第4章 基本数据管理
目录
- 1、新变量创建、变量重编码&命名
-
- 新变量创建
- 变量重编码
- 变量重命名
- 2、操纵日期和缺失值
-
- 缺失值
-
- 符号表示与操作函数
- 处理缺失值的方法
- 日期值
-
- 将日期值转换为字符型变量
- 3、数据类型的转换
- 4、数据集的排序、合并与取子集
-
- 数据排序
- 数据集合并
-
- 添加列(增加变量)
- 添加行(增加观测)
- 5、选入和丢弃变量
-
- 保留变量
- 剔除变量
- 选入观测
- 函数subset()(简便方法)
- 随机抽样
实例分析:
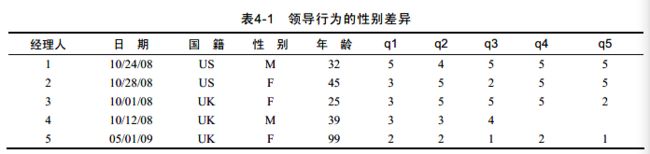
#创建leadership数据框
manager<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","US","UK","UK","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,25,39,99)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,5,NA,1)
leadership<-data.frame(manager,data,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
基本数据管理的常见任务:
- 处理不完整数据即缺失值
- 组合部分数据得到平均结果
- 选择感兴趣的变量重新创建一个简化的数据集
- 将连续型变量重编码为类别型的组变量
- 将分析范围限定在一定数据范围内(如时间段)进行分析
1、新变量创建、变量重编码&命名
新变量创建
目的:按需创建新变量并保存。即从数据框中已有的变量做运算,创建新变量并将其整合到原始的数据框中。
语句形式:变量名←表达式(包含多种运算符和函数,其中算术运算符可用于构造公式)

创建新变量的三种代码实现方式:
# 方法1:创建时使用符号$多次引用数据框中的对应变量
mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,2,8))
mydata$sumx<-mydata$x1+mydata$x2
mydata$meanx<-(mydata$x1+mydata$x2)/2
#方法2:使用attach()和detach()绑定和解绑数据框,避免多次使用$,更简便
attach(mydata)
mydata$sumx<-x1+x2
mydata$meanx<-(x1+x2)/2
detach(mydata)
#方法3:使用transform()函数,最简洁
mydata<-transform(mydata,sumx=x1+x2,meanx=(x1+x2)/2)
变量重编码
概念:根据同一个变量和/或其他变量的现有值来创建新值的过程。
具体情境:
- 将一个连续型变量修改为一组类别值
- 将错误编码的值替换为正确值
- 基于一组分数线创建一个表示及格/不及格的变量
需要用到R中的逻辑运算符:

使用前例:
#创建leadership数据框
manager<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","US","UK","UK","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,25,39,99)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,5,NA,1)
leadership<-data.frame(manager,data,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
# 将年龄99重编码为缺失值
leadership$age[leadership$age==99]<-NA
#创建agecat变量:对连续型的年龄变量进行分组
leadership$agecat[leadership$age>75)<-"Elder"
leadership$agecat[leadership$age>=55 & leadership$age<=75]<-"middle aged"
leadership$agecat[leadership$age<55)<-"Young"
# 创建agecat的另一简便方法
leadership<-within(leadership,{agecat<-NA,agecat[age>75]<-"Elder",agecat[age>=55&age<=75]<-"Middle aged",agecat[age<55]<-"Young"})
- 语句variable[condition]<-expression:仅在condition的值为TRUE时才执行赋值。
- 其他变量重编码函数:car包中的recode()函数(重编码数值型,字符型向量或因子);doBy包中的recodevar()函数;cut()函数(将一个数值型变量按值域切割成多个区间,并返回一个因子)

变量重命名
方法1:交互式编辑器
语句:fix(leadership)调用交互式编辑器,手动点击变量名修改
方法2:编程方式
reshape包中的**rename()**函数:首次使用需要安装
rename(dataframe,c(oldname=“newname”,oldname=“newname”,…))
方法3:names()函数
#按下标赋予新名
names(leadership)[2]<-"testDate"
#也可以根据下标批量命名
names(leadership)[6:10]<-c("item1","item2",...,"item5")
2、操纵日期和缺失值
缺失值
符号表示与操作函数
- 缺失值:符号NA(即Not Available,不可用)
- 不可能出现的值:符号NAN(即Not a Number,非数值)
- 在R中字符型和数值型数据使用的缺失值符号是相同的
- 函数is.na():检测缺失值是否存在
缺失值被认为是不可比较的,即不能使用==号来判断某个变量是否为NA(eg. y[4]==NA);智能使用处理缺失值的函数。
y<-c(1,2,3,NA)
is.na(y)
# is.na()函数会返回一个与所检测对象大小相同的对象,只不过对应的元素是TRUE或者FALSE
#当某个元素是缺失值则相应的位置改写为TRUE,反之则为FALSE
处理缺失值的方法
(1)重新编码某些值为缺失值
使用赋值语句将某些值重编码为缺失值。需要确保所有的缺失数据已经在分析之前已经妥善编码为缺失值。
leadership$age[leadership$age==99]<-NA
(2)在分析中排除缺失值
含有缺失值的算术表达式和函数的计算结果也是缺失值。所以找到并标记缺失值的位置之后,在进一步分析数据之前必须删除这些缺失值。
x<-c(1,2,NA,3)
y<-x[1]+x[3]
z=sum(x)
#这里y和z均是缺失值
- 数值函数的na.rm=选项(即remove NA):na.rm=TRUE表示在计算之前移除缺失值并使用剩余值进行计算。如sum()函数(help(sum))
- 函数na.omit():移除所有含有缺失值的观测,即删除所有含有缺失数据的行(相当于SPSS中的an系统剔除而非“按列/变量剔除”)
行删除(listwise deletion):删除所有含有缺失数据的观测
适用情境:只有少数缺失值或者缺失值仅集中于一小部分观测中,不适于缺失值遍布于数据中或一小部分变量在很多观测中都出现缺失值的模式。
日期值
目标:将日期值以字符串形式输入R,转化为以数值形式存储的日期变量。
函数as.Date():
语法 as.Date(x,“input_format”) 其中x是字符型数据,input_format给出用于读入日期的适当格式
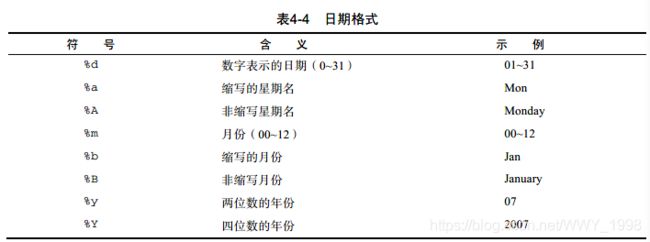
日期值的默认输入格式(即不设定input_format):yyyy-mm-dd
#默认格式
mydates<-as.Date(c("2007-06-22","2020-09-06"))
#设定读取模式
myformat<-"%m/%d/%y" #按照“月/日/年”读取
leadership$date<-as.Date(leadership$date,myformat)
(1)时间戳数据处理函数:
Sys.Date():返回当天的日期
date():返回当前的日期和时间
(2)可以使用函数format(x,format=“output_format”)来输出指定格式的日期值和提取日期中的某些部分。
函数format():可以接受一个参数并按照某种格式输出结果
today<-Sys.Date()
format(today,format="%B %d %Y") #以(非缩写月份,数字日期,四位数年份)格式输出今天的日期
format(today,format="%A") #仅提取出今天的非缩写星期名
可以在日期值上执行算术运算:
startdate<-as.Date("1998-02-04")
enddate<-as.Date("2020-09-06")
days<-enddate-startdate #得到差距天数
函数diffttime():计算时间间隔,并且用星期、天、时、分、秒表示
today<-Sys.Date()
sophie<-as.Date("1998-02-04")
difftime(today,sophie,units="days") #units=选项也可以写auto,weeks,secs,mins,hours其中一个
将日期值转换为字符型变量
函数as.character():将日期值转换为字符型(不太常用)
strDates<-as.Character(dates) #转换之后可对strDates使用一系列字符处理函数
help(as.Date) help(strftime)
3、数据类型的转换
向R中一个数值型向量添加一个字符串会将该向量的所有元素转换为字符型。

判断数据类型或将其转换为指定类型的函数:

解释:
is.datatype():返回TURE或FALSE
as.datatype():将其参数转换为对应的类型
4、数据集的排序、合并与取子集
数据排序
函数order():可以对一个数据框进行排序,默认的排序顺序是升序,在排序变量前加一个肩高也得到降序的排序结果。
#创建了一个新数据集,将各行依照经理人的年龄升序排序
newdata<-leadership[order(leadership$age),]
#嵌套排序
attach(leadership)
newdata<-leadership[order(gender,-age),] #按从女性→男性,同性别以年龄降序排列
detach(leadership)
数据集合并
添加列(增加变量)
函数merge():横向合并两个数据框(数据集)。多数情况下,两个数据框通过一个或多个共有变量进行联结(内联结,inner join)。
by=选项所指定的变量将会置于第一列,后面多列分别为两个数据框(如genderx,gendery)对应的观测
total<-merge(dataframeA,dataframeB,by="ID") #依照ID合并
函数cbind():直接横向合并两个对象,要求俩对象必须有相同的行数且以相同顺序排序
即col bind
total<-cbind(A,B)
添加行(增加观测)
函数rbind():纵向合并两个数据框(数据集)
即row bind
两个数据框必须变量(数量和种类)相同,但顺序未必相同。
如果不满足则须:
- 删除变量较多的数据框中的多余变量
- 在变量较少的数据框中追加变量并设置缺失值(NA)
total<-rbind(dataframeA,dataframeB)
用途:向数据框中添加观测。
5、选入和丢弃变量
保留变量
目的:从一个大数据集中选择有限数量的变量来创建一个新数据集。
切片法:dataframe[row indices,column indices]
mydata<-leadership[,c[6:10]]
#行下标留空,表示默认选择所有行
#列选择6-10列,即q1-q5
#等价实现
myvars<-paste("q",1:5,sep="") #paste()函数即粘贴,用于字符操作,很巧妙
newdata<-leadership<-leadership[myvars]
剔除变量
方法1:names()函数+逻辑运算“非!”
#剔除q3,q4
myvars<-names(leadership)%in%c("q3","q4")
newdata<-leadership[!myvars] # !myvars将逻辑向量反转
方法2:在某一列的下标之前加一个减号(-)就会剔除那一列
#按变量所处的列下标剔除
newdata<-leadership[c(-8,-9)]
方法3:设置为未定义(NULL)(与缺失NA不同)
leadership$q3<-leadership$q4<-NULL
#R允许连环赋值
选入观测
函数which():给出向量中值为TRUE元素的下标:如c(1,4)
newdata<-leadership[1:3,]
newdata<-leadership[which(leadership$gender=="M" & leadership$age>30),]
attach(leadership)
newdata<-leadership[which(gender=="M" & age>30),]
detach(leadership)
函数subset()(简便方法)
newdata<-subset(leadership,age>=35|age<24,select=c(q1,q2,q3,q4))
newdata<-subset(leadership,gender=="M"&age>25,select=gender:q4)
#select=gender:q4 表示选取从gender到q4之间(包含二者)的所有变量
随机抽样
函数sample():允许从数据集中(有放回或无放回)抽取大小为n的一个随机样本
mysample<-leadership[sample(1:nrow(leadership),3,replace=FALSE]
#第一个参数:由要从中抽样的元素组成的向量。本例是所有观测
#第二个参数:要抽取的元素数量
#第三个参数:replace=FALSE表示无放回抽样
备注:SQL语句通过sqldf包sqldf()等函数也可以在R中运行