大数据实战之离线数仓整体规划
前言
大家好,从今天开始,我们将进入到离线数仓项目搭建系列,一来是想对自己所学和实践做一个系统性归纳和结合,二来也是为了给大家多分享一些心得。【在此过程中,有任何疑问或想法,均可在QQ群139809179中提出交流】
背景
2014年,马云爸爸提出,“人类正从 IT 时代走向 DT (Data Technology)时代“。JDC的报告显示:预计到 2020 年,全球数据总量将超过 40ZB (相当于 40万亿 GB )。“十三五”规划纲要也明确提出,要实施国家大数据战略。一切的一切,都预示着,未来,将是属于大数据的时代,我们每个人都将处于或间接处于大数据的风暴眼当中。
而数据的源源不断的产生,如果不能很好的加以利用(存储、规划、分析并产生价值),那就是一堆烂泥,对企业来说,更是一场“灾难”。现在业界内数仓搭建通用做法是向阿里靠齐,下图是本次离线数仓的规划图【部分未截全】
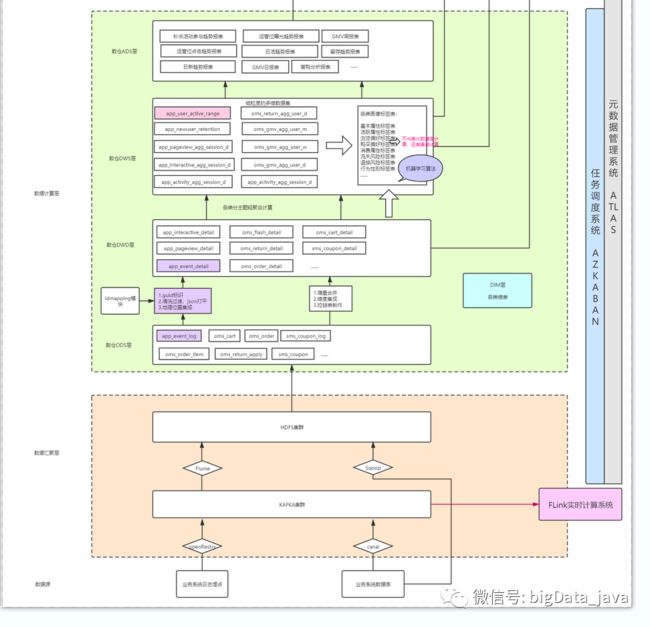
项目概况
从项目架构来说,可以分为数据采集层、数据计算层、数据服务层、数据应用层,调度系统、血缘管理系统等组成。
数据采集层
数据采集层,即将数据从数据产生的来源处,进行采集,并储存起来。
数据来源:web端,前端日志埋点,会将用户的行为数据通过请求日志服务器,并储存在日志服务器上。APP端:阿里采用的是UserTrackAPP端日志采集技术方案。
web端日志采集数据样例:
{"account": "OojqS36Vk","carrier": "中国电信","cookieid": "QIGfKLZOy3mz","ip": "208.67.109.145","netType": "WIFI","osName": "android","osVersion": "8.5","resolution": "2048*1024","sessionId": "7qSqmopgg0q","timeStamp": 1595752563993,“userAgent” :”Chrome 80.47.4.400 webkit”"eventId": "adClick","properties": {"adCampain": "15","adId": "5","adLocation": "2","pageId": "475"},}
采集技术:
目前离线直接使用flume将日志服务器数据采集到hdfs中。
采集组件:flume。从指定的日志服务器目录下将相应的日志文件采集到hdfs中,作为数据仓库当中的ods层,即原始数据层,也叫数据贴源层。
存储格式:以json格式文本文件存储
数据内容:存放flume采集过来的原始日志。
注:flume中可加拦截器,对日志数据进行初步过滤集成,比如非法数据。
数据计算层
此层可分为五层:ods原始数据层、dwd数据明细层、dws数据汇总层、ads数据应用层、dim维表层。此四层数据均存储于hdfs中,使用hive展示数据。存储格式均为orc+parquet。
从计算的频率来看,可以分为离线数仓和实时数仓。本次只讨论离线数仓。离线数仓主要是指传统的数据仓库概念,数据计算频率主要以天(包含小时、周和月)为单位,比如T-1,则每天凌晨处理上一天的数据。
计算引擎:hive/spark
数据服务层
当数据被整合和计算好之后,需要提供给产品和应用。针对不同的需求,数据服务层的数据源可以架构在多种数据库之上,比如mysql和hbase、es等,数据服务层通过接口服务化的方式可以对外提供数据服务。
数据应用层
数据已经准备好了,可以通过合适的应用提供给客户,让数据发挥最大的价值。比如推荐系统、用户画像系统等。
今天的学习差不多到这,后续开启离线数仓实战成神之路。
更多学习、面试资料尽在微信公众号:Hadoop大数据开发

一文带你走进hive的世界系列(建议收藏)
你要悄悄学会HBase,然后惊艳所有人(建议收藏)
你不知道的查找算法之布隆过滤器(建议收藏)
手把手教你搭建hadoop集群
这些linux命令,你都会吗?
庖丁解牛式IOC和DI
没有对象怎么办?new一个(面向对象OOP六大原则系列上,建议收藏)
没有对象怎么办?new一个(面向对象OOP六大原则系列下,建议收藏)
hive中高频函数使用及示例!(建议收藏)