Java文件上传大杀器-绕waf(针对commons-fileupload组件)
Java文件上传大杀器-绕waf(针对commons-fileupload组件)
来个中二的标题,哈哈哈,灵感来源于昨晚赛博群有个师傅@我是killer发了篇新文章,在那篇文章当中提到了在filename="1.jsp"的filename字符左右可以加上一些空白字符%20 %09 %0a %0b %0c %0d %1c %1d %1e %1f,比如%20filename%0a="1.jsp"(直接用url编码为了区别)这样导致waf匹配不到我们上传⽂件 名,⽽我们上传依然可以解析,我对次进行了更深入的研究,也是对师傅文章对一次补充,下面为了衔接还是先梳理一遍,看过赛博群的师傅可以先跳过前面的部分,直接看最后一部分(毕竟我想发个博客)
上传代码
针对使⽤commons-fileupload处理⽂件上传
public class TestServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response) throws IOException {
String path = "/Users/y4tacker/Desktop/JavaStudy/testtest";
try {
ServletFileUpload servletFileUpload = new ServletFileUpload(new DiskFileItemFactory());
servletFileUpload.setHeaderEncoding("UTF-8");
List<FileItem> fileItems = servletFileUpload.parseRequest(request);
for (FileItem fileItem : fileItems) {
response.getWriter().write(fileItem.getName());
fileItem.write(new File(path+"/"+fileItem.getName()));
}
}catch (Exception e){
}
}
}
前置分析
将断点打在servletFileUpload.parseRequest(request),跟入getItemIterator
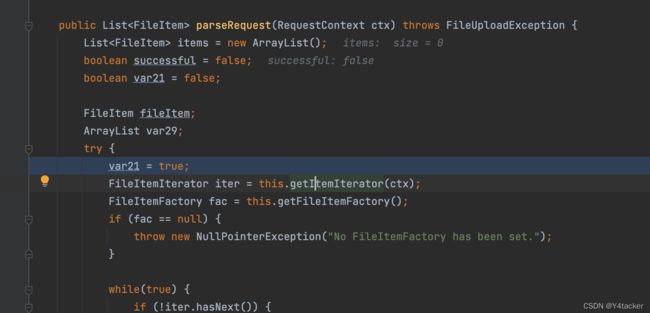
一直往下到org.apache.commons.fileupload.FileUploadBase.FileItemIteratorImpl#FileItemIteratorImpl
Content-Type 要开头为 multipart/
接下来对流的处理部分忽略,到下面有个this.boundary = FileUploadBase.this.getBoundary(contentType);,因为文件上传的格式就是,可以猜出这里就是解析这一部分
------WebKitFormBoundaryTyBDoKvamN58lcEw
Content-Disposition: form-data; name="filename"; filename="1.jsp"
233
------WebKitFormBoundaryTyBDoKvamN58lcEw--
当时师傅跳过中间一些部分到了org.apache.commons.fileupload.FileUploadBase#getFileName(java.lang.String)

在parser.parse(pContentDisposition, ';');,简单说下作用是先⽤分号将 form-data; name="file"; filename="1.jsp" 分割然后获取 等于号前⾯的值,这里我们看看到getToken当中的栈(方便大家调试)
getToken:99, ParameterParser (org.apache.commons.fileupload)
parseToken:162, ParameterParser (org.apache.commons.fileupload)
parse:311, ParameterParser (org.apache.commons.fileupload)
parse:279, ParameterParser (org.apache.commons.fileupload)
parse:262, ParameterParser (org.apache.commons.fileupload)
parse:246, ParameterParser (org.apache.commons.fileupload)
getBoundary:423, FileUploadBase (org.apache.commons.fileupload)
:988, FileUploadBase$FileItemIteratorImpl
这里有个到 Character.isWhitespace,也就是@我是killer师傅提到的点,也是我们开篇前言中说到的利用方式,就不多提了
正文开启
看看getFileName调用前,其实传入了一个headers,这个headers来源于上面的this.multi
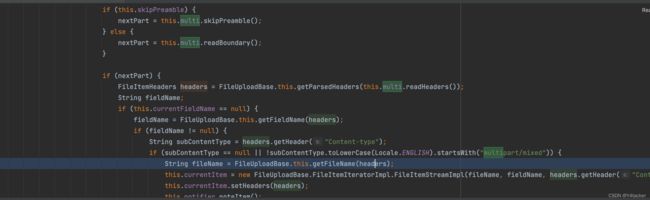
而这个multi来源,还与我们上面的bundary有关
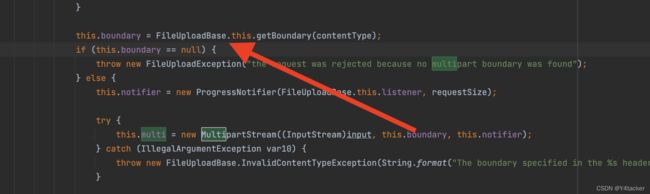
继续回到上面的getFileName之前this.boundary = FileUploadBase.this.getBoundary(contentType);
失败的绕waf点
从这里可以看到和上面getFileName的分隔符不一样,这里用了两个分隔符,那么这里我就在想如果getFileName那里如果和这个逻辑不相关岂不是可以拿下
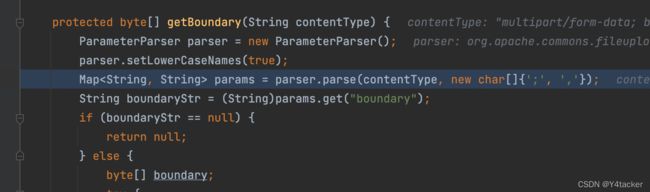
我们知道上面getFileName的参数来源于org.apache.commons.fileupload.MultipartStream#readHeaders,可以看到这里是通过for循环遍历并调用getBytes获取
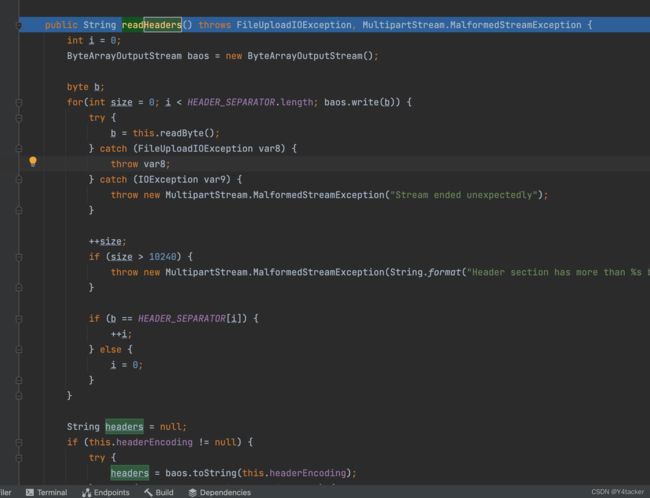
而这个input来源就是我们之前传入的输入流
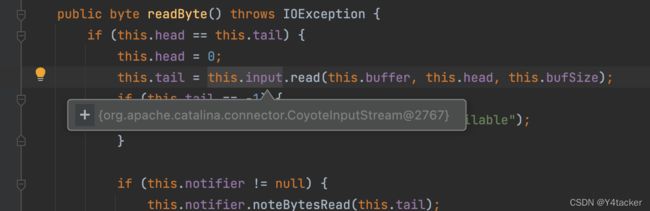
因此这里的绕过思路便是无法奏效,主要原因是,看getFilename这里,分割符只有;,我也是麻了
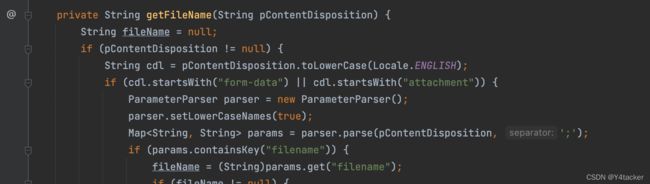
成功的绕waf点
在org.apache.commons.fileupload.ParameterParser#parse(char[], int, int, char),
wow!!,这里对value进行了MimeUtility.decodeText操作
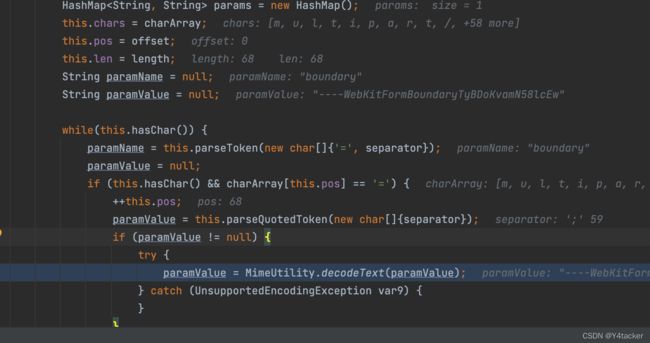
我们知道对MIME的编码出现在邮件中,因为 SMTP 协议一开始只支持纯 ASCII 文本的传输,这种情况下,二进制数据要通过 MIME 编码才能发送
那我们来看看这个decode里面干了啥,我直接看了下面如果=?开头则会调用decode方法
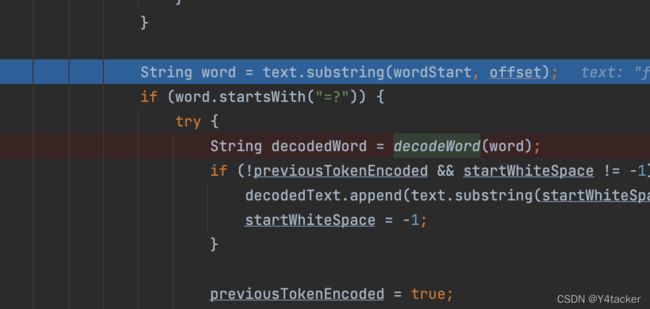
我来对这串又臭又长的代码进行解读,主要是为了符合RFC 2047规范
- 要求以
=?开头 - 之后要求还要有一个
?,中间的内容为编码,也就是=?charset? - 获取下一个
?间的内容,这里与下面的编解码有关 - 之后定位到最后一个
?=间内容执行解码
这里我们来一个实例方便理解上面步骤=?gbk?Q?=31=2e=6a=73=70?=
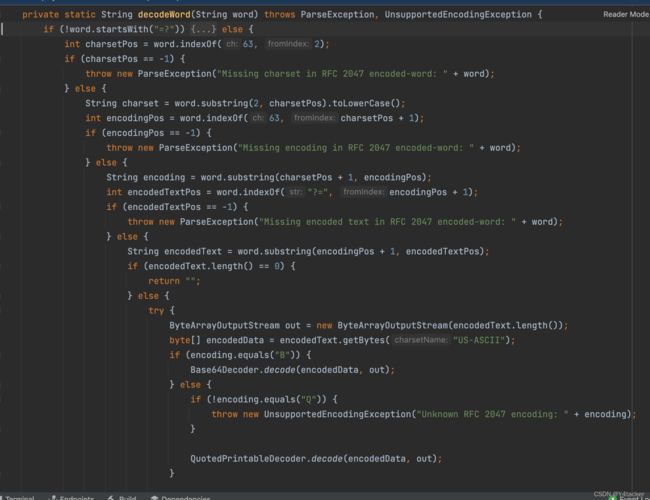
从上面的步骤可以看到对指支持两种解码一种是B一种Q,分别对应Base64以及Quoted-printable编码,对于前者大家都很熟悉,对于后者我们这里只说如何编码
Quoted-printable将任何8-bit字节值可编码为3个字符:一个等号"=“后跟随两个十六进制数字(0–9或A–F)表示该字节的数值。例如,ASCII码换页符(十进制值为12)可以表示为”=0C", 等号"="(十进制值为61)必须表示为"=3D",gb2312下“中”表示为=D6=D0
因此我们就可以对这个value进行一些编码的骚操作,下面我们来梳理下可利用的点
-
一个是控制字符串的编码,这里支持编码很多因为是调用
new String(decodedData, javaCharset(charset)),这个javaCharset函数预制了一些,可以看到如果不是这里面的就直接返回那个指,而new String函数里面会调用所有java支持的编码格式去解析,也就是charsets.jar里面的内容private static String javaCharset(String charset) { if (charset == null) { return null; } else { String mappedCharset = (String)MIME2JAVA.get(charset.toLowerCase(Locale.ENGLISH)); return mappedCharset == null ? charset : mappedCharset; } } static { MIME2JAVA.put("iso-2022-cn", "ISO2022CN"); MIME2JAVA.put("iso-2022-kr", "ISO2022KR"); MIME2JAVA.put("utf-8", "UTF8"); MIME2JAVA.put("utf8", "UTF8"); MIME2JAVA.put("ja_jp.iso2022-7", "ISO2022JP"); MIME2JAVA.put("ja_jp.eucjp", "EUCJIS"); MIME2JAVA.put("euc-kr", "KSC5601"); MIME2JAVA.put("euckr", "KSC5601"); MIME2JAVA.put("us-ascii", "ISO-8859-1"); MIME2JAVA.put("x-us-ascii", "ISO-8859-1"); } -
控制
Base64以及Quoted-printable去解码
这里来测试一下,对能编码的都编码一遍
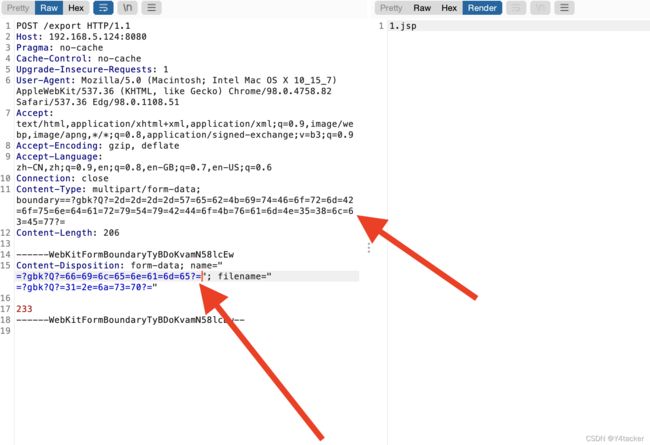
成功上传怎么说
继续增强混淆
还记得吗,当时说的只会提取=??=之间的内容,那我们在后面加点其他东西也可以,当然boundary==?gbk?Q?=2d=2d=2d=2d=57=65=62=4b=69=74=46=6f=72=6d=42=6f=75=6e=64=61=72=79=54=79=42=44=6f=4b=76=61=6d=4e=35=38=6c=63=45=77?=这个不能加,因为他在header头,会造成解析出问题
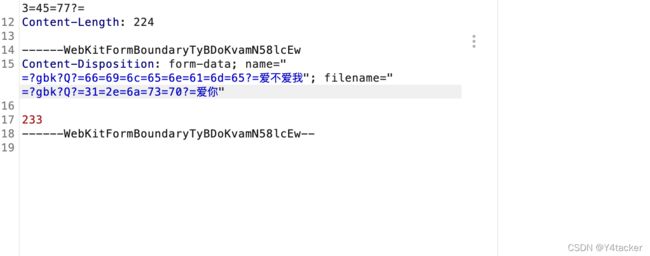
你以为就这就完了?
再回到org.apache.commons.fileupload.util.mime.MimeUtility#decodeText,这里还有判断\t\r\n
直接解释代码有点累了,看图啥都懂了
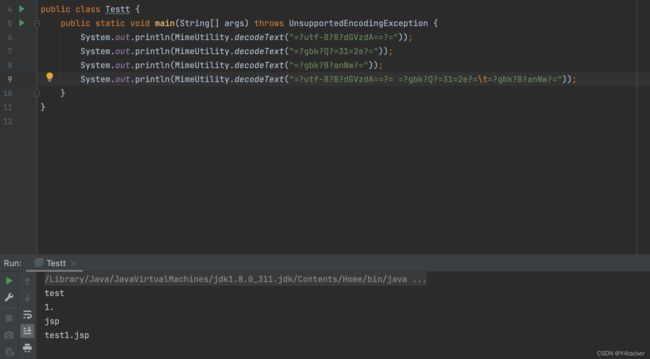
测试相关代码
整合在一起了,最后再次感谢@我是killer师傅的文章带给我的思路
import base64
name = "test"
encode = name.encode("utf-8")
b = base64.b64encode(encode)
print("=?utf-8?B?"+b.decode()+"?=")
res = ""
for i in encode.decode("gbk"):
tmp = hex(ord(i)).split("0x")[1]
res += f"={tmp}"
print("=?gbk?Q?"+res+"?=")