Mybatis 缓存
Mybatis 缓存
我们知道当我们需要去查数据库的时候,都需要与数据库产生连接,然后关闭连接,但是这种动作是十分浪费资源的,这个时候就出现了缓存机制。
缓存机制就是用来解决高并发问题的。
早期的时候网络用户不多的时候,只需要客户端访问服务器,服务器去数据库查询就可以查出来了

但是当后来用户越来越多的时候,访问速度开始越来越慢,然后就出现了Memcached缓存服务器,将一些查询出来的东西放在缓存里面,这样在下次查询相同数据的时候,就不用走数据库了,直接走Memcached缓存服务器了
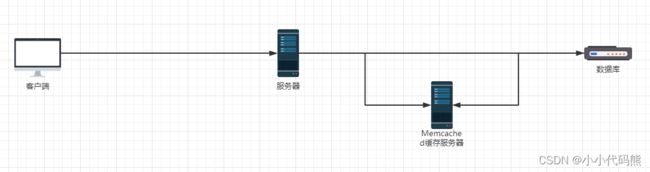
使用缓存能够让我们减少与数据库的交互,来解决高并发问题。
注意点:
-
建议在经常查询且不经常改变的数据上使用缓存。
-
映射语句文件中的所有 select 语句的结果将会被缓存。
-
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
-
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
-
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存失效的情况:
- 查询不同的结果
- 使用增删改语句进行操作时会刷新数据库
- 查询不同的Mapper.xml
- 手动清除缓存
一级缓存
一级缓存是默认开启的,它是SqlSession级别的,一次会话内有效,也就是在SqlSession的开启和关闭期间才有效。
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
ArrayList<Integer> ids = new ArrayList<>();
ids.add(1);
map.put("ids",ids);
mapper.getBlogForeach(map);
mapper.getBlogForeach(map);
sqlSession.close();
}
我们查询相同的一个人,这个人的id都为1
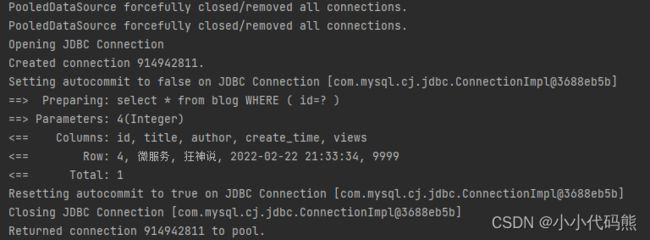
可以看到我们只执行了一次SQL,这就是缓存
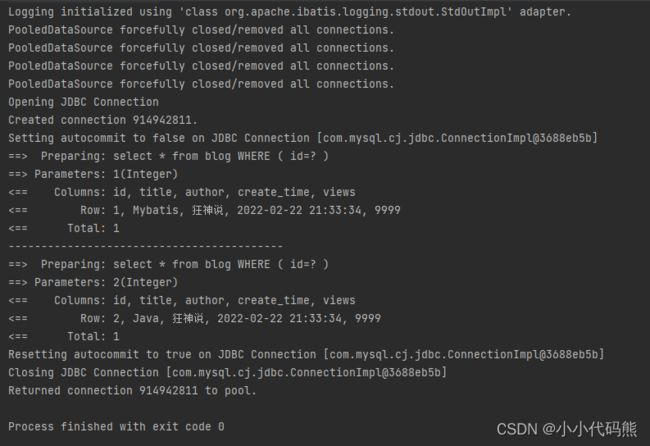
但是当我们查询不同的用户的时候是需要执行两次SQL的
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap map = new HashMap();
ArrayList<Integer> ids = new ArrayList<>();
ids.add(1);
map.put("ids",ids);
mapper.getBlogForeach(map);
System.out.println("------------------------------------------");
ids.remove(0);
ids.add(2);
mapper.getBlogForeach(map);
sqlSession.close();
}
可以看到结果执行了两条SQL
二级缓存
默认情况下,Mybatis只启动了会话等级的缓存也就是一级缓存,而二级缓存是需要手动开启和配置的。
二级缓存是基于namespace级别的,一个命名空间对应一个二级缓存。
工作机制
- 一个会话查询的数据会被保存在一级缓存中
- 但是当这个会话关闭的时候,一级缓存中的数据也就不存在了,但是我们想要的是,会话关闭之后,一级缓存的数据会被保存到二级缓存
- 这样新的会话查询信息的时候就可以从二级缓存中获取数据了
- 不同的Mapper查出的数据会存在自己对应的二级缓存中
使用:
<cache/>
你也可以手动的去定制二级缓存
<cache
flushInterval="60000"
size="512"
readOnly="true"/>
下面写了一个测试类,查询指定id的用户,可以看到我们先关闭了sqlSession,然后使用sqlSession2去查询
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
SqlSession sqlSession2 = MybatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
BlogMapper mapper2 = sqlSession2.getMapper(BlogMapper.class);
HashMap map = new HashMap();
ArrayList<Integer> ids = new ArrayList<>();
ids.add(1);
map.put("ids",ids);
mapper.getBlogForeach(map);
sqlSession.close();
HashMap map2 = new HashMap();
ArrayList<Integer> ids2 = new ArrayList<>();
ids2.add(1);
map2.put("ids",ids2);
mapper2.getBlogForeach(map2);
sqlSession2.close();
}
保存到缓存中的对象实体类必须实现序列化接口Serializable,否则就会报错
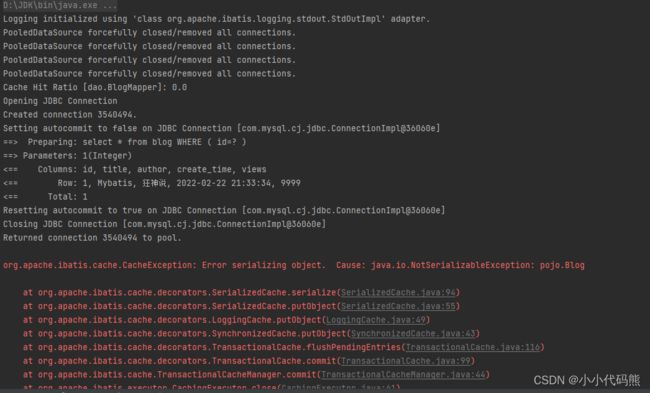
最终结果
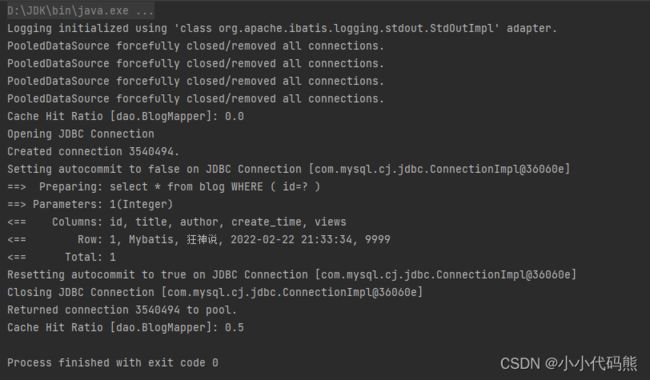
小结
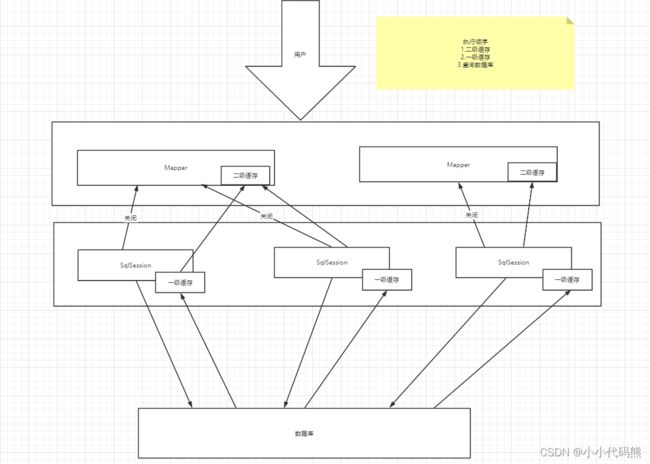
- 每一个Mapper查询的数据都只会存在自己对应的二级缓存中
- 所有的缓存都会先放在一级缓存中
- 只有在一级缓存失效的时候才会转存到二级缓存
Mybatis缓存原理
自定义缓存
我们可以自己定制一些缓存,使用方法如下
1.导包
<dependency>
<groupId>org.mybatis.cachesgroupId>
<artifactId>mybatis-ehcacheartifactId>
<version>1.2.2version>
dependency>
2.开启缓存
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
3.自定义缓存配置文件
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="./tmpdir/Tmp_EhCache"/>
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
ehcache>