2.O(NlogN)的排序算法
认识O(NlogN)的排序算法
1.剖析递归行为及其时间复杂度的估算
递归过程:递归过程是一个多叉树,计算所有树的结点的过程就是利用栈进行后序遍历,每个结点通过自己的所有子结点给自己汇总信息之后才能继续向上返回,栈空间就是整个树的高度。
例题①用递归方法找一个数组中的最大值。
int process(vector<int> &nums, int L, int R) {
if (L == R) {
return nums[L];
}
//>>操作是位运算,向右整体移一位,相当于除2,速度比出发运算要快。
int mid = L + ((R - L) >> 1);
int leftMax = process(nums, L, mid);
int rightMax = process(nums, mid + 1, R);
return max(leftMax, rightMax);
}
int main() {
vector<int> nums{3, 2, 5, 6, 7, 4};
int max = process(nums, 0, nums.size() - 1);
cout << max;
}
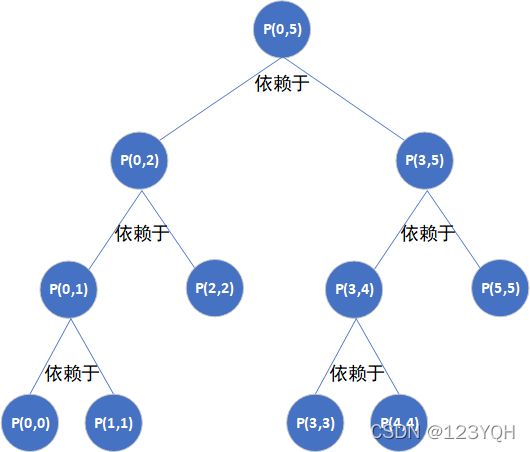
对数组[3, 2, 5, 6, 7, 4]调用process(nums, 0, 5)的递归逻辑图如下图,其中p(a,b)表示process(nums, a, b)
Master公式:
T ( N ) = a × T ( N / b ) + O ( N d ) T(N)= a×T(N/b)+O(N^d) T(N)=a×T(N/b)+O(Nd)
T(N)表示目问题的数据规模是N级别的;T(N/b)表示递归子过程的数据规模是N/b的规模; a表示子过程被调用次数;O(N^d)表示剩下的过程时间复杂度。
满足master公式的递归可以用以下公式求解时间复杂度:
- log(b, a) > d -> 复杂度为O(N^log(b, a)})
- log(b, a) = d -> 复杂度为O(N^d * logN)
- log(b,a) < d -> 复杂度为O(N^d)
满足这样过程的递归可以用master公式求解时间复杂度。
如例题①可以用master公式表示为:T(N) = 2 * T(N/2) + O(1)
2.归并排序
归并排序:
- 整体就是一个简单的递归,左边排好序、右边排好序、让其整体有序
- 让其整体有序的过程中用了外排序方法(即merge函数的过程)
- 利用master公式来求解时间复杂度
void merge(vector<int>& nums, int L, int M, int R) {
vector<int> help(R - L + 1, 0);
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = nums[p1] <= nums[p2] ? nums[p1++] : nums[p2++];
}
while (p1 <= M) {
help[i++] = nums[p1++];
}
while (p2 <= R) {
help[i++] = nums[p2++];
}
for (i = 0; i < help.size(); ++i) {
nums[L + i] = help[i];
}
}
void process(vector<int>& nums, int L, int R) {
if (L == R) {
return;
}
int mid = L + ((R - L) >> 1);
process(nums, L, mid);
process(nums, mid + 1, R);
merge(nums, L, mid, R);
}
int main() {
vector<int> nums{ 3, 2, 5, 6, 7, 4 };
process(nums, 0, 5);
for (int i : nums) {
cout << i << " ";
}
}
//输出结果为: 2 3 4 5 6 7
归并排序的master公式可以表示为:T(N) = 2T(N / 2) + O(N)。
a = 2, b = 2, d = 1.因此,归并排序的时间复杂度为O(NlogN),空间复杂度为O(N)。
例题②:小和问题,在一个数组中,每一个数左边比当当前数小的数累加起来,叫做这个数组的小和,求一个数组的小和。
例:数组[1, 3, 4, 2, 5]。1左边没有比1小的数;3左边比3小的数位1;4左边比4小的数1、3;2左边比2小的数1;5左边比5小的数为1、3、4;所以小和为1+1+3+1+1+3+4+2=16
//可以用归并求小和
//可以反过来想,1右边有3,4,2,5比1大,产生4个1的小和4;3右边有4、5比3大,产生2个3的小和6;4右边有5比4大,产生一个4的小和4;2的右边有一个5比2大产生一个2的小和。
//归并的过程1和右边4个数都比较过一次,只要左边比右边大就产生一个左边小的数的小和
int merge(vector<int>& nums, int L, int M, int R) {
vector<int> help(R - L + 1, 0);
int i = 0;
int p1 = L;
int p2 = M + 1;
int res = 0;
while (p1 <= M && p2 <= R) {
if (nums[p1] <= nums[p2]) {
help[i++] = nums[p1];
res += nums[p1] * (R - p2 + 1);
++p1;
} else {
help[i++] = nums[p2++];
}
}
while (p1 <= M) {
help[i++] = nums[p1++];
}
while (p2 <= R) {
help[i++] = nums[p2++];
}
for (i = 0; i < help.size(); ++i) {
nums[L + i] = help[i];
}
return res;
}
int process(vector<int>& nums, int L, int R) {
if (L == R) {
return 0;
}
int mid = L + ((R - L) >> 1);
return process(nums, L, mid) + process(nums, mid + 1, R) + merge(nums, L, mid, R);
}
3.快速排序
随即快速排序(改进的快速排序)
- 在数组范围中,等概率随机选一个数作为划分值,然后把数组通过荷兰国旗问题分成三个部分:左侧<划分值、 中间==划分值 、 右侧>划分值
- 对左侧范围和右侧范围,递归进行
- 时间复杂度为O(NlogN),空间复杂度为O(logN)。
//荷兰国旗问题,将一个数组以一个数为边界划分三个区域
//处理nums[L,...R]的函数
//默认以num[R]做划分
//返回区域(左边界,有边界)。
vector<int> partition(vector<int> &nums, int L, int R) {
int less = L - 1; //<区右边界
int more = R; //>区左边界
while (L < more) { //L表示当签数的位置 nums[R]->划分值
if (nums[L] < nums[R]) {
swap(nums[++less], nums[L++]);
} else if (nums[L] > nums[R]) {
swap(nums[--more], nums[L]);
} else {
++L;
}
}
swap(nums[more], nums[R]);
return vector<int>{less + 1, more};
}
void quickSort(vector<int> &nums, int L, int R) {
if (L < R) {
int random = rand() % (R - L + 1) + L;
swap(nums[random], nums[R]);
vector<int> p = partition(nums, L, R);
quickSort(nums, L, p[0] - 1); //<区
quickSort(nums, p[1] + 1, R); //>区
}
}
int main() {
vector<int> nums{ 3, 2, 5, 6, 7, 4 };
quickSort(nums, 0, nums.size() - 1);
for (int i : nums) {
cout << i << " ";
}
}
//输出结果为: 2 3 4 5 6 7
4.堆排序
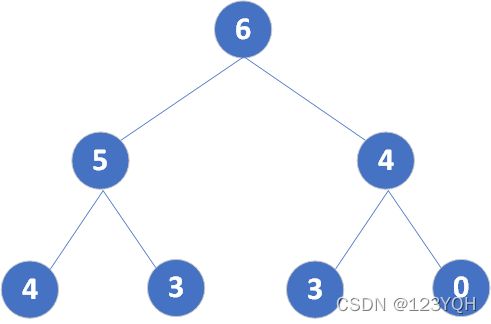
4.1大顶堆和小顶堆
堆是具有下列性质的完全二叉树:
- 每个结点的值都大于等于其左右孩子结点的值,称为大顶堆
- 每个结点的值都小于等于其左右孩子的值,称为小顶堆。
- 完全二叉树可以用数组来存储。
如下图的大顶堆
完全二叉树可以用数组来存储,因此完全二叉树的编号就对应数组的下标,二叉树的编号结点具有如下性质,对于任意编号索引大于0的结点,有:
- 父结点的编号索引为:(k - 1) / 2。
- 左孩子的编号索引为:2 × k + 1。
- 右孩子的编号索引为:2 × k + 2。
堆的定义用上面的性质来描述的话,则有:
- 大根堆:arr[k] > arr[2 × k + 1] && arr[k] > arr[2 × k + 2]
- 小根堆:arr[k] < arr[2 × k + 1] && arr[2 × k + 1] < arr[2 × k + 2]
4.2heapInsert操作和heapfity操作
①如何把边插入一个数保持变成一个堆?(heapInsert过程)
用户每给一个数,不停向上跟父结点比,如果比父结点大则交换,这样可以保证在插入新的数之后保持形成大根堆。这个过程叫做heapInsert过程。
例:将用户输入给数组的数变成一个大根堆。
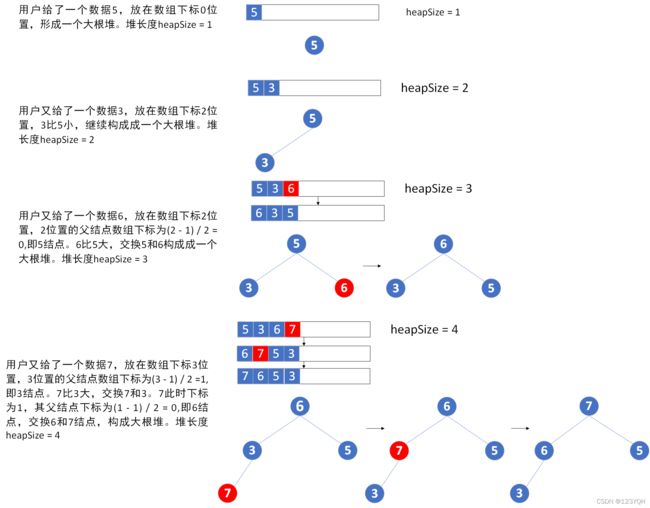
//heapInsert过程
//某个数现在处于index位置,继续向上移动
void heapInsert(vector<int>& nums, int index) {
while (nums[index] > nums[(index - 1) / 2]) {
swap(nums[index], nums[(index - 1) / 2]);
index = (index - 1) / 2;
}
}
②如何知道堆中最大值并把它从堆中去掉?
先用一个临时量记录堆第一个元素,就是堆的最大值。将堆最后一个元素放到第一个元素位置,并减少堆长度即heapSize – 1(把堆最后一个元素放到堆第一个元素位置),此时整体可能不是堆,此时需要调整(进行heapify操作)。从头节点(cur)开始,在它的左孩子和右孩子中选择一个最大值,和头节点比较,如果孩子最大值的值比头节点大则交换两者,直到cur结点没有左孩子和右孩子。
如:弹出堆数组[6 3 5 2 3 4]的最大两个值。
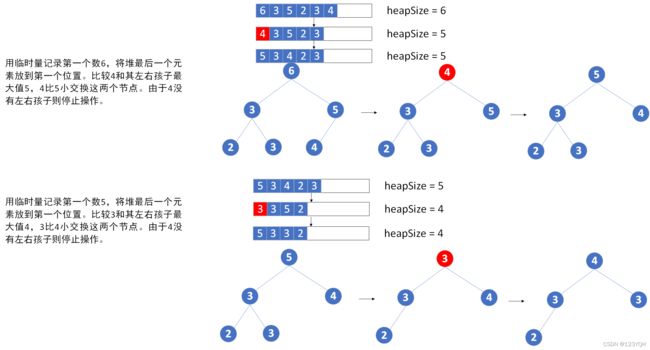
//某个数在index位置,能否往下移动
void heapify(vector<int>& nums, int index, int heapSize) {
int left = index * 2 + 1; //左孩子下标
while (left < heapSize) { //下方还有孩子的时候
//两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && nums[left + 1] > nums[left] ? left + 1 : left;
//父和较大的孩子之间,谁的值大,把下标给largest
largest = nums[largest] > nums[index] ? largest : index;
if (largest == index) {
break;
}
swap(nums[largest], nums[index]);
index = largest;
left = index * 2 + 1;
}
}
③如何将一个已有的数组变成一个大根堆?
heapify解决的是:如果一个二叉树根节点的左右子树都是一个堆,但是加上根节点就可能不是一个堆,用heapify可以将这种二叉树调整成一个堆。
那么对于一个已有数组,我们只要从后往前进行heapify操作即可将这棵树变成大根堆,即将已有数组变成一个大根堆。
for (int i = nums.size() - 1; i >= 0; --i) {
heapify(nums, i, nums.size());
}
6.3堆排序
堆排序就是利用堆进行排序的方法,升序排序用大顶堆,降序排序用小顶堆(优先级队列其实就是堆结构,默认是小顶堆)。 以升序排序为例,它的基本思想是:
- 将待排序的序列构造成一个大顶堆,此时整个序列的最大值就是堆顶的根结点。
- 将它与堆数组的末尾元素进行交换,此时末尾元素就是最大值。
- 将除了末尾元素的剩余的n - 1个序列重新构造成一个大顶堆,重复上述步骤,便能得到一个有序序列了。
//某个数现在处于index位置,继续向上移动
void heapInsert(vector<int>& nums, int index) {
while (nums[index] > nums[(index - 1) / 2]) {
swap(nums[index], nums[(index - 1) / 2]);
index = (index - 1) / 2;
}
}
//某个数在index位置,能否往下移动
void heapify(vector<int>& nums, int index, int heapSize) {
int left = index * 2 + 1; //左孩子下标
while (left < heapSize) { //下方还有孩子的时候
//两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && nums[left + 1] > nums[left] ? left + 1 : left;
//父和较大的孩子之间,谁的值大,把下标给largest
largest = nums[largest] > nums[index] ? largest : index;
if (largest == index) {
break;
}
swap(nums[largest], nums[index]);
index = largest;
left = index * 2 + 1;
}
}
void heapSort(vector<int>& nums) {
if (nums.size() < 2) {
return;
}
//相当于把数组变成大根堆
for (int i = 0; i < nums.size(); ++i) { //O(N)
heapInsert(nums, i); //O(logN)
}
int heapSize = nums.size();
swap(nums[0], nums[--heapSize]);
while (heapSize > 0) { //O(N)
heapify(nums, 0, heapSize); //O(logN)
swap(nums[0], nums[--heapSize]); //O(1)
}
}
int main() {
vector<int> nums{ 3, 2, 5, 6, 7, 4 };
heapSort(nums, 0, nums.size() - 1);
for (int i : nums) {
cout << i << " ";
}
}
//输出结果为: 2 3 4 5 6 7