java新技术有哪些,转疯了!
前言
高并发,几乎是每个程序员都想拥有的经验。原因很简单:随着流量变大,会遇到各种各样的技术问题,比如接口响应超时、CPU load升高、GC频繁、死锁、大数据量存储等等,这些问题能推动我们在技术深度上不断精进。
我们知道,高并发代表着大流量,高并发系统设计的魅力就在于我们能够凭借自己的聪明才智设计巧妙的方案,从而抵抗巨大流量的冲击,带给用户更好的使用体验。这些方案好似能操纵流量,让流量更加平稳得被系统中的服务和组件处理。
1、背景
首先,让我们简要地讨论下每个系统,以了解它们的高级设计和架构,看下每个系统所做的权衡。
Kafka 是一个开源的分布式事件流处理平台,也是 Apache 软件基金会下五个最活跃的项目之一。在其核心,Kafka 被设计成一个多副本的分布式持久化提交日志,用于支撑事件驱动的微服务或大规模流处理应用程序。客户端向代理集群提供事件或使用代理集群的事件,而代理会向底层文件系统写入或从底层文件系统读取事件,并自动在集群中同步或异步地复制事件,以实现容错性和高可用性。
Pulsar 是一个开源的分布式发布 / 订阅消息系统,最初是服务于队列用例的。最近,它又增加了事件流处理功能。Pulsar 被设计为一个(几乎)无状态代理实例层,它连接到单独的 BookKeeper 实例层,由它实际地读取 / 写入消息,也可以选择持久地存储 / 复制消息。Pulsar 并不是唯一的同类系统,还有其他类似的消息传递系统,如 Apache DistributedLog 和 Pravega,它们都是在 BookKeeper 之上构建的,也是旨在提供一些类似 Kafka 的事件流处理功能。
BookKeeper 是一个开源的分布式存储服务,最初是为 Apache Hadoop 的 NameNode 而设计的预写日志。它跨服务器实例 bookies,在 ledgers 中提供消息的持久存储。为了提供可恢复性,每个 bookie 都会同步地将每条消息写入本地日志,然后异步地写入其本地索引 ledger 存储。与 Kafka 代理不同,bookie 之间不进行通信,BookKeeper 客户端使用 quorum 风格的协议在 bookie 之间复制消息。
RabbitMQ 是一个开源的传统消息中间件,它实现了 AMQP 消息标准,满足了低延迟队列用例的需求。RabbitMQ 包含一组代理进程,它们托管着发布消息的“交换器”,以及从中消费消息的队列。可用性和持久性是其提供的各种队列类型的属性。经典队列提供的可用性保证最少。经典镜像队列将消息复制到其他代理并提高可用性。最近引入的仲裁队列提供了更强的持久性,但是以性能为代价。由于这是一篇面向性能的博文,所以我们将评估限制在经典队列和镜像队列。
2、分布式系统的持久性
单节点存储系统(例如 RDBMS)依靠 fsync 写磁盘来确保最大的持久性。但在分布式系统中,持久性通常来自复制,即数据的多个副本独立失效。数据 fsync 只是在发生故障时减少故障影响的一种方法(例如,更频繁地同步可能缩短恢复时间)。相反,如果有足够多的副本失败,那么无论是否使用 fsync,分布式系统都可能无法使用。因此,我们是否使用 fsync 只是这样一个问题,即每个系统选择基于什么方式来实现其复制设计。有些系统非常依赖于从不丢失写入到磁盘的数据,每次写入时都需要 fsync,但其他一些则是在其设计中处理这种情况。
Kafka 的复制协议经过精心设计,可以确保一致性和持久性,而无需通过跟踪什么已 fsync 到磁盘什么未 fsync 到磁盘来实现同步 fsync。Kafka 假设更少,可以处理更大范围的故障,比如文件系统级的损坏或意外的磁盘移除,并且不会想当然地认为尚不知道是否已 fsync 的数据是正确的。Kafka 还能够利用操作系统批量写入磁盘,以获得更好的性能。
我们还不能十分确定,BookKeeper 是否在不 fsync 每个写操作的情况下提供了相同的一致性保证——特别是在没有同步磁盘持久化的情况下,它是否可以依赖复制来实现容错。关于底层复制算法的文档或文章中没有提及这一点。基于我们的观察,以及 BookKeeper 实现了一个分组 fsync 算法的事实,我们相信,它确实依赖于 fsync 每个写操作来确保其正确性,但是,社区中可能有人比我们更清楚我们的结论是否正确,我们希望可以从他们那里获得反馈。
无论如何,由于这可能是一个有争议的话题,所以我们分别给出了这两种情况下的结果,以确保我们的测试尽可能的公平和完整,尽管运行带有同步 fsync 功能的 Kafka 极其罕见,也是不必要的。
3、基准测试框架
对于任何基准测试,人们都想知道使用的是什么框架以及它是否公平。为此,我们希望使用 OpenMessaging Benchmark Framework(OMB),该框架很大一部分最初是由 Pulsar 贡献者编写的。OMB 是一个很好的起点,它有基本的工作负载规范、测试结果指标收集 / 报告,它支持我们选择的三种消息系统,它还有针对每个系统定制的模块化云部署工作流。但是需要注意,Kafka 和 RabbitMQ 实现确实存在一些显著的缺陷,这些缺陷影响了这些测试的公平性和可再现性。最终的基准测试代码,包括下面将要详细介绍的修复程序,都是开源的。
OMB 框架修复
我们升级到 Java 11 和 Kafka 2.6、RabbitMQ 3.8.5 和 Pulsar 2.6(撰写本文时的最新版本)。借助 Grafana/Prometheus 监控栈,我们显著增强了跨这三个系统的监控能力,让我们可以捕获跨消息系统、JVM、Linux、磁盘、CPU 和网络的指标。这很关键,让我们既能报告结果,又能解释结果。我们增加了只针对生产者的测试和只针对消费者的测试,并支持生成 / 消耗积压,同时修复了当主题数量小于生产者数量时生产者速率计算的一个重要 Bug。
OMB Kafka 驱动程序修复
我们修复了 Kafka 驱动程序中一个严重的 Bug,这个 Bug 让 Kafka 生产者无法获得 TCP 连接,存在每个工作者实例一个连接的瓶颈。与其他系统相比,这个补丁使得 Kafka 的数值更公平——也就是说,现在所有的系统都使用相同数量的 TCP 连接来与各自的代理通信。我们还修复了 Kafka 基准消费者驱动程序中的一个关键 Bug,即偏移量提交的过于频繁及同步导致性能下降,而其他系统是异步执行的。我们还优化了 Kafka 消费者的 fetch-size 和复制线程,以消除在高吞吐量下获取消息的瓶颈,并配置了与其他系统相当的代理。
OMB RabbitMQ 驱动程序修复
我们增强了 RabbitMQ 以使用路由键和可配置的交换类型(DIRECT交换和TOPIC交换),还修复了 RabbitMQ 集群设置部署工作流中的一个 Bug。路由键被引入用来模仿主题分区的概念,实现与 Kafka 和 Pulsar 相当的设置。我们为 RabbitMQ 部署添加了一个 TimeSync 工作流,以同步客户端实例之间的时间,从而精确地测量端到端延迟。此外,我们还修复了 RabbitMQ 驱动程序中的另一个 Bug,以确保可以准确地测量端到端延迟。
OMB Pulsar 驱动程序修复
对于 OMB Pulsar 驱动程序,我们添加了为 Pulsar 生产者指定最大批次大小的功能,并关闭了那些在较高目标速率下、可能人为地限制跨分区生产者队列吞吐量的全局限制。我们不需要对 Pulsar 基准驱动程序做任何其他重大的更改。
4、测试平台
OMB 包含基准测试的测试平台定义(实例类型和 JVM 配置)和工作负载驱动程序配置(生产者 / 消费者配置和服务器端配置),我们将其用作测试的基础。所有测试都部署了四个驱动工作负载的工作者实例,三个代理 / 服务器实例,一个监视实例,以及一个可选的、供 Kafka 和 Pulsar 使用的三实例 Apache ZooKeeper 集群。在实验了几种实例类型之后,我们选定了网络 / 存储经过优化的 Amazon EC2 实例,它具有足够的 CPU 内核和网络带宽来支持磁盘 I/O 密集型工作负载。在本文接下来的部分,我们会列出我们在不同的测试中对这些基线配置所做的更改。
磁盘
具体来说,我们选择了i3en.2xlarge(8 vCore,64GB RAM,2x 2500 GB NVMe SSD),我们看中了它高达 25 Gbps 的网络传输限额,可以确保测试设置不受网络限制。这意味着这些测试可以测出相应服务器的最大性能指标,而不仅仅是网速多快。i3en.2xlarge实例在两块磁盘上支持高达 约 655 MB/s 的写吞吐量,这给服务器带来了很大的压力。有关详细信息,请参阅完整的 实例类型定义。根据一般建议和最初的 OMB 设置,Pulsar 把一个磁盘用于 journal,另一个用于 ledger 存储。Kafka 和 RabbitMQ 的磁盘设置没有变化。
总结:绘上一张Kakfa架构思维大纲脑图(xmind)
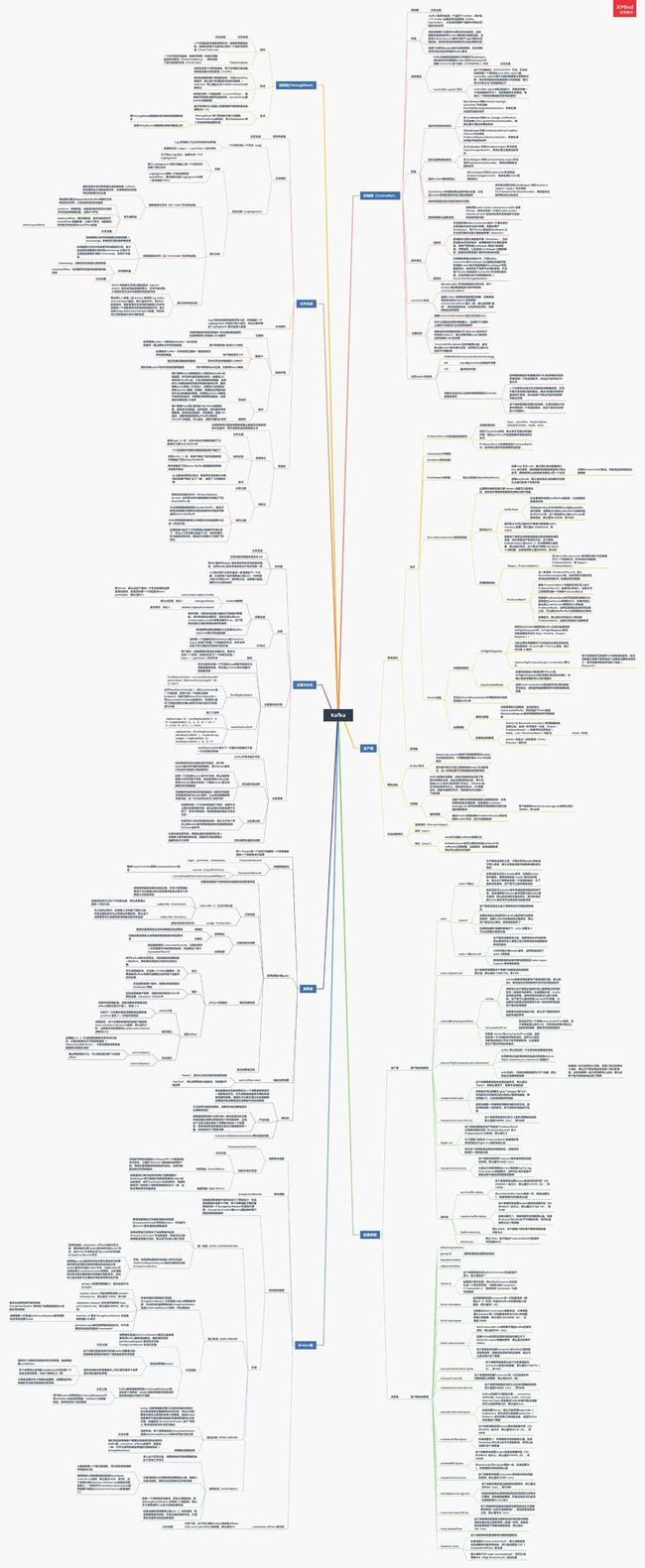
其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
资料领取方式:点击这里免费下载
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
[外链图片转存中…(img-VT3PT1y7-1623226492271)]