nutch工程源码导入Eclipse过程
测试环境
-
Nutch release 0.9
-
Eclipse 3.3 - aka Europa
-
Java 1.6
开始之前
Setting up Nutch to run into Eclipse can be tricky, and most of the time you are much faster if you edit Nutch in Eclipse but run the scripts from the command line (my 2 cents). However, it's very useful to be able to debug Nutch in Eclipse. But again you might be quicker by looking at the logs (logs/hadoop.log)...
配置步骤
安装Nutch
-
Grab a fresh release of Nutch 0.9 http://lucene.apache.org/nutch/version_control.html
-
Do not build Nutch now. Make sure you have no .project and .classpath files in the Nutch directory
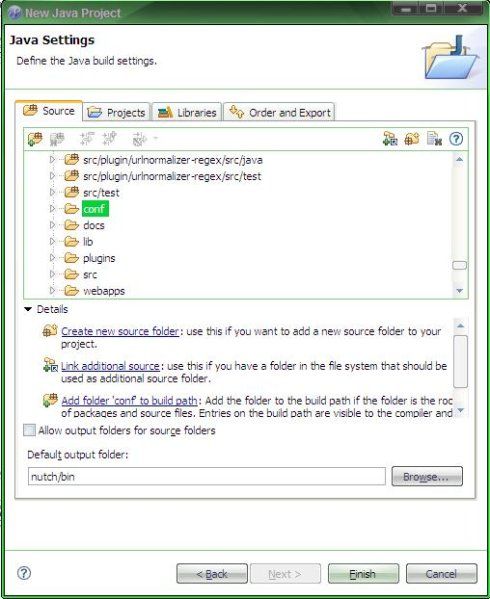
在Eclipse中创建一个新的java工程,名字为nutch
-
File > New > Project > Java project > click Next
-
Name the project (nutch)
-
Select "Create project from existing source" and use the location where you downloaded Nutch
-
Click on Next, and wait while Eclipse is scanning the folders
-
Eclipse should have guessed all the java files that must be added on your classpath. If it's not the case, add "src/java", "src/test" and all plugin "src/java" and "src/test" folders to your source folders. Also add all jars in "lib" and in the plugin lib folders to your libraries
-
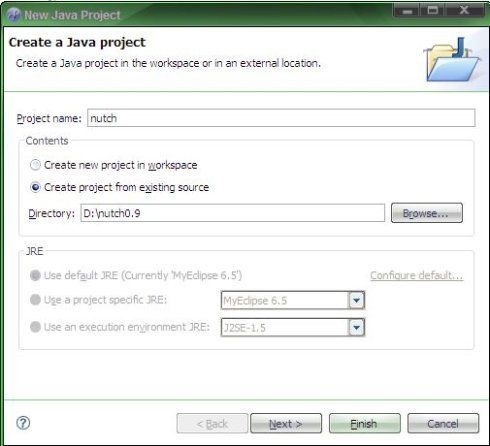
把nutch-0.9的conf添加到工程目录下,里面都是配置文件.单击conf文件夹,选择第三项,and folder conf to
build path,并且Default output folder 选择/nutch/conf。
-
配置nutch
-
为处理方便,直接在nutch工程下创建一个名为url.txt文件,然后在文件里添加要搜索的网址,例如:http://www.sina.com.cn/,注意网址最后的"/"一定要有。前面的"http://"也是必不可少的。
2.配置crawl-urlfilter.txt打开工程conf/crawl-urlfilter.txt文件,找到这两行
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
红色部分是一个正则,改写为如下形式
+^http://([a-z0-9]*\.)*com.cn/
+^http://([a-z0-9]*\.)*cn/
+^http://([a-z0-9]*\.)*com/ -
注意:“+”号前面不要有空格。
-
3.修改conf\nutch-site.xml为如下内容,否则不会抓取。
<configuration>
<property>
<name>http.agent.name</name> <value>*</value> </property>
</configuration>
-
在conf/nutch-defaul.xml下,将属性"plugin.folders"的值由“plugins”更改为 "./src/plugin"
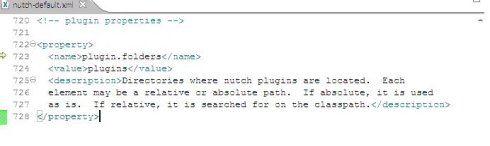
缺少
You will encounter problems with some imports in parse-mp3 and parse-rtf plugins (30 errors in my case). Because of incompatibility with Apache license they were left from sources. You can download them here:
![]() http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-mp3/lib/
http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-mp3/lib/
![]() http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-rtf/lib/
http://nutch.cvs.sourceforge.net/nutch/nutch/src/plugin/parse-rtf/lib/
Copy the jar files into src/plugin/parse-mp3/lib and src/plugin/parse-rtf/lib/ respectively. Then add them to the libraries to the build path (First refresh the workspace. Then Right click on the source folder => Java Build Path => Libraries => Add Jars).
配置Crawl.java运行环境
-
Menu Run > "Run..."
-
create "New" for "Java Application"
-
set in Main class
org.apache.nutch.crawl.Crawl
-
on tab Arguments, Program Arguments
urls -dir crawl -depth 3 -topN 50
( urls是存放入口地址的文件夹(在工程的根目录建新建一个urls的目录,
里面新建一个文本文件,也可以没有后缀名,在里面填写url 比如: http://www.163.com/),
-dir创建一个名为 crawl 的文件夹,里面就是我们抓取回来的数据存放地方
-depth 3 采集深度 3层 topN 最大页数
)
-
in VM arguments
-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log
-
click on "Run"
-
if all works, you should see Nutch getting busy at crawling