),维持在一个合理的范围之内,就需要对哈希表进行扩展或收缩。
扩容:当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
缩容:当 hash 表因为元素的逐渐删除变得越来越稀疏时,,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。缩容不会考虑 Redis 是否正在做 bgsave。
大字典的扩容是比较耗时间的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个O(n)级别的操作.
扩容代码:
static int _dictExpandIfNeeded(dict *d) //扩展d字典,并初始化
{
if (dictIsRehashing(d)) return DICT_OK; //正在进行rehash,直接返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
//1. 字典的总元素个数和字典的数组大小之间的比率接近 1:1
//2. 能够扩展的标志为真
//3. 已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //扩展为节点个数的2倍
}
return DICT_OK;
}
收缩代码:
int dictResize(dict *d) //缩小字典d
{
int minimal;
//如果dict_can_resize被设置成0,表示不能进行rehash,或正在进行rehash,返回出错标志DICT_ERR
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //获得已经有的节点数量作为最小限度minimal
if (minimal < DICT_HT_INITIAL_SIZE)//但是minimal不能小于最低值DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //用minimal调整字典d的大小
}
参考链接:https://www.jianshu.com/p/7f53f5e683cf
渐进式rehash
详细步骤:
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个hash表
-
在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,标识rehash工作正式开始。
-
在rehash期间,每次对字典执行添加、删除、查找或者更新操作时,程序出了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上所有的键值对rehash到ht[1],当rehash工作完成之后,将rehashidx属性值增一。
-
随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx的树形值设置为-1,表示rehash操作已经完成。
渐进式rehash好处是分而治之,将rehash键值所需的计算工作分摊到对字典的每个添加、删除、查找和跟新操作上,从而避免了集中式rehash而带来的庞大计算量。
在渐进rehash期间,同时使用ht[0]和ht[1]两个哈希表,先查找ht[0],再查找ht[1]
新添加到字典的键值对,一律保存到ht[1]
里面
本文禁止任何形式的转载,内容参考《Redis设计与实现》。
文中Redis版本6.0.8
如有错误之处欢迎沟通交流。