【2021Java后端面试题整理】JVM面试题+面经答案
目录
链接一下目录方便查找
菜鸡的2021春招实习之旅(面经+自己总结的笔记)
JVM
1.JVM体系结构
背烂了
2.什么是垃圾?如何判断一个对象是否可以回收?
简单来说就是内存汇中已经不再使用到的空间就是垃圾
使用标记算法:
标记算法有两种,一种引用计数器算法,另一种是可达性分析算法
引用计数器算法就是如果A对象被引用,则给计数器加1,如果引用接触则减去1,下次垃圾回收的时候如果计数器为0则表示为垃圾,但是存在严重的问题,就是如果存在循环引用,会引发内存泄露
可达性分析,就是使用GCRoot作为起点,用引用链能够找到的对象就是可达的,如果不可达就是不可用
使用可达性分析,通过GCRoot为起点,如果一个对象到GC Root没有任何引用链相连,说明此对象不可用
2.5什么时候触发垃圾回收,什么时候放入老年代?
1.eden区满了,触发young gc,触发复制算法,将存活的对象放到s1区;如果eden区再次满了,再次触发young gc,将s1和eden区存活对象放到s2区;
如果超过15次阈值还是长期存活就直接转移到老年代;或者s1区过小,eden区转移不到s区,直接放入老年代 ;或者当前文件过大,直接就转移到老年代
2.老年代垃圾回收
对老年代而言,垃圾没那么多,以前是使用标记-清理算法,但是会有内存碎片,没有连续可用的空间;后续使用标记-整理算法
3.哪些对象可以作为GC Roots
- 虚拟机栈(栈帧中的局部变量)中引用的对象。
- 本地方法栈(native)中引用的对象。
- 方法区中常量引用的对象。
- 方法区中类静态属性引用的对象。
- 所有被同步锁synchronized持有的对象
- Java虚拟机内部的引用:基本数据类型对应的Class对象,一些常驻的异常对象(如: NullPointerException、OutOfMemoryError) ,系统类加载器。
- 反映java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
4.垃圾回收算法
https://blog.csdn.net/qq_41522089/article/details/107801105
5.System.gc()或者Runtime.getRuntime().gc()的调用会怎么样
在默认情况下,通过System.gc()或者Runtime.getRuntime().gc()的调用,会显式触发Full GC,同时对老年代和新生代进行回收,尝试释放被丢弃对象占用的内存。
然而System.gc()调用附带一个免责声明,无法保证对垃圾收集器的调用(无法保证马上触发GC)。
垃圾回收是自动进行的,无序手动
6.OutOfMemoryError
内存溢出和内存泄露
内存溢出就是内存在GC完毕的情况下或者有大文件GC知道自己无法进行清理,就会存在内存溢出
内存泄露就是本来不应该可达的对象,竟然可达了,就是还有引用在上面.说明存在泄露,比如ThreadLocal里面的变量就是一个非常典型的例子
StackOverflowError
栈满会抛出该错误。无限递归就会导致StackOverflowError,是java.lang.Throwable→java.lang.Error→java.lang.VirtualMachineError下的错误。
OOM—Java heap space
堆满会抛出该错误。
OOM—GC overhead limit exceeded
这个错误是指:GC的时候会有“Stop the World",STW越小越好,正常情况是GC只会占到很少一部分时间。但是如果用超过98%的时间来做GC,而且收效甚微,就会被JVM叫停。下例中,执行了多次Full GC,但是内存回收很少,最后抛出了OOM:GC overhead limit exceeded错误。详见GCOverheadDemo。
[GC (Allocation Failure) [PSYoungGen: 2048K->496K(2560K)] 2048K->960K(9728K), 0.0036555 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2544K->489K(2560K)] 3008K->2689K(9728K), 0.0060306 secs] [Times: user=0.08 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 2537K->512K(2560K)] 4737K->4565K(9728K), 0.0050620 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2560K->496K(2560K)] 6613K->6638K(9728K), 0.0064025 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[Full GC (Ergonomics) [PSYoungGen: 2048K->860K(2560K)] [ParOldGen: 6264K->7008K(7168K)] 8312K->7869K(9728K), [Metaspace: 3223K->3223K(1056768K)], 0.1674947 secs] [Times: user=0.63 sys=0.00, real=0.17 secs]
[Full GC (Ergonomics) [PSYoungGen: 2048K->2006K(2560K)] [ParOldGen: 7008K->7008K(7168K)] 9056K->9015K(9728K), [Metaspace: 3224K->3224K(1056768K)], 0.1048666 secs] [Times: user=0.45 sys=0.00, real=0.10 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7082K->7082K(7168K)] 9130K->9130K(9728K), [Metaspace: 3313K->3313K(1056768K)], 0.0742516 secs] [Times: user=0.28 sys=0.00, real=0.07 secs]
·······
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7084K->7084K(7168K)] 9132K->9132K(9728K), [Metaspace: 3313K->3313K(1056768K)], 0.0738461 secs] [Times: user=0.36 sys=0.02, real=0.07 secs]
Exception in thread "main" [Full GC (Ergonomics) [PSYoungGen: 2047K->0K(2560K)] [ParOldGen: 7119K->647K(7168K)] 9167K->647K(9728K), [Metaspace: 3360K->3360K(1056768K)], 0.0129597 secs] [Times: user=0.11 sys=0.00, real=0.01 secs]
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Integer.toString(Integer.java:401)
at java.lang.String.valueOf(String.java:3099)
at jvm.GCOverheadDemo.main(GCOverheadDemo.java:12)
OOM—GC Direct buffer memory
在写NIO程序的时候,会用到ByteBuffer来读取和存入数据。与Java堆的数据不一样,ByteBuffer使用native方法,直接在堆外分配内存。当堆外内存(也即本地物理内存)不够时,就会抛出这个异常。
OOM—unable to create new native thread
在高并发应用场景时,如果创建超过了系统默认的最大线程数,就会抛出该异常。Linux单个进程默认不能超过1024个线程。解决方法要么降低程序线程数,要么修改系统最大线程数vim /etc/security/limits.d/90-nproc.conf。
OOM—Metaspace
使用静态类,将元空间装满了,元空间满了就会抛出这个异常。
7.什么是STW
Stop-the-World,简称STW,指的是GC事件发生过程中,会产生应用程序(对应进程)的停顿。
可达性分析算法中枚举根节点(GC Roots)会导致所有Java执行线程停顿.
1.STW事件和采用哪款GC无关,所有的GC都有这个事件。
2.哪怕是G1也不能完全避免Stop-the-world情况发生,只能说垃圾回收器越来越优秀,回收效率越来越高,尽可能地缩短了暂停时间。
3.STW是JVM在后台自动发起和自动完成的。在用户不可见的情况下,把用户正常的工作线程全部停掉。
4.开发中尽量不要采用System.gc();会导致Stop-the-world的发生。
8.四大引用
强引用:只要有引用,就不回收,一般是new
软引用:在内存足够的情况下不回收,如果内存不够就进行回收,如果内存还不够就OOM
弱引用:只要垃圾回收器一运作就回收
虚引用:形同虚设,get方法为null,一般机制被引用队列锁使用
public class PhantomReferenceDemo {
public static void main(String[] args) throws InterruptedException {
Object o1 = new Object();
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
PhantomReference phantomReference = new PhantomReference(o1, referenceQueue);
System.out.println(o1);
System.out.println(phantomReference.get());
System.out.println(referenceQueue.poll());
System.out.println("===========");
o1 = null;
System.gc();
Thread.sleep(500);
System.out.println(o1);
System.out.println(phantomReference.get());
System.out.println(referenceQueue.poll());//GC后将对象放到引用队列中了
}
}
详解可以见我的博客[https://blog.csdn.net/qq_41522089/article/details/107850681](
9.垃圾收集器
详解可见https://blog.csdn.net/qq_41522089/article/details/107871181
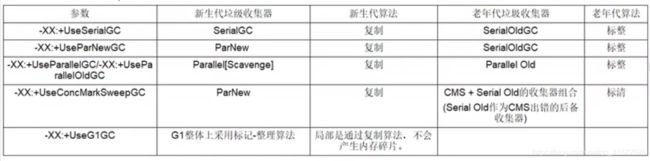
Java 8可以将垃圾收集器分为四类。
串行收集器Serial
为单线程环境设计且只使用一个线程进行GC,会暂停所有用户线程,不适用于服务器。就像去餐厅吃饭,只有一个清洁工在打扫。
并行收集器Parrallel
使用多个线程并行地进行GC,会暂停所有用户线程,适用于科学计算、大数据后台,交互性不敏感的场合。多个清洁工同时在打扫。
并发收集器CMS
用户线程和GC线程同时执行(不一定是并行,交替执行),GC时不需要停顿用户线程,互联网公司多用,适用对响应时间有要求的场合。清洁工打扫的时候,也可以就餐。
G1收集器
对内存的划分与前面3种很大不同,将堆内存分割成不同的区域,然后并发地进行垃圾回收。
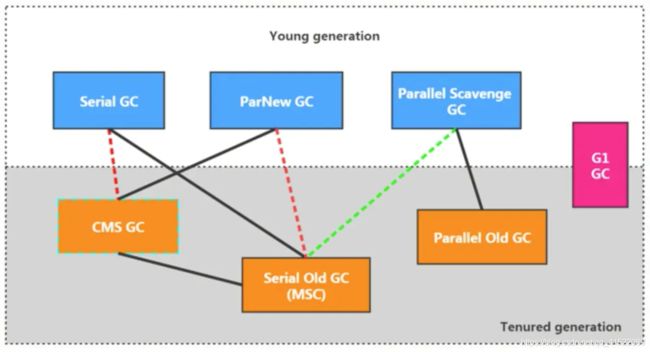
CMS与serial old GC是备选,就是如果无法用原有搭配就使用备选搭配
红线在JDK8以后弃用,9直接remove
绿线在jdk14弃用
CMS在JDK14删除
- 两个收集器间有连线,表明它们可以搭配使用: Serial/Serial Old、Serial/CMS、 ParNew/Serial Old、ParNew/CMS、 Parallel Scavenge/Serial Old、Parallel Scavenge/Parallel Old、G1;
- 其中Serial Old作为CMS 出现"Concurrent Mode Failure"失败的后备预案。
- (红色虚线)由于维护和兼容性测试的成本,在JDK 8时将Serial+CMS、 ParNew+Serial Old这两个组合声明为废弃(JEP 173) ,并在JDK 9中完全取消了这些组合的支持(JEP214),即:移除。
- (绿色虚线)JDK 14中:弃用Parallel Scavenge和SerialOld GC组合(JEP366 )
- (青色虚线)JDK 14中:删除CMS垃圾回收器 (JEP 363)
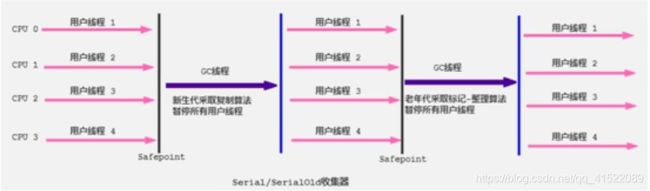
Serial收集器
年代最久远,是Client VM模式下的默认新生代收集器,使用复制算法。优点:单个线程收集,没有线程切换开销,拥有最高的单线程GC效率。缺点:收集的时候会暂停用户线程。
使用-XX:+UseSerialGC可以显式开启,开启后默认使用Serial+SerialOld的组合。
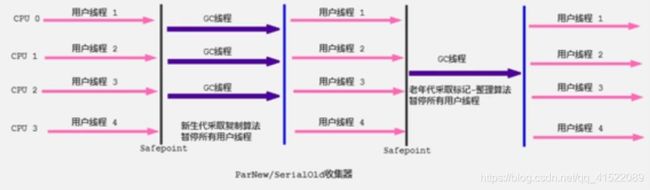
ParNew收集器
也就是Serial的多线程版本,GC的时候不再是一个线程,而是多个,是Server VM模式下的默认新生代收集器,采用复制算法。
使用-XX:+UseParNewGC可以显式开启,开启后默认使用ParNew+SerialOld的组合。但是由于SerialOld已经过时,所以建议配合CMS使用。
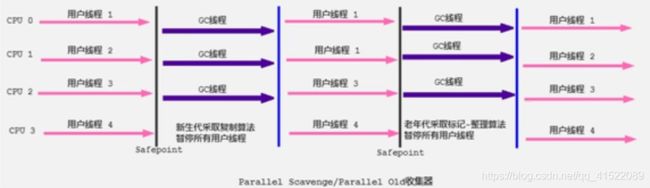
Parallel Scavenge收集器
ParNew收集器仅在新生代使用多线程收集,老年代默认是SerialOld,所以是单线程收集。而Parallel Scavenge在新、老两代都采用多线程收集。Parallel Scavenge还有一个特点就是吞吐量优先收集器,可以通过自适应调节,保证最大吞吐量。采用复制算法。
使用-XX:+UseParallelGC可以开启, 同时也会使用ParallelOld收集老年代。其它参数,比如-XX:ParallelGCThreads=N可以选择N个线程进行GC,-XX:+UseAdaptiveSizePolicy使用自适应调节策略。
SerialOld收集器
Serial的老年代版本,采用标整算法。JDK1.5之前跟Parallel Scavenge配合使用,现在已经不了,作为CMS的后备收集器。
ParallelOld收集器
Parallel的老年代版本,JDK1.6之前,新生代用Parallel而老年代用SerialOld,只能保证新生代的吞吐量。JDK1.8后,老年代改用ParallelOld。
使用-XX:+UseParallelOldGC可以开启, 同时也会使用Parallel收集新生代。
CMS收集器
并发标记清除收集器,是一种以获得最短GC停顿为目标的收集器。适用在互联网或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望停顿时间最短。是G1收集器出来之前的首选收集器。使用标清算法。在GC的时候,会与用户线程并发执行,不会停顿用户线程。但是在标记的时候,仍然会STW。
使用-XX:+UseConcMarkSweepGC开启。开启过后,新生代默认使用ParNew,同时老年代使用SerialOld作为备用。
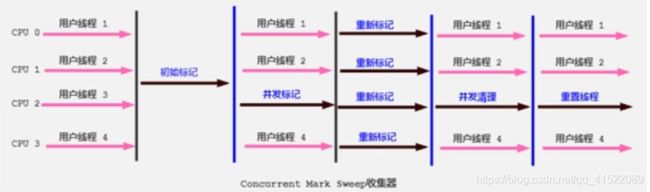
过程
- 初始标记:只是标记一下GC Roots能直接关联的对象,速度很快,需要STW。
- 并发标记:主要标记过程,标记全部对象,和用户线程一起工作,不需要STW。
- 重新标记:修正在并发标记阶段出现的变动,需要STW。
- 并发清除:和用户线程一起,清除垃圾,不需要STW。
优缺点
优点:停顿时间少,响应速度快,用户体验好。
缺点:
- 对CPU资源非常敏感:由于需要并发工作,多少会占用系统线程资源。
- 无法处理浮动垃圾:由于标记垃圾的时候,用户进程仍然在运行,无法有效处理新产生的垃圾。到达阈值会使用full GC
- 产生内存碎片:由于使用标清算法,会产生内存碎片。
GC的选择
组合的选择
- 单CPU或小内存,单机程序
-XX: +UseSerialGC - 多CPU ,需要最大吞吐量,如后台计算型应用
-XX: +UseParallelGC或者
-XX: +UseParallelOldGC - 多CPU ,追求低停顿时间,需快速响应如互联网应用
-XX: +UseConcMarkSweepGC
-XX:+ParNewGC
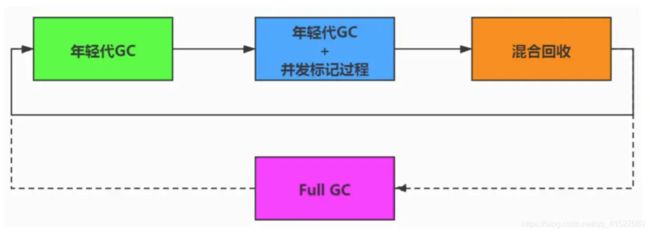
G1收集器
G1收集器与之前垃圾收集器的一个显著区别就是——之前收集器都有三个区域,新、老两代和元空间。而G1收集器只有G1区和元空间。而G1区,不像之前的收集器,分为新、老两代,而是一个一个Region,每个Region既可能包含新生代,也可能包含老年代。
G1收集器既可以提高吞吐量,又可以减少GC时间。最重要的是STW可控,增加了预测机制,让用户指定停顿时间。
使用-XX:+UseG1GC开启,还有-XX:G1HeapRegionSize=n、-XX:MaxGCPauseMillis=n等参数可调。
特点
- 并行和并发:充分利用多核、多线程CPU,尽量缩短STW。
- 分代收集:虽然还保留着新、老两代的概念,但物理上不再隔离,而是融合在Region中。
- 空间整合:
G1整体上看是标整算法,在局部看又是复制算法,不会产生内存碎片。 - 可预测停顿:用户可以指定一个GC停顿时间,
G1收集器会尽量满足。
过程
与CMS类似。
- 初始标记。
- 并发标记。
- 最终标记。
- 筛选回收。
10.JVM参数
1.JVM参数类型
标配参数
比如-version、-help、-showversion等,几乎不会改变。
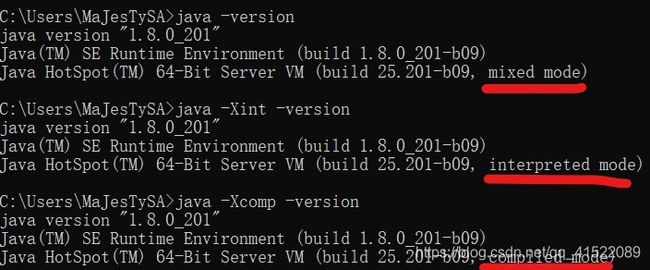
X参数
用得不多,比如-Xint,解释执行模式;-Xcomp,编译模式;-Xmixed,开启混合模式(默认)。
XX参数
重要,用于JVM调优。
查询
jps -l 查询正在运行的Java程序
jinfo -flag 属性名 进程号
布尔类型
公式:-XX:+某个属性、-XX:-某个属性,开启或关闭某个功能。比如-XX:+PrintGCDetails,开启GC详细信息。
KV键值类型
公式:-XX:属性key=值value。比如-XX:Metaspace=128m、-XX:MaxTenuringThreshold=15。
-xms/-xmx参数
-Xms和-Xmx十分常见,用于设置初始堆大小和最大堆大小。第一眼看上去,既不像X参数,也不像XX参数。实际上-Xms等价于-XX:InitialHeapSize,-Xmx等价于-XX:MaxHeapSize。所以-Xms和-Xmx属于XX参数。
查看参数盘点家底
查看默认初始值:java -XX:+PrintFlagsInitial
查看修改后参数
-XX:+PrintFlagsFinal
= 是默认参数,:=是修改后的参数
可以用-XX:+PrintCommandLineFlags查看常用参数。
JVM 常用参数
-Xmx/-Xms
最大和初始堆大小。最大默认为物理内存的1/4,初始默认为物理内存的1/64。
-Xss
等价于-XX:ThresholdStackSize。用于设置单个栈的大小,系统默认值是0,不代表栈大小为0。而是使用默认值,根据操作系统的不同,有不同的值。比如64位的Linux系统是1024K,而Windows系统依赖于虚拟内存。
-Xmn
新生代大小,一般不调。
-XX:MetaspaceSize
设置元空间大小。
-XX:+PrintGCDetails
输出GC收集信息,包含GC和Full GC信息。
-XX:SurvivorRatio
新生代中,Eden区和两个Survivor区的比例,默认是8:1:1。通过-XX:SurvivorRatio=4改成4:1:1
-XX:NewRatio
老生代和新年代的比列,默认是2,即老年代占2,新生代占1。如果改成-XX:NewRatio=4,则老年代占4,新生代占1。
-XX:MaxTenuringThreshold
新生代设置进入老年代的时间,默认是新生代逃过15次GC后,进入老年代。如果改成0,那么对象不会在新生代分配,直接进入老年代。
https://blog.csdn.net/qq_41522089/article/details/107850681)
-XX: +PrintGC 输出Gc日志。类似: -verbose: gc
只会显示总的GC堆的变化
-XX: +PrintGCDetails 输出GC的详细日志
详细显示GC使用情况,收集多少垃圾,内存变化,花费时间等
-XX: +PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
显示启动以来花费的时间
-XX: +PrintGCDateStamps输出GC的时间戳(以日期的形式 )
以yyyy-MM-dd HH:mm:ss的形式输出启动以来的时间
-XX: +PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:. . /logs/gc. log日志文件的输出路径
11.JVMGC + SpringBoot微服务的生产部署和调参优化
实际工作中,如何结合spr ingboot进行调优?
JVMGC -->>调优–>> spr ingboot微服务的生产部
署和调参优化
1 IDEA开发完微服务工程
2 maven进行clean package
3要求微服务启动的时候,同时配置我们的JVM/GC的调优参数
3.1内
3.2外===>重点
4公式
java -server jvm的各种参数 -jar 第一步上面的jar/war包名字
12.栈帧的里面具体有什么
https://blog.csdn.net/qq_41522089/article/details/107596640
13.栈和堆的区别
一、堆栈空间分配区别:
1、栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2、堆(操作系统): 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二、堆栈缓存方式区别:
1、栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2、堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三、堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
14.线程上下文加载器打破双亲委派机制
线程上下文加载器的重要性:
SPI (Service Provider Interface)
父ClassLoader可以使用当前线程Thread.currentThread().getContextClassLoader()所指定的classloader加载的类。
这就改变了父ClassLoader不能使用子ClassLoader或是其他没有直接父子关系的CLassLoader加载的类的情况,即改变了
双亲委托模型。
线程上下文加载器就是当前线程的Current ClassLoader
在双亲委托模型下,类加载器由下至上的,即下层的类加载器会委托上层进行加载。但是对于SPI来说,有些接口是java
核心库所提供的,而java核心库是由启动类加载器来加载的,而这些接口的实现来自于不同的jar包(厂商提供),java
的启动类加载器是不会加载其他来源的jar包,这样传统的双亲委托模型就无法满足SPI的要求,而通过给当前线程设置上下文加载器
就可以设置上下文类加载器来实现对于接口实现类的加载。
如果没有通过与setContextClassLoader(ClassLoader classloader)进行设置的话,线程将继承其父线程的上下文类加载器。
Java应用运行时的初始线程的上下文加载器是系统类加载器,在线程中运行的代码可以通过该类加载器来加载类与资源
15.new一个对象的过程

Java new一个对象有以下几步:
1.首先查看常量池,看看有没有该类的符号引用,如果没有符号引用的话就会触发创建对象,总体又分为这个类加载过程和对象内存分配的过程
2.首先是触发类加载机制,加载链接初始化;将字节码文件使用类加载器进行加载,然后链接分为验证,准备和解析,验证就是验证字节码文件的安全性,准备就是将对应的类成员变量进行赋默认值,常量直接赋值,解析就是将符号引用转换成直接引用,经过初始化过程,就是调用方法进行初始化,为静态变量赋值,执行静态代码块
3.之后就是进行对象内存分配;如果已经有过符号引用可以省去第二步类加载过程.首先在堆中分配一块内存,如果说是连续空间的话,就是用指针碰撞在空闲的位置开辟一块空间;如果是空闲列表,就是找一块足够大的空间存储内存.然后设置对象头;在之后是调用对象的初始化方法;最后在栈中引用新对象
如果经过逃逸分析以后,对象不发生逃逸,那么可以分配到栈上,如果不可以,尝试使用TLAB进行分配,再不行就进行堆内存,指针碰撞和空闲列表的方式,如果eden内存不够则分给老年代