爬虫goodreads数据

什么 (What)
This is a data set of the first 50,000 book ids pulled from Goodreads’ API on July 30th, 2020. A few thousand ids did not make it through because the book id was changed, the URL or API broke, or the information was stored in an atypical format.
这是2020年7月30日从Goodreads的API中提取的前50,000个图书ID的数据集。由于图书ID发生更改,URL或API中断或信息存储在其中,数千个ID没有通过非典型格式。
为什么 (Why)
From the reader’s perspective, books are a multi-hour commitment of learning and leisure (they don’t call it Goodreads for nothing). From the author’s and publisher’s perspectives, books are a way of living (with some learning and leisure too). In both cases, knowing which factors explain and predict great books will save you time and money. Because while different people have different tastes and values, knowing how a book is rated in general is a sensible starting point. You can always update it later.
从读者的角度来看,书籍是学习和休闲的一个多小时的承诺(他们不称其为“ 好读书无所作为”)。 从作者和出版者的角度来看,书籍是一种生活方式(也有一些学习和休闲的机会)。 在这两种情况下,了解哪些因素可以解释和预测优秀的书将为您节省时间和金钱。 因为尽管不同的人有不同的品味和价值观,但了解一本书的总体评级是明智的起点。 您以后可以随时对其进行更新。
环境 (Environment)
It’s good practice to work in a virtual environment, a sandbox with its own libraries and versions, so we’ll make one for this project. There are several ways to do this, but we’ll use Anaconda. To create and activate an Anaconda virtual environment called ‘gr’ (for Goodreads) using Python 3.7, run the following commands in your terminal or command line:
在虚拟环境中工作是一个好习惯,这是一个具有自己的库和版本的沙箱,因此我们将为该项目创建一个。 有几种方法可以做到这一点,但是我们将使用Anaconda 。 要使用Python 3.7创建并激活名为'gr'(用于Goodreads)的Anaconda虚拟环境,请在终端或命令行中运行以下命令:
装置 (Installations)
You should see ‘gr’ or whatever you named your environment at the left of your prompt. If so, run these commands. Anaconda will automatically install any dependencies of these packages, including matplotlib, numpy, pandas, and scikit-learn.
您应该在提示符左侧看到“ gr”或您所命名的环境。 如果是这样,请运行这些命令。 Anaconda将自动安装这些软件包的所有依赖项,包括matplotlib,numpy,pandas和scikit-learn。
进口货 (Imports)
数据采集 (Data Collection)
We pull the first 50,000 book ids and their associated information using a lightweight wrapper around the Goodreads API made by Michelle D. Zhang (code and documentation here), then write each as a dictionary to a JSON file called book_data.
我们使用轻量级包装器(由Michelle D. Zhang制作, 此处是代码和文档)使用轻量级包装提取前50,000个书籍ID及其相关信息,然后将每个书籍ID作为字典写到名为book_data的JSON文件中。
数据清理 (Data Cleaning)
We’ll define and describe some key functions below, but we’ll run them in one big wrangle function later.
我们将在下面定义和描述一些关键功能,但是稍后将在一个大的争用函数中运行它们。
威尔逊下界 (Wilson Lower Bound)
A rating of 4 stars based on 20 reviews and a rating of 4 stars based on 20,000 reviews are not equal. The rating based on more reviews has less uncertainty about it and is therefore a more reliable estimate of the “true” rating. In order to properly define and predict great books, we must transform average_rating by putting a penalty on uncertainty.
基于20条评论的4星评级和基于20,000条评论的4星评级不相等。 基于更多评论的评级具有较少的不确定性,因此是对“真实”评级的更可靠的估计。 为了正确定义和预测好书,我们必须通过对不确定性进行惩罚来转变average_rating 。
We’ll do this by calculating a Wilson Lower Bound, where we estimate the confidence interval of a particular rating and take its lower bound as the new rating. Ratings based on tens of thousands of reviews will barely be affected because their confidence intervals are narrow. Ratings based on fewer reviews, however, have wider confidence intervals and will be scaled down more.
我们将通过计算威尔逊下界(Wilson Lower Bound)来做到这一点,在此我们估计特定等级的置信区间,并将其下界作为新等级。 基于数万条评论的评分几乎不会受到影响,因为它们的置信区间很窄。 但是,基于较少评论的评分具有较大的置信区间,并且将被缩小。
Note: We modify the formula because our data is calculated from a 5-point system, not a binary system as described by Wilson. Specifically, we decrement average_rating by 1 for a conservative estimate of the true non-inflated rating, and then normalize it. If this penalty is too harsh or too light, more ratings will over time raise or lower the book’s rating, respectively. In other words, with more information, this adjustment is self-correcting.
注意 :我们修改公式是因为我们的数据是根据5点系统而不是Wilson所描述的二进制系统计算的。 具体来说,我们对平均非虚假评级的保守估计值将average_rating递减1,然后对其进行归一化。 如果此惩罚太苛刻或太轻,随着时间的流逝,更多的评级将分别提高或降低该书的评级。 换句话说,有了更多信息,此调整是自校正的。
体裁 (Genres)
Goodreads’ API returns ‘shelves’, which encompass actual genres like “science-fiction” and user-created categories like “to-read”. We extracted only the 5 most popular shelves when pulling the data to limit this kind of clean-up; here, we’ll finish the job.
Goodreads的API返回“货架”,其中包含诸如“科幻小说”之类的实际类型和诸如“待阅读”之类的用户创建类别。 在提取数据时,我们仅提取了5个最受欢迎的书架,以限制此类清理工作。 在这里,我们将完成工作。
After some inspection, we see that these substrings represent the bulk of non-genre shelves. We’ll filter them out using a regular expression. Note: We use two strings in the regex so the line doesn’t get cut off. Adjacent strings inside parantheses are joined at compile time.
经过检查,我们发现这些子字符串代表了大部分非类型的货架。 我们将使用正则表达式过滤掉它们。 注意 :我们在正则表达式中使用了两个字符串,因此该行不会被截断。 括号内的相邻字符串在编译时连接。
多合一清洁 (All-in-one Cleaning)
Now we’ll build and run one function to wrangle the data set. This way, the cleaning is more reproducible and debug-able.
现在,我们将构建并运行一个函数来纠缠数据集。 这样,清洁更可重复且可调试。
比较未调整和调整后的平均评分 (Compare Unadjusted and Adjusted Average Ratings)
Numerically, the central measures of tendency of mean (in blue) and median (in green) slightly decrease, and the variance significantly decreases.
在数值上,均值(蓝色)和中位数(绿色)趋势的中心度量略有降低,并且方差显着降低。
Visually, we can see the rating adjustment in the much smoother and wider distribution (although note that the x-axis is truncated). This is from eliminating outlier books with no or very few ratings, and scaling down ratings with high uncertainty.
在视觉上,我们可以看到等级调整更加平滑和广泛(尽管请注意,x轴被截断了)。 这是因为消除了没有评级或评级很少的离群图书,并降低了不确定性很高的评级。
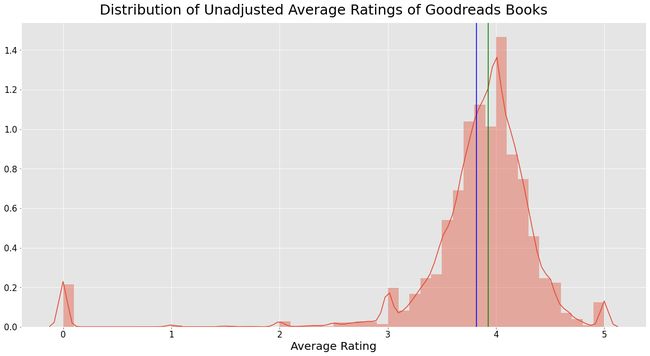
Unadjusted mean: 3.82
Unadjusted median: 3.93
Unadjusted variance: 0.48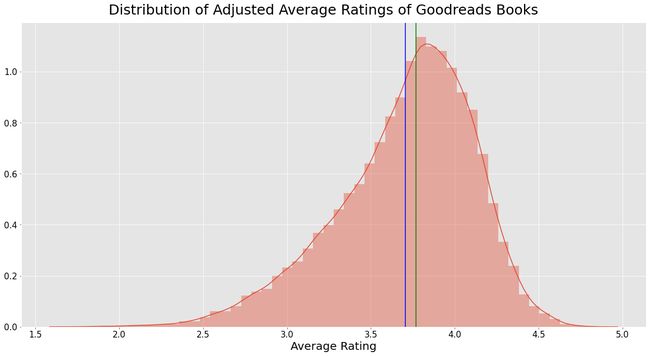
Adjusted mean: 3.71
Adjusted median: 3.77
Adjusted variance: 0.17资料泄漏 (Data Leakage)
Because our target is derived from ratings, training our model using ratings is effectively training with the target. To avoid distorting the model, we must drop these columns.
由于我们的目标是从评级得出的,因此使用评级训练模型可以有效地对目标进行训练。 为了避免扭曲模型,我们必须删除这些列。
It is also possible that review_count is a bit of leakage, but it seems more like a proxy for popularity, not greatness, in the same way that pop(ular) songs are not often considered classics. Of course, we'll reconsider this if its permutation importance is suspiciously high.
review_count也可能有点泄漏,但似乎更像是流行的 review_count ,而不是review_count ,就像流行(ular)歌曲通常不被视为经典之类。 当然,如果其排列重要性很高,我们将重新考虑。
分割资料 (Split Data)
We’ll do an 85/15 train-test split, then re-split our train set to make the validation set about the same size as the test set.
我们将进行85/15火车测试拆分,然后重新拆分火车集,以使验证集的大小与测试集的大小相同。
(20281, 12) (20281,) (4348, 12) (4348,) (4347, 12) (4347,)评估指标 (Evaluation Metrics)
With classes this imbalanced, accuracy (correct predictions / total predictions) can become misleading. There just aren’t enough true positives for this fraction to be the best measure of model performance. So we’ll also use ROC AUC, a Receiver Operator Characteristic Area Under the Curve. Here is a colored drawing of one, courtesy of Martin Thoma.
对于此类不平衡的类,准确性(正确的预测/总的预测)可能会引起误解。 对于这部分,没有足够的真实肯定作为衡量模型性能的最佳方法。 因此,我们还将使用ROC AUC,即曲线下方的接收器操作员特征区域。 这是马丁·托马(Martin Thoma)提供的彩色图画。
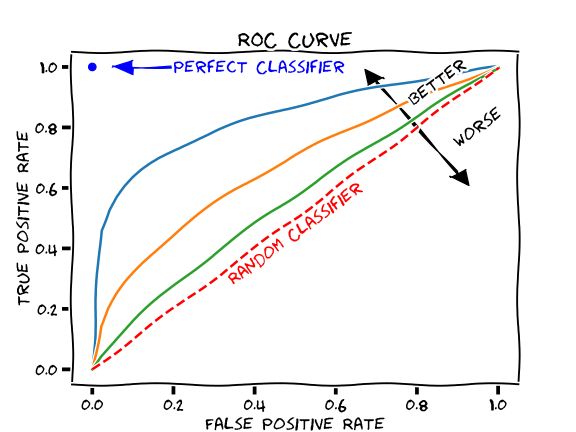
The ROC curve is a plot of a classification model’s true positive rate (TPR) against its false positive rate (FPR). The ROC AUC is the area from [0, 1] under and to the right of this curve. Since optimal model performance maximizes true positives and minimizes false positives, the optimal point in this 1x1 plot is the top left, where the area under the curve (ROC AUC) = 1.
ROC曲线是分类模型的真实阳性率(TPR)相对其假阳性率(FPR)的图。 ROC AUC是此曲线下方和右侧的[0,1]区域。 由于最佳模型性能可最大化真实正值并最小化错误正值,因此此1x1图中的最佳点位于左上方,曲线下面积(ROC AUC)= 1。
For imbalanced classes such as great, ROC AUC outperforms accuracy as a metric because it better reflects the relationship between true positives and false positives. It also depicts the classifier’s performance across all its values, giving us more information about when and where the model improves, plateaus, or suffers.
对于不平衡类(例如great ,ROC AUC优于准确性作为度量标准,因为它可以更好地反映真假阳性之间的关系。 它还描述了分类器在其所有值上的表现,为我们提供了有关模型何时何地改进,平稳或遭受损失的更多信息。
拟合模型 (Fit Models)
Predicting great books is a binary classification problem, so we need a classifier. Below, we’ll encode, impute, and fit to the data a linear model (Logistic Regression) and two tree-based models (Random Forests and XGBoost), then compare them to each other and to the majority baseline. We’ll calculate their accuracy and ROC AUC, and then make a visualization.
预测好书是一个二进制分类问题,因此我们需要一个分类器。 下面,我们将对数据进行编码,估算和拟合,以线性模型(Logistic回归)和两个基于树的模型(Random Forests和XGBoost)进行比较,然后将它们相互比较并与多数基准进行比较。 我们将计算其准确性和ROC AUC,然后进行可视化。
多数阶级基线 (Majority Class Baseline)
First, by construction, great books are the top 20% of books by Wilson-adjusted rating. That means our majority class baseline (no books are great) has an accuracy of 80%.
首先,从结构上看,按威尔逊调整后的评分, great书籍是排名前20%的书籍。 这意味着我们的大多数班级基线( 没有一本好书)的准确性为80%。
Second, this “model” doesn’t improve, plateau, or suffer since it has no discernment to begin with. A randomly chosen positive would be treated no differently than a randomly chosen negative. In other wrods, its ROC AUC = 0.5.
第二,此“模型”没有改善,稳定或遭受损害,因为它一开始没有识别力。 随机选择的阳性与随机选择的阴性没有区别。 在其他情况下,其ROC AUC = 0.5。
Baseline Validation Accuracy: 0.8
Baseline Validation ROC AUC: 0.5逻辑回归 (Logistic Regression)
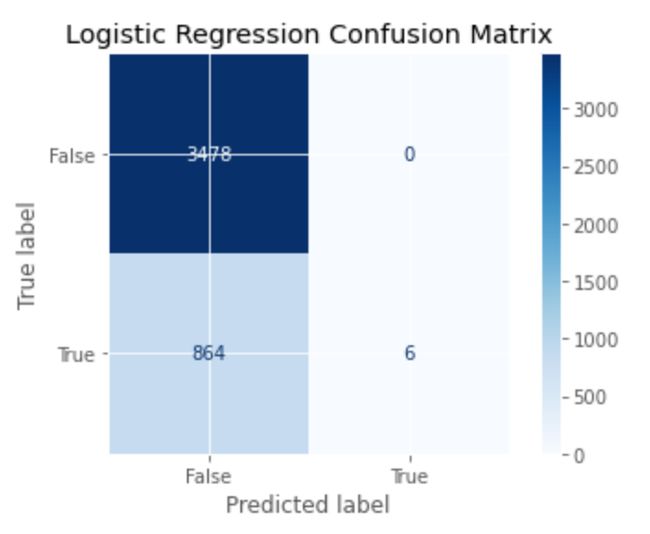
Now we’ll fit a linear model with cross-validation, re-calculate evaluation metrics, and plot a confusion matrix.
现在,我们将使用带有交叉验证的线性模型,重新计算评估指标,并绘制混淆矩阵。
Baseline Validation Accuracy: 0.8
Logistic Regression Validation Accuracy: 0.8013
Baseline Validation ROC AUC: 0.5
Logistic Regression Validation ROC AUC: 0.6424Logistic回归混淆矩阵 (Logistic Regression Confusion Matrix)
随机森林分类器 (Random Forest Classifier)
Now we’ll do the same as above with a tree-based model with bagging (Bootstrap AGGregation).
现在,我们将对带有袋装( B ootstrap AGG规约)的基于树的模型进行与上述相同的操作。
Baseline Validation Accuracy: 0.8
Logistic Regression Validation Accuracy: 0.8013
Random Forest Validation Accuracy: 0.8222
Majority Class Baseline ROC AUC: 0.5
Logistic Regression Validation ROC AUC: 0.6424
Random Forest Validation ROC AUC: 0.8015随机森林混淆矩阵 (Random Forest Confusion Matrix)
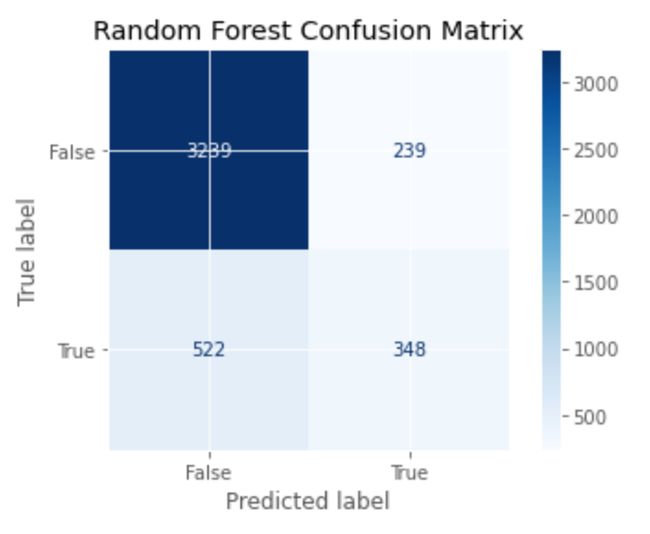
XGBoost分类器 (XGBoost Classifier)
Now we’ll do the same as above with another tree-based model, this time with boosting.
现在,我们将对另一个基于树的模型进行与上述相同的操作,这一次是使用boosting。
Baseline Validation Accuracy: 0.8
Logistic Regression Validation Accuracy: 0.8013
Random Forest Validation Accuracy: 0.8245
XGBoost Validation Accuracy: 0.8427
Majority Class Baseline ROC AUC: 0.5
Logistic Regression Validation ROC AUC: 0.6424
Random Forest Validation ROC AUC: 0.8011
XGBoost Validation ROC AUC 0.84XGBClassifier performes the best in accuracy and ROC AUC.
XGBClassifier在准确性和ROC AUC方面表现最佳。
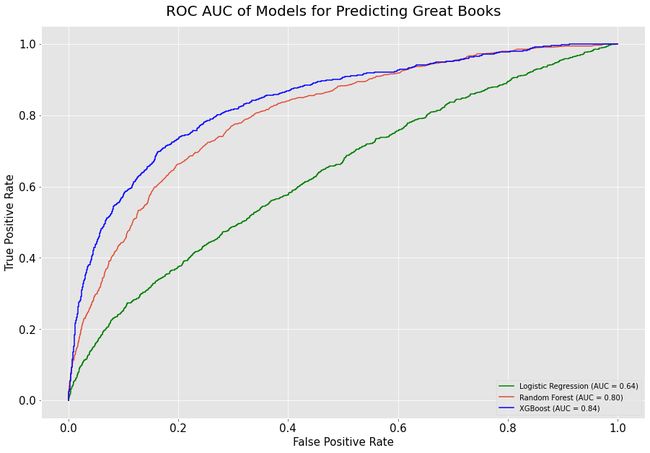
图形和比较模型的ROC AUC (Graph and Compare Models’ ROC AUC)
Below, we see that logistic regression lags far behind XGBoost and Random Forests in achieving a high ROC AUC. Among the top two, XGBoost initially outperforms RandomForest, and then the two roughly converge around FPR=0.6. We see in the lower right legend, however, that XGBoost has the highest AUC of 0.84, followed by Random Forest at 0.80 and Logistic Regression at 0.64.
在下面,我们看到逻辑回归在实现高ROC AUC方面远远落后于XGBoost和Random Forests。 在前两个中,XGBoost最初优于RandomForest,然后两个大致在FPR = 0.6左右收敛。 但是,我们在右下角的图例中看到,XGBoost的AUC最高,为0.84,其次是随机森林,为0.80,逻辑回归为0.64。
In less technical language, the XGBoost model was the best at classifying great books as great (true positives) and not classifying not-great books as great (false positives).
用较少技术的语言,XGBoost模型最擅长将优秀书籍分类为优秀书籍(真实肯定),而不是将非优秀书籍分类为优秀书籍(错误肯定)。
排列重要性 (Permutation Importances)
One intuitive way of identifying whether and to what extent something is important is by seeing what happens when you take it away. This is the best in a situation unconstrained by time and money.
识别某些事物是否重要以及在什么程度上重要的一种直观方法是查看将其拿走时发生的情况。 在不受时间和金钱约束的情况下,这是最好的选择。
But in the real world with real constrains, we can use permutation instead. Instead of eliminating the column values values by dropping them, we eliminate the column’s signal by randomizing it. If the column really were a predictive feature, the order of its values would matter, and shuffling them around would substantially dilute if not destroy the relationship. So if the feature’s predictive power isn’t really hurt or is even helped by randomization, we can conclude that it is not actually important.
但是,在具有实际约束的现实世界中,我们可以改用排列。 我们没有通过丢弃来消除列值的值,而是通过随机化来消除列的信号 。 如果该列确实是一个预测性特征,则其值的顺序将很重要,并且如果不破坏该关系,将它们改组也将大大稀释。 因此,如果该功能的预测能力并没有真正受到损害,甚至没有受到随机化的帮助,我们可以得出结论,它实际上并不重要。
Let’s take a closer look at the permutation importances of our XGBoost model. We’ll have to refit it to be compatible with eli5.
让我们仔细看看XGBoost模型的排列重要性。 我们必须对其进行改装以使其与eli5兼容。
排列重要性分析 (Permutation Importance Analysis)
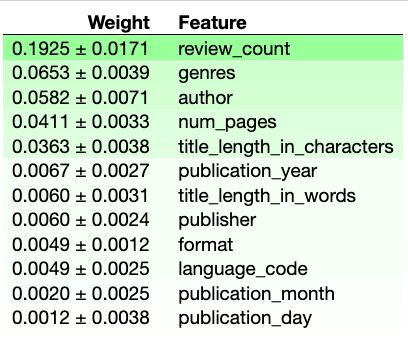
As we assumed at the beginning, review_count matters but it is not suspiciously high. This does not seem to rise to the level of data leakage. What this means is that if you were wondering what book to read next, a useful indicator is how many reviews it has, a proxy for how many others have read it.
正如我们在一开始所假设的那样, review_count重要,但并不高。 这似乎没有达到数据泄漏的程度。 这意味着如果您想知道接下来要读什么书,一个有用的指标是它拥有多少评论,以及多少其他书已经读过它的代理。
We see that genres is the second most important feature for ROC AUC in the XGBoost model.
我们看到genres是XGBoost模型中ROC AUC的第二重要功能。
author is third, which is surprising and perhaps a bit concerning. Because our test set is not big, the model may just be identifying authors whose books are the most highly rated in wilson-adjusted terms, such as J.K. Rowling and Suzanne Colins. More data would be useful to test this theory.
author排名第三,这令人惊讶,也许有点令人担忧。 由于我们的测试集不大,因此该模型可能只是在识别按威尔森调整后的书评鉴最高的作者,例如JK Rowling和Suzanne Colins。 更多的数据将有助于检验这一理论。
Fourth is num_pages. I thought this would be higher for two reasons:
第四是num_pages 。 我认为这会更高,原因有两个:
- Very long books’ ratings seem to have a bit of a ratings bias upward in that people willing to start and finish them will rate them higher. The long length screens out less interested marginal readers, who probably wouldn’t have rated the book highly in the first place. 很长的书的评分似乎有一个较高的评分偏见,因为愿意开始和完成它们的人会给它们更高的评分。 篇幅较长的文章筛选出了那些不太感兴趣的边缘读者,他们可能不会一开始就对这本书给予很高的评价。
- Reading and showing off that you’re reading or have read long books is a sign of high social status. The archetypal example: Infinite Jest. 阅读并炫耀自己正在阅读或已经读过很长的书是社会地位很高的标志。 原型示例:无限开玩笑。
带走 (Takeaway)
We’ve seen how to collect, clean, analyze, visualize, and model data. Some actionable takeaways are that when and who publishes a book doesn’t really matter, but its review count does — the more reviews, the better.
我们已经看到了如何收集,清理,分析,可视化和建模数据。 一些可行的建议是,何时以及谁出版一本书并不重要,但它的评论数却很重要–评论越多越好。
For further analysis, we could break down genres and authors to find out which ones were rated highest. For now, happy reading.
为了进行进一步的分析,我们可以分解genres和authors ,找出哪些被评为最高。 现在,阅读愉快。
翻译自: https://medium.com/@ryan.koul/predicting-great-books-from-goodreads-data-using-python-1d378e7ef926
爬虫goodreads数据