Node.js高级编程【一】node 基础
目录
一、Node 基础
1、课程概述
2、Node.js 架构
3、为什么是Node.js ?
4、Node.js 的 异步IO
5、Node.js 主线程是单线程
6、Node.js 应用场景
7、 Nodejs实现API服务
8、Node.js 全局对象
9、Node.js 常见全局变量
10、全局变量之 process
二、核心模块
1、内置模块之 PATH(用于处理文件/目录的路径)
2、全局变量之 Buffer
3、FS 模块
4、文件的打开与操作
5、大文件读写操作
6、 文件拷贝自定义实现
7、FS 之目录操作 API
8、创建目录之同步实现
9、 目录创建之异步实现
10、目录删除之异步实现
11、模块化历程
12、Commonjs 规范
13、 Nodejs与CommonJS
14、模块分类及加载流程
15、模块加载源码分析
16、内置模块之 VM 模块
17、模块加载模拟实现
18、核心模块之 Events
19、浏览器中的 Eventloop 事件环
20、Nodejs 下的事件环
一、Node 基础
1、课程概述
Node.js可以做什么 ?

2、Node.js 架构

- Native modules

- Builtin modules "胶水层"

- 底层


3、为什么是Node.js ?
Node 慢慢演化为一门服务端“语言”
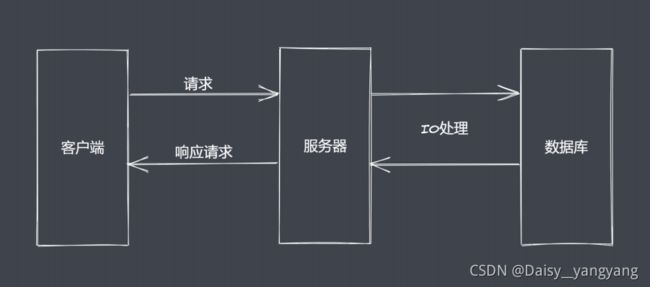
IO 是计算过程操作过程中最缓慢的环节
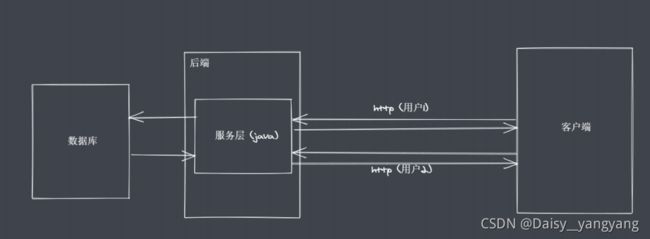
Reactor 模式,单线程完成多线程工作
Reactor 模式下实现异步IO、事件驱动
Node.js 更适用于 IO 密集型高并发请求
4、Node.js 的 异步IO
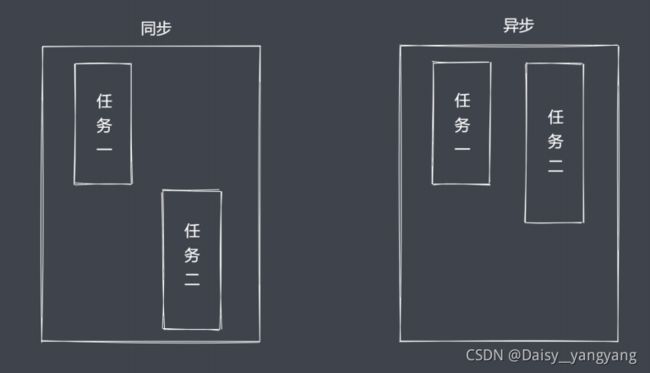
分为非阻塞 IO 和阻塞 IO
重复调用 IO 操作,判断 IO 是否结束
read、select 、poll、kqueue、event ports
期望实现无须主动判断非阻塞 IO

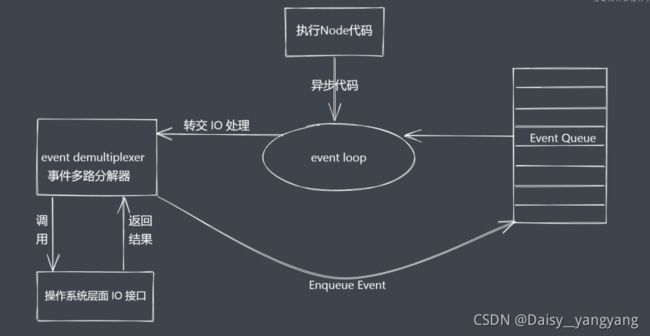 异步 IO 总结
异步 IO 总结
- IO 是应用程序的瓶颈所在
- 异步 IO 提高性能无采原地等待结果返回
- IO 操作属于操作系统级别,平台都有对应实现
- Node.js 单线程配合事件驱动架构及 libuv 实现了异步 IO
5、Node.js 主线程是单线程
6、Node.js 应用场景
IO 密集型高并发请求
Node.js 作为中间层
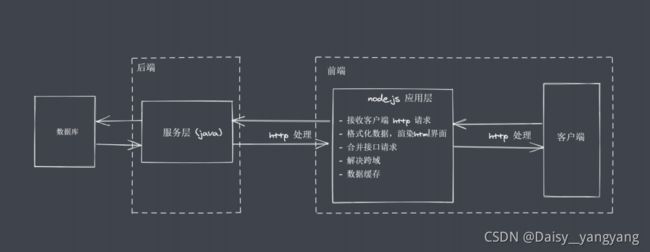
操作数据库提供API服务
实时聊天应用程序
Node.js 更加适合 IO 密集型任务
7、 Nodejs实现API服务
(1)npm init -y
(2)npm i typescript -g
(3)tsc --init
(4)npm i ts-node -D // 用于运行 ts 脚本
(5)npm i express
(6)npm i @types/express -D // 用于编译 ts 中未定义的变量
(7)编写 api_server.ts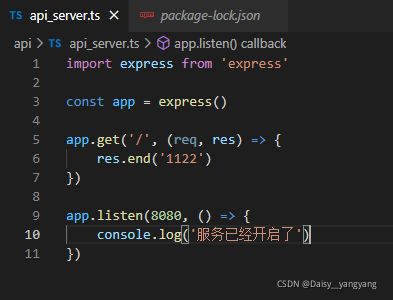
(8)启动文件 ts-node .\api_server.ts
8、Node.js 全局对象
- 与浏览器平台的 window 不完全相同
- Node.js 全局对象上挂载许多属性
全局对象是 Javascript 中的特殊对象
Node.js 中全局对象是 global
Global 的根本作用就是作为宿主
全局对象可以看作是全局变量的宿主
9、Node.js 常见全局变量
- __filename:返回正在执行脚本文件的绝对路径
- __dirname:返回正在执行脚本所在目录
- timer 类函数:执行顺序与事件循环间的关系
- process:提供与当前接口互动的接口
- require:实现模块的加载
- module、exports:处理模块的导出
10、全局变量之 process
- 无需 require 可直接使用
- 获取进程信息
- 执行进程操作
(1)资源:CPU 内存
console.log(process.memoryUsage())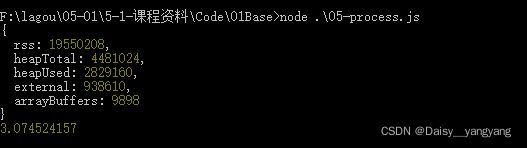
console.log(process.cpuUsage())![]()
(2)运行环境
- process.cwd() // 运行目录
-
process.version // 运行版本 process.versions // 详细的运行版本
-
process.arch // cpu架构
-
process.env.NODE_ENV // node环境
-
process.env.PATH // 路径
-
process.env.USERPROFILE // 用户环境 mac是HOME
-
process.platform // 系统平台
(3)运行状态
-
process.argv // 启动参数
-
process.argv0 // 获取第一个启动参数
-
process.pid // PID
-
process.uptime // 运行时间
(4)事件
process.on('beforeExit', (code) => {
console.log('before exit' + code)
})
process.on('exit', (code) => { // 退出程序
console.log('exit' + code)
})
console.log('代码执行完了')
process.exit()
// 代码执行完了
// exit0(5)标准输出 输入 错误
console.log = function(data) {
process.stdout.write('---' + data + '\n')
}
console.log(11)
console.log(22)
// 11
// 22const fs = require('fs')
fs.createReadStream('test.txt') //读取文件内容
.pipe(process.stdout)
// 拉钩教育
process.stdin.pipe(process.stdout) // 自定义输入输出
// 123
// 123
process.stdin.setEncoding('utf-8') // 自定义文本格式输入输出
process.stdin.on('readable', () => {
let chunk = process.stdin.read()
if (chunk !== null) {
process.stdout.write('data' + chunk)
}
})
// 123
// data123二、核心模块
1、内置模块之 PATH(用于处理文件/目录的路径)
path 模块中常见的 API
- basename() 获取路径中基础名称‘
const path = require('path')
console.log(__filename); // F:\lagou\05-01\5-1-课程资料\Code\01Base\06-path.js
// 1 获取路径中的基础名称
// 01 返回的就是接收路径当中的最后一部分
// 02 第二个参数表示扩展名,如果说没有设置则返回完整的文件名称带后缀
// 03 第二个参数作为后缀时,如果没有在当前路径中被匹配到,那么就被会忽略
// 04 处理目录路径的是哦胡如果说,结尾处有路径分隔符,则也会被忽略掉
console.log(path.basename(__filename)); // 06-path.js
console.log(path.basename(__filename, '.js')); // 06-path
console.log(path.basename(__filename, '.css')); // 06-path.js
console.log(path.basename('a/b/c')); // c
console.log(path.basename('a/b/c/')); // c- dirname() 获取路径中目录名称
// 2、获取路径目录名(路径)
// 01 返回路径中最后一个部分的上一层目录所在路径
console.log(path.dirname(__filename)) // F:\lagou\05-01\5-1-课程资料\Code\01Base
console.log(path.dirname('a/b/c')) // a/b
console.log(path.dirname('a/b/c/')) // a/b
- extname() 获取路径中扩展名称
// 3、获取路径的扩展名
// 01 返回 path 路径中相应文件的后缀名
// 02 如果 path 路径当中存在多个点,它匹配的是最后一个点,到结尾的内容
console.log(path.extname(__filename)); // .js
console.log(path.extname('a/b')); // 空
console.log(path.extname('a/b/index.html.js.css')); // .css
console.log(path.extname('a/b/index.js.')); // .- isAbsolute() 获取路径是否为绝对路径
// 6、判断当前路径是否为绝对
console.log(path.isAbsolute('foo')); // false
console.log(path.isAbsolute('/foo')); // true
console.log(path.isAbsolute('///foo')); // true
console.log(path.isAbsolute('')); // false
console.log(path.isAbsolute('.')); // false
console.log(path.isAbsolute('../bar')); // false- join() 拼接多个路径片段
// 7、拼接路径
console.log(path.join('a/b', 'c', 'index.html')); // a\b\c\index.html
console.log(path.join('/a/b', 'c', 'index.html')); // \a\b\c\index.html
console.log(path.join('/a/b', 'c', '../', 'index.html')); // \a\b\index.html
console.log(path.join('a/b', 'c', './', 'index.html')); // a\b\c\index.html
console.log(path.join('a/b', 'c', '', 'index.html')); // a\b\c\index.html
console.log(path.join('')); // .- resolve() 返回绝对路径
// 9、绝对路径
// console.log(path.resolve());
// resolve([from], to)
console.log(path.resolve('/a', '../b')); // \b 和 a没有关系
console.log(path.resolve('index.html')); // F:\lagou\05-01\5-1-课程资料\Code\01Base\index.html- parse() 解析路径
// 4、解析路径
// 01 接受一个路径,返回一个对象,包含不同的信息
// 02 root dir base ext name
const obj = path.parse('a/b/c/index.html')
// {
// root: '',
// dir: 'a/b/c',
// base: 'index.html',
// ext: '.html',
// name: 'index'
// }
const obj = path.parse('a/b/c/')
// { root: '', dir: 'a/b', base: 'c', ext: '', name: 'c' }
const obj = path.parse('./a/b/c/')
// { root: '', dir: './a/b', base: 'c', ext: '', name: 'c' }
console.log(obj)- format() 序列化路径
// 5、序列化路径
const obj = path.parse('./a/b/c/')
console.log(path.format(obj)) // ./a/b\c- normalize() 规范化路径
// 8、规范化路径
console.log(path.normalize('')); // .
console.log(path.normalize('a/b/c/d')); // a\b\c\d
console.log(path.normalize('a///b/c../d')); // a\b\c..\d
console.log(path.normalize('a//\\/b/c\\/d')); // a\b\c\d
console.log(path.normalize('a//\b/c\\/d')); // a\c\d2、全局变量之 Buffer
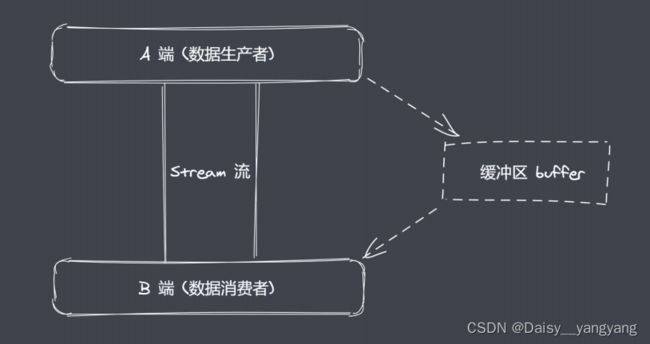
Buffer 缓冲区
Buffer 让 Javascript 可以操作二进制
Javascript 语言起初服务于浏览器平台
Nodejs 平台下 Javascript 可实现 IO
IO 行为操作的就是二进制数据
Stream 流操作并非 Nodejs 独创
流操作配合管道实现数据分段传输
数据的端到端传输会有生产者和消费者
生产和消费的过程往往存在等待
产生等待时数据存放在哪?Nodejs 中 Buffer是一片内存空间
(1)Buffer 总结
- 无须 require 的一个全局变量
- 实现 Nodejs 平台下的二进制数据操作
- 不占据 V8 对内存大小的内存空间
- 内存的使用由 Node 来控制,由V8 的 GC 回收
- 一般配合 Stream 流使用,充当数据缓冲区
(2)创建 Bufffer
- alloc:创建制定字节大小的 buffer
- allocUnsafe:创建制定大小的 buffer (不安全)
- from:接收数据,创建 buffer
const b1 = Buffer.alloc(10) //
const b2 = Buffer.allocUnsafe(10) //
console.log(b1);
// from
const b1 = Buffer.from('1')
console.log(b1); //
const b1 = Buffer.from('中')
console.log(b1); //
const b1 = Buffer.from([1, 2, '中'], 'utf8')
console.log(b1); //
const b1 = Buffer.from([0xe4, 0xb8, 0xad]) // 建议不要放非数组的内容,直接放数组
console.log(b1); //
console.log(b1.toString()); // 中
const b1 = Buffer.alloc(3)
const b2 = Buffer.from(b1)
console.log(b1) //
console.log(b2) //
// 测试 b1 和 b2 是不是共享内存,结果显示不共享内粗
b1[0] = 1
console.log(b1) //
console.log(b2) // (3)Buffer 实例方法
- fill:使用数据填充 buffer
let buf = Buffer.alloc(6)
// fill 里面有三个参数 (值, 起始位置, 结束位置)
buf.fill('123')
console.log(buf); //
console.log(buf.toString()); // 123123 - write:向 buffer 中写入数据
// write
buf.write('123', 1, 4)
console.log(buf); //
console.log(buf.toString()); // 123 - toString:从 buffer 中提取数据
// toString()
buf = Buffer.from('拉钩教育')
console.log(buf) // 12个字节
console.log(buf.toString('utf-8', 3, 9)) // 钩教 取得第三个到第九个字节,一个汉字占3个字节 - slice:截取 buffer
// slice
buf = Buffer.from('拉钩教育')
let b1 = buf.slice(-3)
console.log(b1) //
console.log(b1.toString()); // 育 - indexOf:在 buffer 中查找数据
// indexOf
buf = Buffer.from('ace爱前端,爱拉钩教育,爱大家')
console.log(buf); //
console.log(buf.indexOf('爱', 4)); // 15 - copy:拷贝 buffer 中的数据
// copy
let b1 = Buffer.alloc(6)
let b2 = Buffer.from('拉钩')
b2.copy(b1, 3, 3, 6) // 后面的参数读取顺序是从第三个字节,从第三个字节接着读
console.log(b1.toString()); // 钩
console.log(b2.toString()); // 拉钩(3)Buffer 静态方法
- concat:将多个 buffer 拼接成一个新的 buffer
let b1 = Buffer.from('拉钩')
let b2 = Buffer.from('教育')
let b = Buffer.concat([b1, b2], 9)
console.log(b); //
console.log(b.toString()); // 拉钩教 - isBuffer:判断当前数据是否为 buffer
let b1 = '123'
console.log(Buffer.isBuffer(b1)); // false
let b2 = Buffer.alloc(123)
console.log(Buffer.isBuffer(b2)); // true(4)自定义 Buffer 之 spilt
ArrayBuffer.prototype.split = function (sep) {
let len = Buffer.from(sep).length
let ret = []
let start = 0
let offset = 0
while( offset = this.indexOf(sep, start) !== -1 ) {
ret.push(this.slice(start, offset))
start = offset + len
}
ret.push(this.slice(start))
return ret
}
let buf = 'ace吃馒头,吃面条,我吃好吃的'
let bufArr = buf.split('吃')
console.log(bufArr); // [ 'ace', '馒头,', '面条,我', '好', '的' ]3、FS 模块
- 一个是缓冲区,一个是数据流
- FS 是内置核心模块,提供文件系统操作的 API

- FS 基本操作类
- FS 常用 API
- 权限位、标识符、文件描述符
- 用于对于文件所具备的操作权限


- Nodejs 中 flag 表示对文件操作方式
- 常见 flag 操作符
- r:表示可读
- w:表示可写
- s:表示同步
- +:表示执行相反操作
- x:表示排它操作
- a:表示追加操作
- fd 就是操作系统分配给被打开文件的标识
fs 介绍总结
- fs 是 Nodejs 中内置核心模块
- 代码层面上 fs 分为基本操作类和常用 API
- 权限位、标识符、操作符
4、文件的打开与操作
- fs.open(path, flags, [mode], [callback(err,fd)])
- path 文件路径
- flags 可以是以下的值
- 'r' - 以读取模式打开文件
- 'r+' - 以读写模式打开文件
- 'rs' - 使用同步模式打开并读取文件。指示操作系统忽略本地文件系统缓存
- 'rs+' - 以同步的方式打开,读取 并 写入文件
- 注意:这不是让fs.open变成同步模式的阻塞操作。如果想要同步模式请使用fs.openSync()。
- 'w' - 以读取模式打开文件,如果文件不存在则创建
- 'wx' - 和 ' w ' 模式一样,如果文件存在则返回失败
- 'w+' - 以读写模式打开文件,如果文件不存在则创建
- 'wx+' - 和 ' w+ ' 模式一样,如果文件存在则返回失败
- 'a' - 以追加模式打开文件,如果文件不存在则创建
- 'ax' - 和 ' a ' 模式一样,如果文件存在则返回失败
- 'a+' - 以读取追加模式打开文件,如果文件不存在则创建
- 'ax+' - 和 ' a+ ' 模式一样,如果文件存在则返回失败
- mode 用于创建文件时给文件制定权限,默认0666
- callback 回调函数会传递一个文件描述符 fd ,和一个异常err
const fs = require('fs')
const path = require('path')
// open
fs.open(path.resolve('data.txt'), 'r', (err, fd) => {
console.log(fd);
})
// 3
// close
fs.open('data.txt', 'r', (err, fd) => {
console.log(fd);
fs.close(fd, err => {
console.log('关闭成功');
})
})
// 3
// 关闭成功
5、大文件读写操作

A文件要把内容复制到B文件里, 需要一个内存来暂存内容,边读边写,可以用Buffer来实现,避免直接复制过去造成内存的溢出。
const fs = require('fs')
// read : 所谓的读操作就是将数据从磁盘文件中写入到 buffer 中
let buff = Buffer.alloc(10)
/**
* fd 定位当前被打开的文件
* rfd 文件标识符
* buf 用于表示当前缓冲区
* offset 表示当前从 buf 的哪个位置开始执行写入
* length 表示当前写入的长度
* position 表示当前从文件的那个位置开始读取
*/
fs.open('data.txt', 'r', (err, rfd) => {
console.log(rfd); // 3
fs.read(rfd, buff, 0, 4, 3, (err, readBytes, data) => {
console.log(readBytes); // 4
console.log(data); //
console.log(data.toString()); // 4567
})
})
buf = Buffer.from('1234567890')
fs.open('b1.txt', 'w', (err, wfd) => {
/**
* wfd 文件标识符
* buf 存放数据的缓存区
* 1 第一个位置是从 buffer 的哪个位置取数据
* 4 表示具体写多少个长度
* 0 表示从文件的哪个位置执行写操作,一版从0开始执行写操作
*/
fs.write(wfd, buf, 1, 4, 0, (err, written, buffer) => {
console.log(written, '----'); // 4 ----
fs.close(wfd) // 记得关闭文件,减少内存的占用
})
})
// 会生成一个 b1.txt 文件,内容是 2345 6、 文件拷贝自定义实现
const fs = require('fs')
/**
* 01 打开 a 文件,利用 read将数据保存在 buffer 暂存起来
* 02 打开 b 文件,利用 write 将 buffer 中数据写入到 b 文件中
*/
let buf = Buffer.alloc(10)
// 01 打开制定的文件 拷贝10个字节
fs.open('a.txt', 'r', (err, rfd) => {
// 03 打开 B 文件,用于执行数据写入操作
fs.open('b.txt', 'w', (err, wfd) => {
// 02 从打开的文件中读取数
fs.read(rfd, buf, 0, 10, 0, (err, readBytes) => {
// 04 将 buffer 中的数据写入到 b.txt 中
fs.write(wfd, buf, 0, 10, 0, (err, writter) =>{
console.log('写入成功');
})
})
})
})
// 02 数据的完全拷贝
// fs.open('a.txt', 'r', (err, rfd) => {
// fs.open('b.txt', 'w', (err, wfd) => {
// fs.read(rfd, buf, 0, 10, 0, (err, readBytes) => {
// fs.write(wfd, buf, 0, 10, 0, (err, writter) =>{
// fs.read(rfd, buf, 0, 5, 10, (err, readBytes) => {
// fs.write(wfd, buf, 0, 5, 10, (err,writter) => {
// console.log('写入成功')
// })
// })
// })
// })
// })
// })
const BUFFER_SIZE = buf.length
let readOffset = 0
fs.open('a.txt', 'r', (err, rfd) => {
fs.open('b.txt', 'w', (err, wfd) => {
function next() {
fs.read(rfd, buf, 0, BUFFER_SIZE, readOffset, (err, readBytes) => {
if (!readBytes) {
// 如果条件成立,说明内容已经读取完毕
fs.close(rfd, () => {})
fs.close(wfd, () => {})
console.log('拷贝完成')
return
}
readOffset += readBytes
fs.write(wfd, buf, 0, readBytes, (err, writter) => {
next()
})
})
}
next()
})
})
// 生成一个 b.txt 文件,内容为A的内容7、FS 之目录操作 API
常见目录操作 API
- access:判断文件或目录是否具有操作权限
const fs = require('fs')
// 一、access
fs.access('a.txt', (err) => {
if (err) {
console.log(err);
} else {
console.log('有操作权限');
}
})
// 有操作权限- stat:获取目录及文件信息
// 二、stat
fs.stat('a.txt', (err, statObj) => {
console.log(statObj.size); // 108
console.log(statObj.isFile()); // true
console.log(statObj.isDirectory()); // false
})- mkdir:创建目录
// 三、mkdir recursive 递归操作
fs.mkdir('a/b/c', {recursive: true}, (err) => {
if (!err) {
console.log('创建成功');
} else {
console.log(err);
}
})- rmdir:删除目录
// 四、rmdir
fs.rmdir('a', {recursive: true}, (err) => {
if (!err) {
console.log('删除成功');
} else {
console.log(err);
}
})- readdir:读取目录中内容
// 五、readdir
fs.readdir('a', (err, files) => {
console.log(files); // [ 'a.txt', 'b' ]
})- unlink:删除指定文件
// 六、unlink
fs.unlink('a/a.txt', (err) => {
if (!err) {
console.log('删除成功');
} else {
console.log(err);
}
})8、创建目录之同步实现
const fs = require('fs')
const path = require('path')
/**
* 01 将来调用时需要接收类似于 a/b/c,这样的路径,他们之间是采用 / 去进行连接
* 02 利用 / 分割符将路径进行拆分,将每一项放入一个数组中进行管理 ['a', 'b', 'c']
* 03 对上述的数组进行遍历,我们需要拿到每一项,然后与前一项进行拼接 /
* 04 判断一个当前对拼接之后的路径是否具有可操作的权限,如果有则证明存在,否则的话需要执行创建
*/
function makeDirSync (dirPath) {
let items = dirPath.split(path.sep)
for(let i = 1; i <= items.length; i++) {
let dir = items.slice(0, i).join(path.sep)
try {
fs.accessSync(dir)
} catch (err) {
fs.mkdirSync(dir)
}
}
}
makeDirSync('a\\b\\c')9、 目录创建之异步实现
const fs = require('fs')
const path = require('path')
function mkDir (dirPath, cb) {
let parts = dirPath.split('/')
let index = 1
function next () {
if (index > parts.length) return cb && cb()
let current = parts.slice(0, index++).join('/')
fs.access(current, (err) => {
if (err) {
fs.mkdir(current, next)
} else {
next()
}
})
}
next()
}
mkDir('a/b/c', () => {
console.log('创建成功');
})10、目录删除之异步实现
const { dir } = require('console')
const fs = require('fs')
const path = require('path')
/**
* 需求:自定义一个函数,接受一个路径,然后执行删除
* 01 判断当前传入的路径是否为一个文件,直接删除当前文件即可
* 02 如果当前传入的是一个目录,我们需要继续读取目录中的内容,然后再执行删除操作
* 03 将删除行为定义成一个函数,然后通过递归的方式进行复用
* 04 将当前的名称拼接成在删除时可使用的路径
*/
function myRmdir (dirPath, cb) {
// 判断当前 dirPath 的类型
fs.stat(dirPath, (err, statObj) => {
if (statObj.isDirectory()) {
// 目录 ---> 继续读取
fs.readdir(dirPath, (err, files) => {
let dirs = files.map(item => {
return path.join(dirPath, item)
})
let index = 0
function next () {
if (index === dirs.length) return fs.rmdir(dirPath, cb)
let current = dirs[index++]
myRmdir(current, next)
}
next ()
})
} else {
// 文件 ---> 直接删除
fs.unlink(dirPath, cb)
}
})
}
myRmdir('tmp', () => {
console.log('删除成功了');
})11、模块化历程
(1)前端开发为什么需要模块化?
组件化前端开发
a、传统开发常见问题
- 命名冲突和污染
- 代码冗余,无效请求多
- 文件间的以来关系复杂
b、项目难以维护不方便复用
c、模块小而精且利于维护代码片段
d、利用函数、对象、自执行函数实现分块
(2)常见模块化规范
- Commonjs 规范
- AMD 规范
- CMD 规范
- ES mdules 规范
(3)模块化规范
- 模块化是前端走向工程化中的重要一环
- 早期 JavaScript 语言层面没有模块化规范
- Commonjs、AMD、CMD都是模块化规范
- ES6 中将模块化纳入标准规范
- 当下常用规范是 Commonjs 与 ESM
12、Commonjs 规范
Commonjs 规范主要应用于 Node.js
Commonjs 是语言层面上的规范i
- 模块尹用
- 模块定义
- 模块标识
(1)Nodejs 与 Commonjs
- 任意一个文件就是一模块,具有独立作用域
- 使用 require 导入其他模块
- 将模块 ID 传入 require 实现目标模块定位
(2)module 属性
- 任意 js 文件就是一个模块,可以直接使用 module 属性
- id:返回模块标识符,一般是一个绝对路径
- filename:返回文件模块的绝对路径
- loaded:返回布尔值,表示模块是否完成加载
- parent:返回对象调用房前模块的模块
- childern:返回数组,存放当前模块调用的其他模块
- exports:返回当前模块需要暴露的内容
- paths:返回数组,存放不同目录下的 node_modules 位置
(3)module,exports 与 exports 有何区别?


(4)require 属性
- 基本功能是读入并且执行一个模块文件
- resolve:返回模块文件绝对路径
- extensions:依据不同后缀名执行解析操作
- main:返回主模块对象
(5)CommonJs 规范
- CommonJs 规范是为了弥补 JS 语言模块化缺陷
- CommonJs 是语言层面的规范,当前主要用于 Node.js
- CommonJs 规定模块化分为引入、定义、标识符三部分
- Module 在任意模块中可直接使用包含模块信息
- require 接收标识符,加载目标模块
- Exports 与 module.exports 都能导出模块数据
- CommonJs 规范定义模块的加载是同步完成
13、 Nodejs与CommonJS
- 使用 module.exports 与 require 实现模块导入与导出
// 文件 01.js
// 一、导入
let obj = require('./m')
console.log(obj); // { age: 20, agefn: [Function: ageFn] }// 文件 m.js
// 一、模块的导入与导出
const age = 20
const ageFn = (x, y) =>{
return x + y
}
module.exports = {
age: age,
agefn:ageFn
}- module 属性及其常见信息获取
// 文件 01.js
// 二、module导入
let obj = require('./m')
console.log(obj);
// 文件 m.js
// 二、module 导出
module.exports = 111
console.log(module);
// Module {
// id: '.',
// path: 'F:\\lagou\\05-01\\5-1-课程资料\\Code\\04FS\\05Modules',
// exports: 111,
// parent: null,
// filename: 'F:\\lagou\\05-01\\5-1-课程资料\\Code\\04FS\\05Modules\\m.js',
// loaded: false,
// children: [],
// paths: [
// 'F:\\lagou\\05-01\\5-1-课程资料\\Code\\04FS\\05Modules\\node_modules',
// 'F:\\lagou\\05-01\\5-1-课程资料\\Code\\04FS\\node_modules',
// 'F:\\lagou\\05-01\\5-1-课程资料\\Code\\node_modules',
// 'F:\\lagou\\05-01\\5-1-课程资料\\node_modules',
// 'F:\\lagou\\05-01\\node_modules',
// 'F:\\lagou\\node_modules',
// 'F:\\node_modules'
// ]
// }- exports 导出数据及其与 module.exports 区别(不能给exports直接赋值)
// 文件 01.js
// 三、exports
let obj = require('./m')
console.log(obj); // { name: 'ace' }// 文件 m.js
//三、exports
exports.name = 'ace'- CommonJS 规范下的模块同步加载
// 文件 01.js
//四、同步加载
let obj = require('./m')
console.log('01.js 代码执行了')
// m.js被加载导入了
// 01.js 代码执行了
let obj = require('./m')
console.log(require.main == module); //true
// false
// true// 文件 m.js
// 四、同步加载
let name = 'lg'
let iTime = new Date()
while(new Date() - iTime < 4000) {}
module.exports = name
console.log('m.js被加载导入了');
console.log(require.main == module); // false14、模块分类及加载流程
(1)模块分类
- 内置模块
- 文件模块
(2)模块加载速度
- 核心模块:Node 源码编译时写入到二妗子和文件中
- 文件模块:代码运行时,动态加载
(3)加载流程
- 路径分析:依据标识符确定模块位置
- 文件定位:确定目标模块中具体的文件及文件类型
- 编译执行:采用对应的方式完成文件的编译执行
(4)路径分析之标识符
- 路径标识符
- 非路径标识符(非路径常见于核心模块)
(5)文件定位

(6)编译执行
- 将某个具体类型的文件按照相应的方式进行编译和执行
- 创建新对象,按路径载入,完成编译执行
(7)JS文件的编译执行

(8)JSON 文件编译执行
将读取到的内容通过 JSON.parse() 进行解析
(9)缓存优化原则
- 提高模块加载速度
- 当前模块不存在,则经历一次完整加载流程
- 模块加载完成厚,使用路径作为索引进行缓存
(10)加载流程小结
- 路径分析:确定目标模块位置
- 文件定位:确定目标模块中的具体文件
- 编译执行:对模块内容进行编译,返回可用 exports 对象
15、模块加载源码分析
用 vscode 调试查看require孕妈
16、内置模块之 VM 模块
创建独立的沙箱环境
// text.txt
var age = 19// vm.js
const fs = require('fs')
const vm = require('vm')
let age = 33
let content = fs.readFileSync('text.txt', 'utf-8')
// eval
eval(content) // 19 如果又声明 age ,就会报错,变量已声明,不适用
console.log(age);
// new Function
console.log(age); // 33
let fn = new Function('age', 'return age + 1') // 34
console.log(fn(age));
// vm
vm.runInThisContext(content) //33
age = 33
vm.runInThisContext('age += 10') // 29
console.log(age)17、模块加载模拟实现
核心逻辑
- 路径分析
- 缓存优先
- 文件定位
- 编译执行
// v.json 文件
{
"age":18
}
// 或者 v.js
const age = 18
module.exports = name
// 模拟模块加载实现
const fs = require('fs')
const path = require('path')
const vm = require('vm')
function Module (id) {
this.id = id
this.exports = {}
console.log(1111)
}
Module._resolveFilename = function (filename) {
// 利用 Path 将 filename 转为绝对路径
let absPath = path.resolve(__dirname, filename)
// 判断当前路径对应的内容是否存在()
if (fs.existsSync(absPath)) {
// 如果条件成立则说明 absPath 对应的内容是存在的
return absPath
} else {
// 文件定位
let suffix = Object.keys(Module._extensions)
for(var i=0; i18、核心模块之 Events
(1)通过 EventEmitter 类实现事件统一管理
(2)events 与 EventEmitter
- node.js 是基于时间驱动的异步操作架构,内置 events 模块
- events 模块提供了 EventEmitter 类
- node.js 中很多内置核心模块继承 EventEmitter
(3)EventEmitter 常见 API
- on:添加当事件被触发时调用的回调函数
- emit:触发事件,按照注册的序同步调用每个事件监听器
const EventEmitter = require('events')
const ev = new EventEmitter()
// on
ev.on('事件1', () => {
console.log('事件1执行了');
})
ev.on('事件1', () => {
console.log('事件1执行了---2');
})
// emit
// ev.emit('事件1')
// ev.emit('事件1')
//事件1执行了
// 事件1执行了---2
//事件1执行了
// 事件1执行了---2- once:添加当事件在注册之后首次被触发时调用的回调函数
// once
ev.once('事件1', () => {
console.log('事件1执行了');
})
ev.once('事件1', () => {
console.log('事件1执行了---2');
})
// emit
ev.emit('事件1')
ev.emit('事件1')
//事件1执行了
// 事件1执行了---2- off:移除特定的监听器
// off
let cbFn = (...args) => {
console.log(args); // [ 1, 2, 3 ]
}
ev.on('事件1', cbFn)
// ev.off('事件1', cbFn)
ev.emit('事件1', 1, 2, 3)18、发布订阅
(1)定义对象间一对多的关系
(2)发布订阅可以解决什么问题?

(3)发布订阅要素
- 缓存队列,存放订阅者信息
- 具有增加、删除订阅的能力
- 状态改变时通知所有订阅者执行监听
(4)发布订阅中存在调度中心
(5)状态发生改变时,发布订阅者无须主动通知
(6)EventEmitter模拟
function MyEvent () {
// 准备一个数据结构用于缓存订阅者信息
this._events = Object.create(null)
}
MyEvent.prototype.on = function (type, callback) {
// 判断当前次的事件是否已经存在,然后再决定如果做缓存
if (this._events[type]) {
this._events[type].push(callback)
} else {
this._events[type] = [callback]
}
}
MyEvent.prototype.emit = function (type, ...args) {
if (this._events && this._events[type].length) {
this._events[type].forEach((callback) => {
callback.call(this, ...args)
})
}
}
MyEvent.prototype.off = function (type, callback) {
// 判断当前 type 事件监听是否存在,如果存在则取消指定的监听
if (this._events && this._events[type]) {
this._events[type] = this._events[type].filter((item) => {
return item !== callback && item.link !== callback
})
}
}
MyEvent.prototype.once = function (type, callback) {
let foo = function (...args) {
callback.call(this, ...args)
this.off(type, foo)
}
foo.link = callback
this.on(type, foo)
}
let ev = new MyEvent()
let fn = function (...data) {
console.log('事件1执行了', data);
}
// ev.on('事件1', fn)
// ev.on('事件1', () => {
// console.log('事件1---2');
// })
// ev.emit('事件1', 1, 2)
// ev.emit('事件1', 1, 2)
// 事件1执行了 [ 1, 2 ]
// 事件1---2
// 事件1执行了 [ 1, 2 ]
// ev.on('事件1', fn)
// ev.emit('事件1', '前')
// ev.off('事件1', fn)
// ev.emit('事件1', '后')
// 事件1执行了 [ '前' ]
ev.once('事件1', fn)
ev.off('事件1', fn)
// ev.emit('事件1', '前')
ev.emit('事件1', '后')
// 1
// 事件1执行了 [ '前' ]19、浏览器中的 Eventloop 事件环
setTimeout(() => {
console.log('s1');
Promise.resolve().then(() => {
console.log('p1');
})
Promise.resolve().then(() => {
console.log('p2');
})
})
setTimeout(() => {
console.log('s2');
Promise.resolve().then(() => {
console.log('p3');
})
Promise.resolve().then(() => {
console.log('p4');
})
})
// s1 p1 p2 s2 p3 p4完整事件环执行顺序
- 从上至下执行所有的同步代码
- 执行过程中将遇到的宏任务与微任务添加至相应的队列
- 同步代码执行完毕后,执行满足条件的微任务回调
- 微任务队列执行完毕后执行所有满足需求的宏任务回调
- 循环事件环操作
注意:每执行一个宏任务之后就会立刻检查微任务对列
setTimeout(() => {
console.log('s1');
Promise.resolve().then(() => {
console.log('p2');
})
Promise.resolve().then(() => {
console.log('p3');
})
})
Promise.resolve().then(() => {
console.log('p1');
setTimeout(() => {
console.log('s2');
})
setTimeout(() => {
console.log('s3');
})
})
// p1 s1 p2 p3 s2 s3
/**
* 执行顺序
* (1)代码从上到下同步执行,先遇到 setTimeout,放入宏任务记为 s1事件(暂不执行里面的代码);接下来遇到 Promise,放入到微任务记为 p1事件(暂不执行里面的代码),第一次代码执行结束;
* 然后进入到微任务看一下是否有执行的代码,发现有 p1 事件
* 输出 p1
* (2)然后 p1 事件执行结束后,从上到下执行,发现里面有两个宏任务,分别记为 s2事件、s3事件,放到宏任务列表中,现在宏任务列表排序为 s1、s2、s3,这样微任务 p1 事件就算执行完成了
* 微任务 p1 事件执行结束,微任务队列清空
* (3)现在切换到宏任务队列,按照先进先出原则,就会先执行 s1 事件
* 输出 s1
* (4)然后从上到下执行,遇到了微任务 p2 事件和 p3 事件,放到微任务列表,然后清空 s1 事件
* 每执行一个宏任务之后就会立刻检查微任务对列
* 输出 p2 p3, 微任务列表会被清空
* (5)切换到宏任务列表,发现有 s2 和 s3,按照对列顺序清空
* 输出 s2 s3
* 最后输出结果: p1 s1 p2 p3 s2 s3
*/20、Nodejs 下的事件环
(1)Nodejs 事件循环机制

队列说明:
- timers:执行 setTimeout 与 setInterval 回调
- pengding callbacks:执行系统操作的回调,例如top udp
- idle,prepare:只在系统内部进行使用
- poll:执行与 I/O 相关的回调
- check:执行 setImmediate 中的回调
- close callbacks:执行 close 事件的回调
(2)Nodejs 完整事件环
- 执行同步代码,将不同的任务添加至相应的队列
- 所有同步代码执行后回去执行满足条件微任务
- timer 中的所有宏任务执行完成后就会依次切换队列
注意:在完成队列切换之前会先情况微任务代码
内容见下一篇博客:Node.js高级编程【二】