(系列更新完毕)深度学习零基础使用 PyTorch 框架跑 MNIST 数据集的第二天:加载 MNIST 数据集
1. Introduction
今天是尝试用 PyTorch 框架来跑 MNIST 手写数字数据集的第二天,主要学习加载 MNIST 数据集。本 blog 主要记录一个学习的路径以及学习资料的汇总。
注意:这是用 Python 2.7 版本写的代码
第一天(LeNet 网络的搭建):https://blog.csdn.net/qq_36627158/article/details/108098147
第二天(加载 MNIST 数据集):https://blog.csdn.net/qq_36627158/article/details/108119048
第三天(训练模型):https://blog.csdn.net/qq_36627158/article/details/108163693
第四天(单例测试):https://blog.csdn.net/qq_36627158/article/details/108183655
2. Code(lenet.py)
感谢 凯神 提供的代码与耐心指导!
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import glob
import os.path as osp
from PIL import Image
import matplotlib.pyplot as plt
TRAIN_BATCH_SIZE = 128
TEST_BATCH_SIZE = 1000
class MNIST(Dataset): # define a class named MNIST
# read all pictures' filename
def __init__(self, root, transform=None):
self.filenames = []
self.transform = transform
# read filenames
for i in range(10):
# 'root/0/all_png'
filenames = glob.glob(osp.join(root, str(i), '*.png'))
for fn in filenames:
# (filename, label)
self.filenames.append((fn, i))
self.len = len(self.filenames)
# Get a sample from the dataset
# Return an image and it's label
def __getitem__(self, index):
# open the image
image_fn, label = self.filenames[index]
image = Image.open(image_fn)
# May use transform function to transform samples
if self.transform is not None:
image = self.transform(image)
return image, label
# get the length of dataset
def __len__(self):
return self.len
# define the transformation
# PIL images -> torch tensors [0, 1]
transform = transforms.Compose([
transforms.ToTensor()
])
# 2. load the MNIST training dataset
trainset = MNIST(
root='/home/ubuntu/Downloads/C6/mnist_png/training',
transform=transform
)
# divide the dataset into batches
trainset_loader = DataLoader(
trainset,
batch_size=TRAIN_BATCH_SIZE,
shuffle=True,
num_workers=0
)
# 3. load the MNIST testing dataset
testset = MNIST(
root='/home/ubuntu/Downloads/C6/mnist_png/testing',
transform=transform
)
# divide the dataset into batches
testset_loader = DataLoader(
testset,
batch_size=TEST_BATCH_SIZE,
shuffle=False,
num_workers=0
)
3. Materials
1、Dataset 的抽象类官方文档:
https://pytorch-cn.readthedocs.io/zh/latest/package_references/data/
2、DataLoader 类的官方文档:
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
4、Code Details
1、__init__() 函数
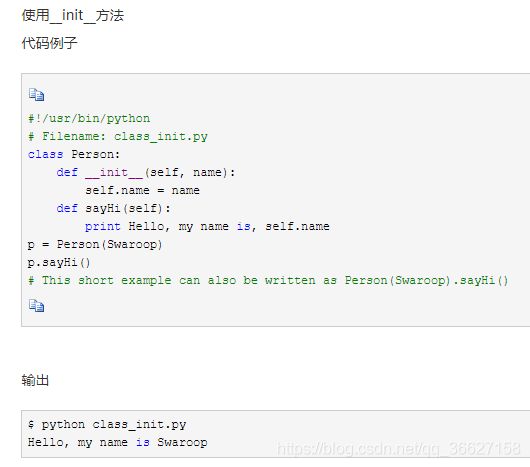
注意:__init__并不相当于C#中的构造函数,执行它的时候,实例已构造出来了。__init__作用是初始化已实例化后的对象。
图文均来自链接:https://www.cnblogs.com/insane-Mr-Li/p/9758776.html
2、Dataset 的子类都应该要重写 __len__() 和 __getitem__() 函数。前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)。
之前看代码,一直没有看到具体体现 __getitem__() 函数的使用地方。
后面查到了:只要继承了 Dataset 这个类后,就可以通过类的实例化对象的索引来调用到 _getitem_() 了。如: data[0]
https://www.zhihu.com/question/383099903
(图也是链接里的)
3、enumerate() 函数
将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print i, element
# 0 one
# 1 two
# 2 threehttps://www.runoob.com/python/python-func-enumerate.html
4、Batch Size
Batch Size的理解:https://blog.csdn.net/qq_34886403/article/details/82558399
batch size 设置技巧:https://blog.csdn.net/kl1411/article/details/82983971
顺便找到了一个小白科普贴:深度学习中GPU和显存分析
5、Dataloader 中的 num_worker
https://www.cnblogs.com/hesse-summer/p/11343870.html
https://blog.csdn.net/breeze210/article/details/99679048
6、迭代器(iterator)
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
https://www.runoob.com/python3/python3-iterator-generator.html
7、DataLoader, DataSet, Sampler之间的关系
https://zhuanlan.zhihu.com/p/76893455
8、DataLoader 的索引
- dataloader本质是一个可迭代对象,使用 iter() 访问,不能使用 next() 访问
- 使用 iter(dataloader) 返回的是一个迭代器,然后可以使用next访问
- 也可以使用 for inputs, labels in dataloaders 进行可迭代对象的访问
- 一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据
https://www.cnblogs.com/ranjiewen/p/10128046.html
9、Python glob.glob使用
https://www.cnblogs.com/luminousjj/p/9359543.html
https://www.cnblogs.com/luminousjj/p/9359543.html