Spark基础学习笔记02:搭建Spark环境
文章目录
- 零、本讲学习目标
- 一、搭建Spark单机版环境
-
- (一)在私有云上创建ied实例
- (二)修改ied实例主机名
- (三)设置IP地址与主机名的映射
- (四)通过SecureCRT访问ied虚拟机
- (五)下载、安装和配置JDK
- (六)下载Spark安装包到hw_win7虚拟机
- (七)将Spark安装包上传到ied虚拟机
- (八)将Spark安装包解压到指定目录
- (九)配置Spark环境变量
- (十)使用SparkPi来计算Pi的值
- (十一)使用Scala版本Spark-Shell
- (十二)使用Python版本Spark-Shell
- (十三)初步了解RDD
-
-
- 例1、创建一个RDD
- 例2、调用转化操作filter()
- 例3、调用first() 行动操作
-
- 二、搭建Spark伪分布式环境
-
- (一)搭建伪分布式Hadoop
-
- 1、利用hw_win7实例上的SecureCRT登录ied实例
- 2、配置免密登录
-
- (1)生成密钥对
- (2)将生成的公钥发送到本机(虚拟机ied)
- (3)验证虚拟机是否能免密登录本机
- 3、下载与Spark版本匹配的Hadoop安装包
- 4、将Hadoop安装包上传到虚拟机ied的/opt目录
- 5、将Hadoop安装包解压到指定目录
- 6、查看Hadoop的安装目录
-
- (1)进入Hadoop安装目录查看
- (2)查看etc/hadoop子目录
- (3)查看sbin子目录
- 7、配置Hadoop实现伪分布式
-
- (1)修改环境配置文件 - hadoop-env.sh
- (2)修改核心配置文件 - core-site.xml
- (3)修改分布式文件系统配置文件 - hdfs-site .xml
- (4)修改MapReduce配置文件 - mapred-site.xml
- (5)修改yarn配置文件 - yarn-site.xml
- (6)配置hadoop的环境变量
- 8、创建存放生成文件的临时目录
- 9、格式化名称节点
- 10、启动hadoop服务
- 11、停止hadoop服务
- (二)搭建伪分布式Spark
-
- 1、进入spark配置目录
- 2、生成环境配置文件 - spark-env.sh
- 3、修改环境配置文件 - spark-env.sh
- 4、配置spark环境变量
- (三)启动并使用伪分布式Spark
-
- 1、启动hadoop服务
- 2、启动spark服务
- 3、进入交互式Spark Shell
-
- (1)scala版spark shell
- (2)python版spark shell
- 4、Web界面访问spark
- 三、搭建Spark完全分布式环境
-
- (一)Spark集群拓扑
- (二) 搭建ZooKeeper集群
-
- 1、私有云上创建三台虚拟机
- 2、利用SecureCRT登录三台虚拟机
-
- (1)登录master虚拟机
- (2)登录slave1虚拟机
- (3)登录slave2虚拟机
- 3、查看三台虚拟机主机名
- 4、配置三台虚拟机IP-主机名映射
-
- (1)配置master虚拟机IP-主机名映射
- (2)配置slave1虚拟机IP-主机名映射
- (3)配置slave2虚拟机IP-主机名映射
- 5、关闭与禁用防火墙
-
- (1)master虚拟机
- (2)slave1虚拟机
- (3)slave2虚拟机
- 6、关闭SeLinux安全机制
-
- (1)master虚拟机
- (2)slave1虚拟机
- (3)slave2虚拟机
- 7、设置三台虚拟机相互免密登录
-
- (1)master虚拟机免密登录master、slave1与slave2
- (2)slave1虚拟机免密登录master、slave1与slave2
- (3)slave2虚拟机免密登录master、slave1与slave2
- 8、在三台虚拟机上安装lrzsr
-
- (1)在master虚拟机上安装lrzsz
- (2)在slave1虚拟机上安装lrzsz
- (3)在slave2虚拟机上安装lrzsz
- 9、在三台虚拟机上安装配置JDK
-
- (1)在master虚拟机上安装配置JDK
- (2)在master虚拟机上安装的JDK免密拷贝到slave1虚拟机
- (3)在master虚拟机上安装的JDK免密拷贝到slave2虚拟机
- 10、安装配置ZooKeeper(可选)
-
- (1)在虚拟机master上安装配置ZooKeeper
- (2)在虚拟机slave1上安装配置ZooKeeper
- (3)在虚拟机slave2上安装配置ZooKeeper
- 11、启动与关闭集群ZooKeeper服务
-
- (1)在虚拟机master上启动ZK服务
- (2)在虚拟机slave1上启动ZK服务
- (3)在虚拟机slave2上启动ZK服务
- (4) 在三个虚拟机上查询ZK服务状态
- (5)测试集群三个节点是否同步
- (6)关闭三台虚拟机上的ZK服务
- (三)配置完全分布式Hadoop
-
- 1、在master虚拟机上安装配置hadoop
-
- (1)上传hadoop安装包到/opt目录
- (2)将hadoop安装包解压到指定位置
- (3)配置hadoop环境变量
- (4)编辑环境配置文件 - hadoop-env.sh
- (5)编辑核心配置文件 - core-site.xml
- (6)编辑HDFS配置文件 - hdfs-site.xml
- (7)编辑MapReduce配置文件 - mapred-site.xml
- (8)编辑yarn配置文件 - yarn-site.xml
- (9)编辑slaves文件
- 2、在slave1虚拟机上安装配置hadoop
-
- (1)将master虚拟机上hadoop安装目录远程拷贝到slave1虚拟机
- (2)将master虚拟机上环境配置文件远程拷贝到slave1虚拟机
- (3)在slave1虚拟机上让环境配置生效
- 3、在slave2虚拟机上安装配置hadoop
-
- (1)将master虚拟机上hadoop安装目录远程拷贝到slave2虚拟机
- (2)将master虚拟机上环境配置文件远程拷贝到slave2虚拟机
- (3)在slave2虚拟机上让环境配置生效
- 4、在master虚拟机上格式化名称节点
- 5、启动与关闭集群Hadoop服务
-
- (1)在master虚拟机上启动hadoop服务
- (2)利用Web界面查看hadoop集群情况
- (3) 停止hadoop服务
- (四)配置完全分布式Spark
-
- 1、在master主节点上安装配置Spark
-
- (1)上传spark安装包到master虚拟机
- (2)将spark安装包解压到master虚拟机指定目录
- (3)配置spark环境变量
- (3)编辑spark环境配置文件 - spark-env.sh
- (4)创建spark缺省配置文件 - spark-defaults.conf
- (5)创建slaves文件,添加三个节点
- 2、在slave1从节点上安装配置Spark
-
- (1)把master虚拟机上的spark安装目录远程拷贝到slave1虚拟机相同位置
- (2)将master虚拟机上环境变量配置文件分发到slave1虚拟机
- (3)在slave1虚拟机上让spark环境配置文件生效
- 3、在slave2从节点上安装配置Spark
-
- (1)把master虚拟机上的spark安装目录远程拷贝到slave2虚拟机相同位置
- (2)将master虚拟机上环境变量配置文件分发到slave2虚拟机
- (3)在slave2虚拟机上让spark环境配置文件生效
- (五)启动并使用完全分布式Spark
-
- 1、启动hadoop的dfs服务
- 2、启动hadoop的yarn服务
- 3、启动Spark服务
- 3、Spark监控 - 通过浏览器访问管理界面
- 4、启动Scala版Spark Shell
- 5、关闭spark服务
零、本讲学习目标
- 学会搭建Spark单机版环境
- 学会搭建Spark伪分布式环境
- 掌握搭建Spark完全分布式环境
一、搭建Spark单机版环境
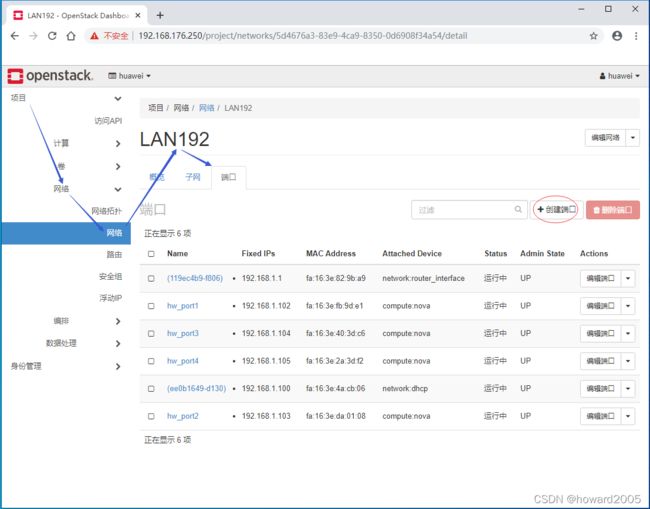
(一)在私有云上创建ied实例
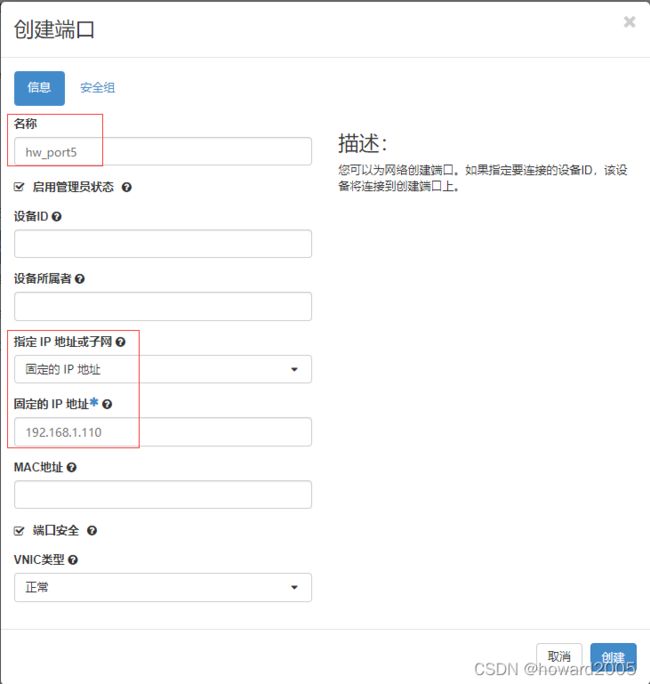
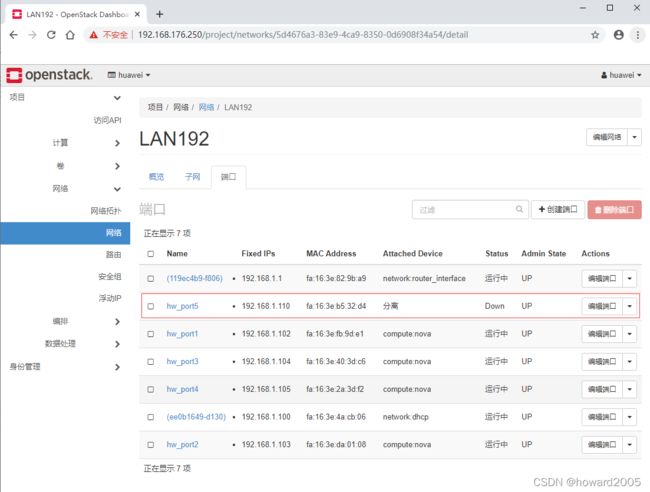
- 给子网LAN192创建端口 - hw_port5
- 单击【创建端口】按钮
- 单击【创建】按钮
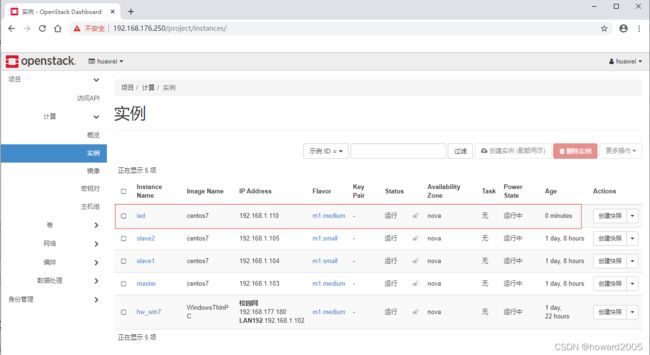
- 项目 - 计算 - 实例
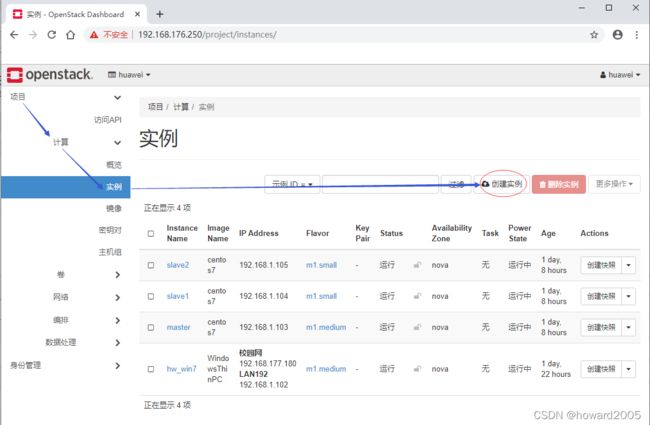
- 单击【创建实例】按钮
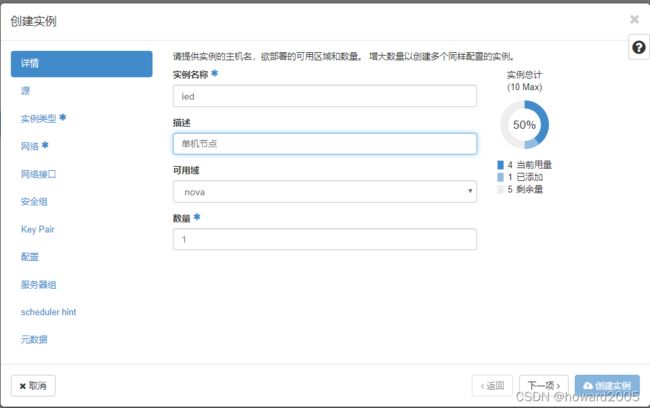
- 单击【下一项】按钮
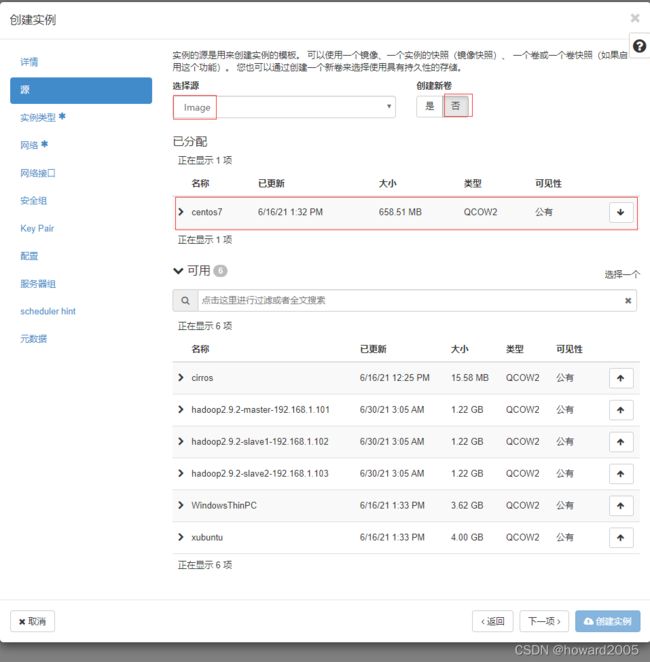
- 单击【下一项】按钮

- 单击【下一项】按钮
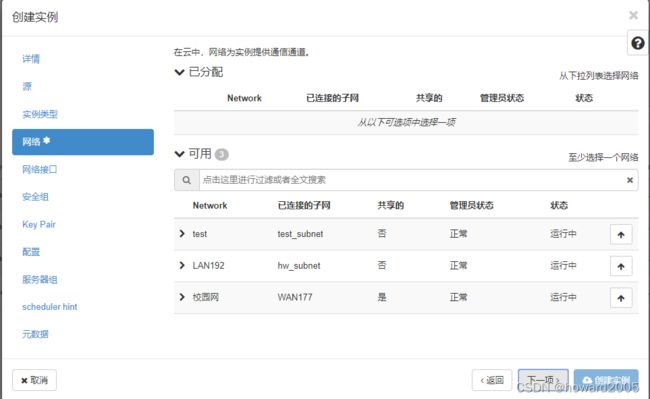
- 单击【下一项】按钮
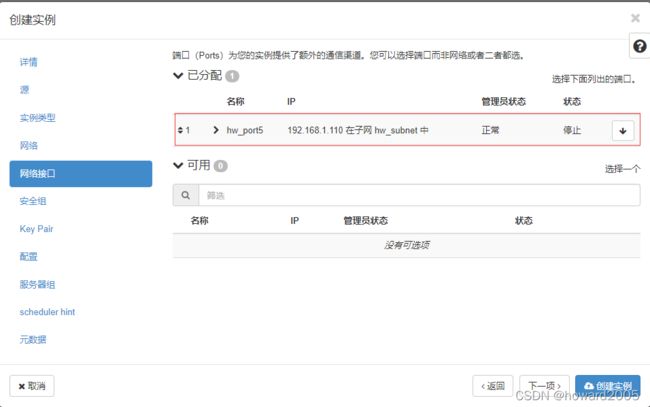
- 单击【创建实例】按钮
(二)修改ied实例主机名
- 登录ied实例

- 查看主机名

- 修改主机名

- 执行
reboot命令,重启ied虚拟机
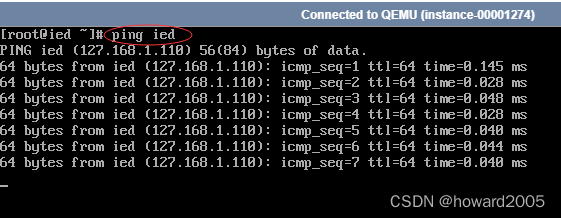
(三)设置IP地址与主机名的映射
- 执行命令:
vi /etc/hosts

- 存盘退出,这样
ping ied就相当于ping 192.168.1.110
(四)通过SecureCRT访问ied虚拟机
- 本机远程桌面连接hw_win7虚拟机
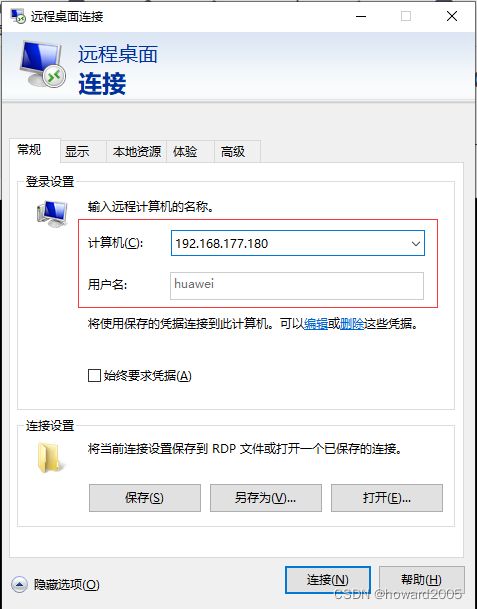
- 启动hw_win7虚拟机上的SecureCRT
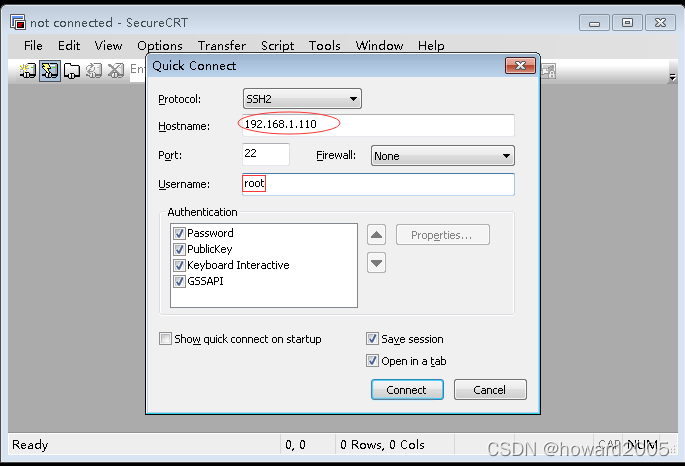
- 新建一个连接,访问ied虚拟机
- 单击【Connect】按钮

- 单击【Accept & Save】按钮

- 单击【OK】按钮
- 关闭连接,修改连接名为ied
- 单击【Connect】按钮
- 设置选项

- 单击【OK】按钮
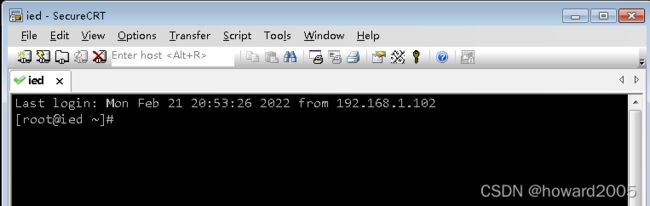
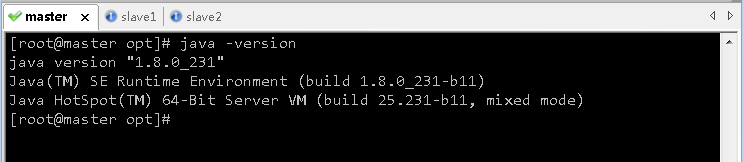
- 查看一下是否安装了Java
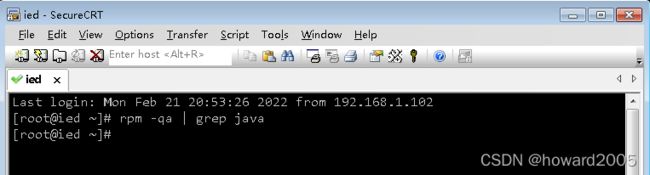
- 说明ied虚拟机上没有安装Java
(五)下载、安装和配置JDK
- 下载链接:https://pan.baidu.com/s/1RcqHInNZjcV-TnxAMEtjzA 提取码:jivr
- 下载到hw_win7虚拟机
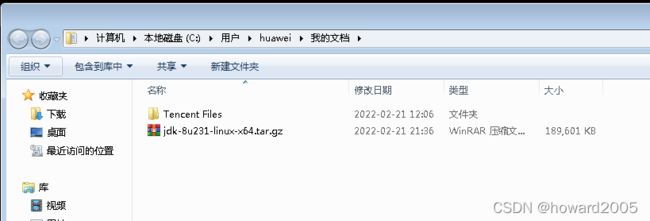
- 将Java安装包上传到ied虚拟机/opt目录,但是rz命令不能用
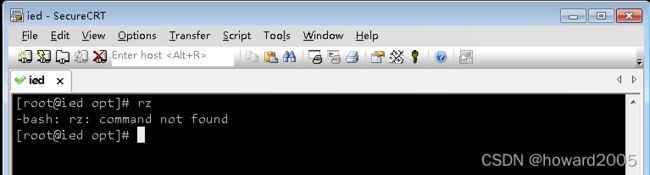
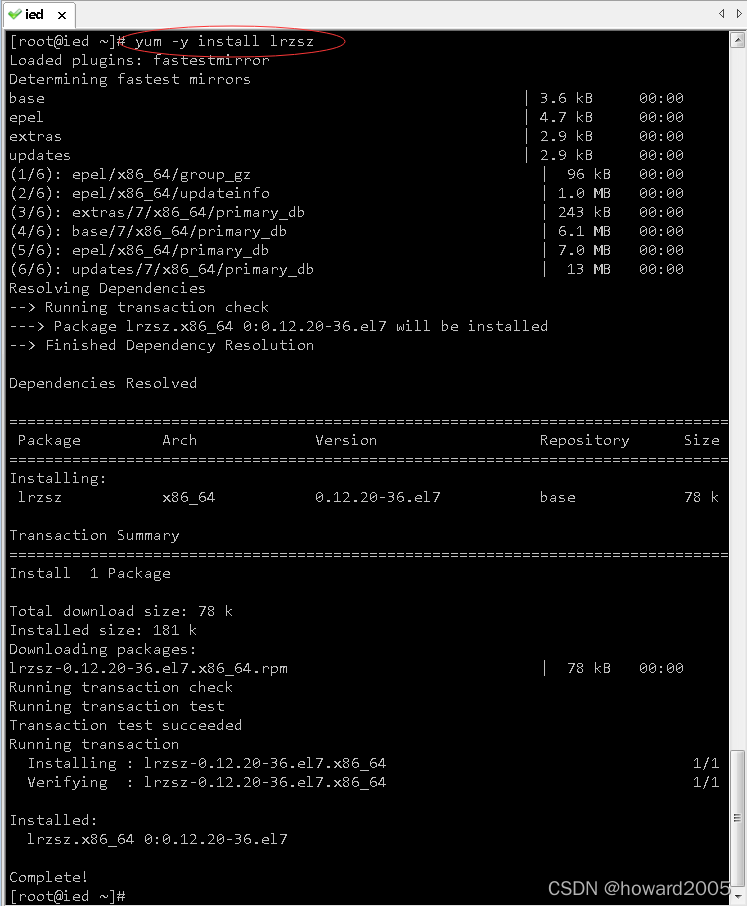
- rz命令无法使用,需要安装lrzsz。lrzsz是一个unix通信套件提供的X,Y,和ZModem文件传输协议。Windows 需要向CentOS服务器上传文件,可直接在CentOS上执行命令
yum -y install lrzsz,程序会自动安装好。要下载,则sz[找到你要下载的文件];要上传,则rz浏览找到你本机要上传的文件。
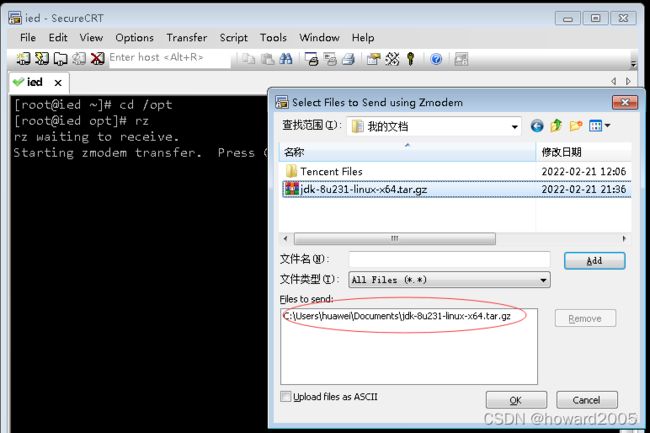
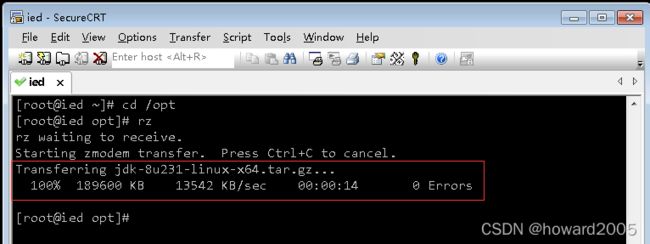
- 利用rz命令上传Java安装包到ied虚拟机/opt目录
- 执行
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local,将Java安装包解压到/usr/local

- 执行
yum -y install vim,安装vim编辑器
- 配置Java环境变量
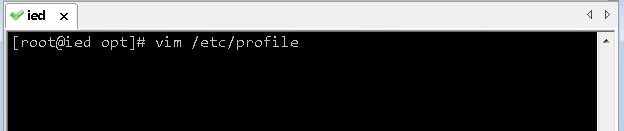
JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
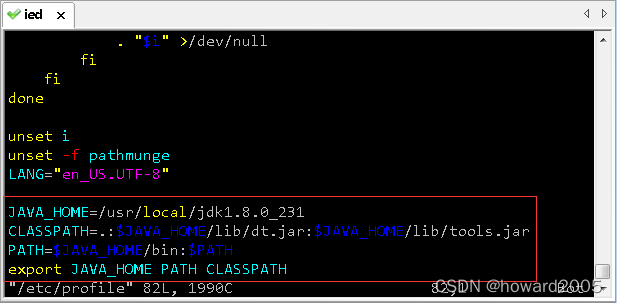
- 存盘退出,让环境配置生效

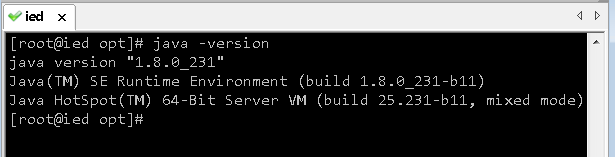
- 在任意目录下都可以查看JDK版本
(六)下载Spark安装包到hw_win7虚拟机
- 下载链接:https://pan.baidu.com/s/1dLKt5UJgpqehRNNDcoY2DQ 提取码:zh0x
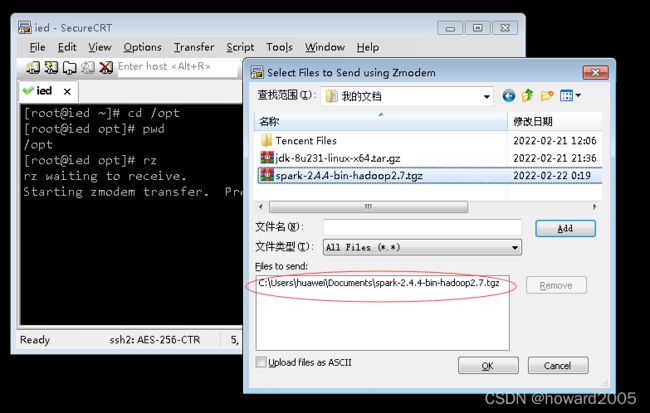
(七)将Spark安装包上传到ied虚拟机
- 执行
cd /opt,进入/opt目录

- 利用rz命令上传Spark安装包
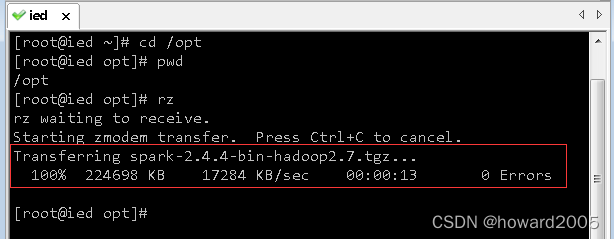
(八)将Spark安装包解压到指定目录
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local

- 查看解压之后的spark目录

(九)配置Spark环境变量
- 执行
vim /etc/profile

JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
export JAVA_HOME SPARK_HOME PATH CLASSPATH
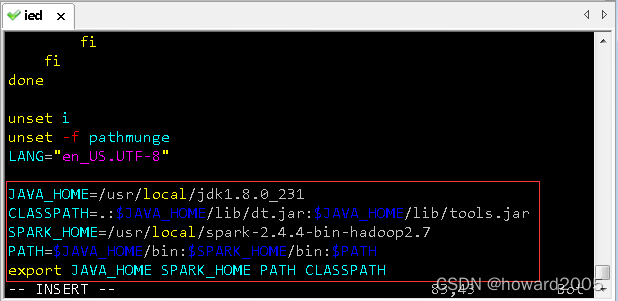
- 存盘退出,让环境配置生效

(十)使用SparkPi来计算Pi的值
run-example SparkPi 2 # 其中参数2是指两个并行度
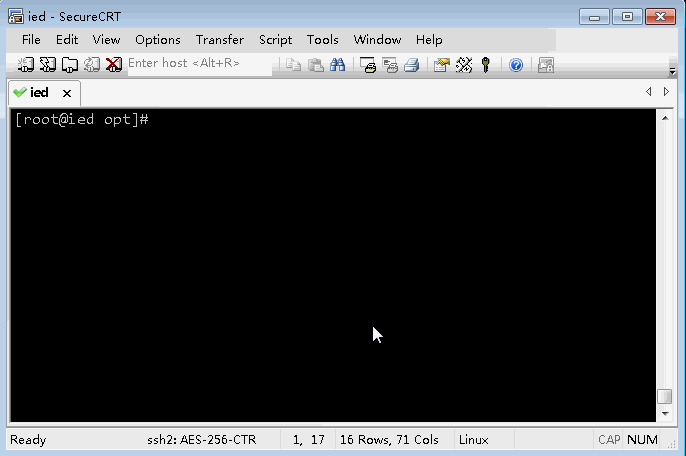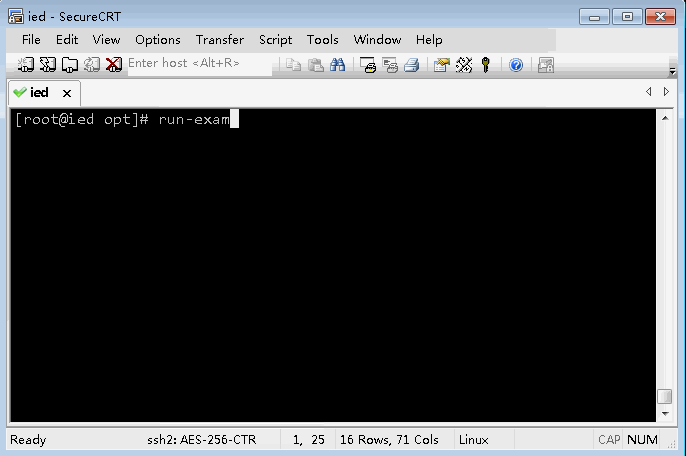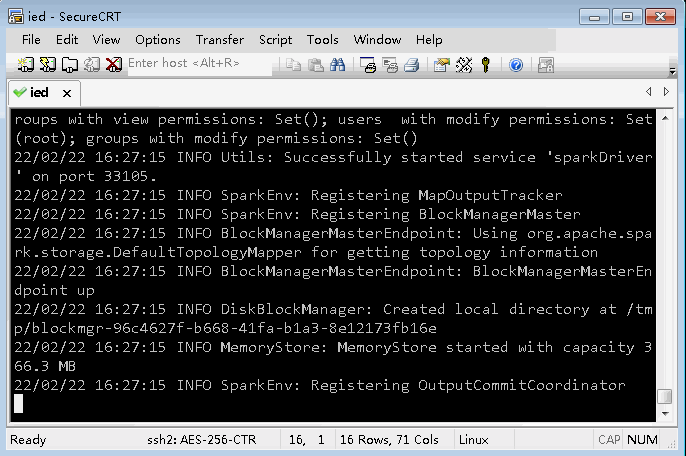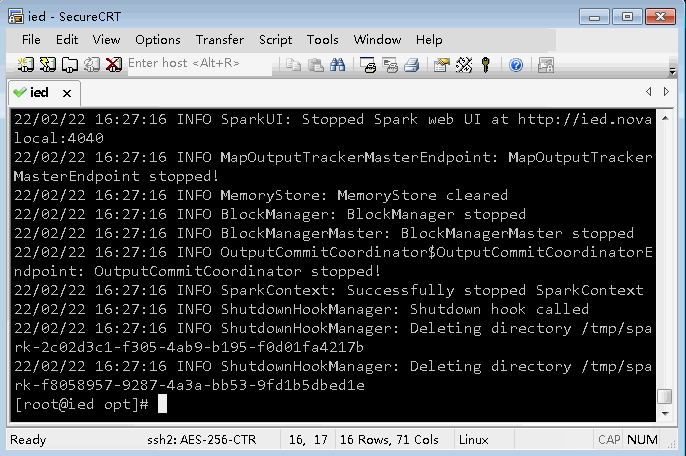
[root@ied opt]# run-example SparkPi 2
22/02/20 04:24:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/02/20 04:24:34 INFO SparkContext: Running Spark version 2.4.4
22/02/20 04:24:34 INFO SparkContext: Submitted application: Spark Pi
22/02/20 04:24:34 INFO SecurityManager: Changing view acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing view acls groups to:
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls groups to:
22/02/20 04:24:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/02/20 04:24:35 INFO Utils: Successfully started service 'sparkDriver' on port 41942.
22/02/20 04:24:35 INFO SparkEnv: Registering MapOutputTracker
22/02/20 04:24:36 INFO SparkEnv: Registering BlockManagerMaster
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/02/20 04:24:36 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-8de32b0e-530a-47ba-ad2d-efcfaa2af498
22/02/20 04:24:36 INFO MemoryStore: MemoryStore started with capacity 413.9 MB
22/02/20 04:24:36 INFO SparkEnv: Registering OutputCommitCoordinator
22/02/20 04:24:36 INFO Utils: Successfully started service 'SparkUI' on port 4040.
22/02/20 04:24:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://ied:4040
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar at spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar with timestamp 1645302276946
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/scopt_2.11-3.7.0.jar at spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:37 INFO Executor: Starting executor ID driver on host localhost
22/02/20 04:24:37 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 33814.
22/02/20 04:24:37 INFO NettyBlockTransferService: Server created on ied:33814
22/02/20 04:24:37 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/02/20 04:24:37 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMasterEndpoint: Registering block manager ied:33814 with 413.9 MB RAM, BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:39 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
22/02/20 04:24:39 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
22/02/20 04:24:39 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
22/02/20 04:24:39 INFO DAGScheduler: Parents of final stage: List()
22/02/20 04:24:39 INFO DAGScheduler: Missing parents: List()
22/02/20 04:24:39 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1936.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1256.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ied:33814 (size: 1256.0 B, free: 413.9 MB)
22/02/20 04:24:40 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1161
22/02/20 04:24:40 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
22/02/20 04:24:40 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
22/02/20 04:24:40 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7866 bytes)
22/02/20 04:24:40 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
22/02/20 04:24:40 INFO Executor: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:41 INFO TransportClientFactory: Successfully created connection to ied/192.168.225.100:41942 after 185 ms (0 ms spent in bootstraps)
22/02/20 04:24:41 INFO Utils: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar to /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/fetchFileTemp2787747616090799670.tmp
22/02/20 04:24:42 INFO Executor: Adding file:/tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/scopt_2.11-3.7.0.jar to class loader
22/02/20 04:24:42 INFO Executor: Fetching spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar with timestamp 1645302276946
22/02/20 04:24:42 INFO Utils: Fetching spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar to /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/fetchFileTemp5384793568751348333.tmp
22/02/20 04:24:42 INFO Executor: Adding file:/tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/spark-examples_2.11-2.4.4.jar to class loader
22/02/20 04:24:42 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 910 bytes result sent to driver
22/02/20 04:24:42 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7866 bytes)
22/02/20 04:24:42 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
22/02/20 04:24:42 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 867 bytes result sent to driver
22/02/20 04:24:42 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1654 ms on localhost (executor driver) (1/2)
22/02/20 04:24:42 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 139 ms on localhost (executor driver) (2/2)
22/02/20 04:24:42 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
22/02/20 04:24:42 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 2.597 s
22/02/20 04:24:42 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.956212 s
Pi is roughly 3.1441757208786045
22/02/20 04:24:42 INFO SparkUI: Stopped Spark web UI at http://ied:4040
22/02/20 04:24:42 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/02/20 04:24:42 INFO MemoryStore: MemoryStore cleared
22/02/20 04:24:42 INFO BlockManager: BlockManager stopped
22/02/20 04:24:42 INFO BlockManagerMaster: BlockManagerMaster stopped
22/02/20 04:24:42 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/02/20 04:24:42 INFO SparkContext: Successfully stopped SparkContext
22/02/20 04:24:42 INFO ShutdownHookManager: Shutdown hook called
22/02/20 04:24:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf
22/02/20 04:24:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-e8fe131d-a733-466f-9665-4277ace75a06
看第61行:Pi is roughly 3.1441757208786045
(十一)使用Scala版本Spark-Shell
- 执行 spark-shell 命令启动Scala版的Spark-Shell
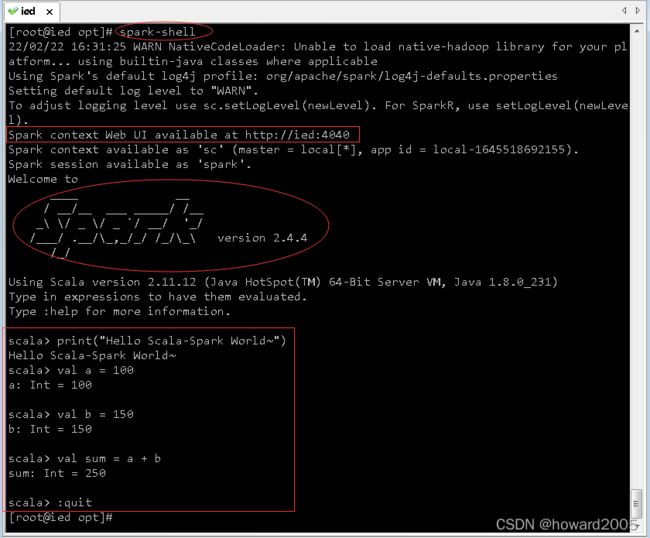
- 利用print函数输出了一条信息,做了一个简单的加法运算
(十二)使用Python版本Spark-Shell
- 执行 pyspark 命令启动Python版的Spark-Shell
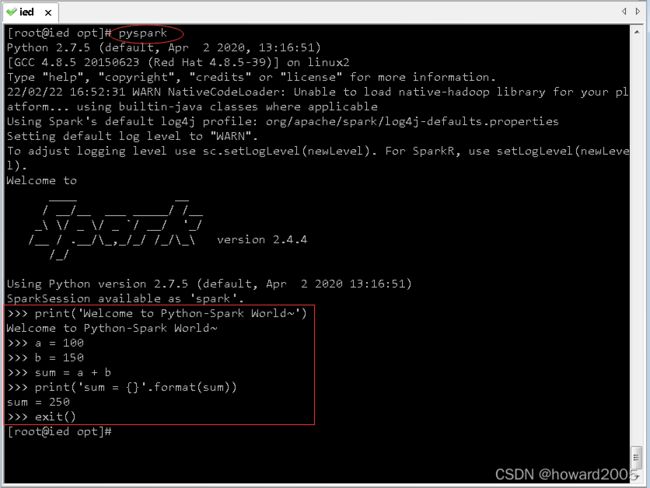
- 在hw_win7虚拟机上创建test.txt文件
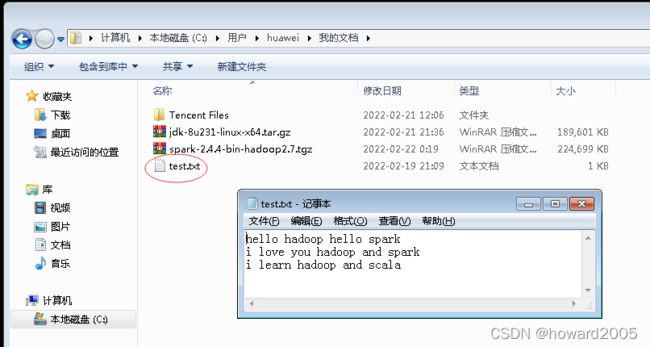
- 上传test.txt文件到ied虚拟机的/opt目录

- 执行 pyspark 启动 spark shell

(十三)初步了解RDD
- Spark 中的RDD (Resilient Distributed Dataset) 就是一个不可变的分布式对象集合。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list 和set)。
例1、创建一个RDD
- 在Python 中使用textFile() 创建一个字符串的RDD
>>> lines = sc.textFile('test.txt')
- 创建出来后,RDD 支持两种类型的操作: 转化操作(transformation) 和行动操作(action)。转化操作会由一个RDD 生成一个新的RDD。另一方面,行动操作会对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中。
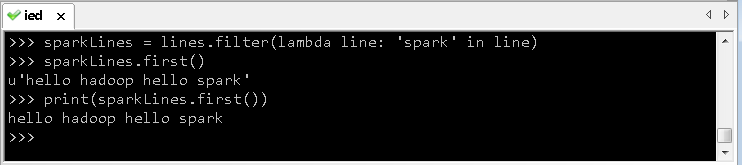
例2、调用转化操作filter()
>>> sparkLines = lines.filter(lambda line: 'spark' in line)
例3、调用first() 行动操作
>>> sparkLines.first()
‘hello hadoop hello spark’
- 转化操作和行动操作的区别在于Spark 计算RDD 的方式不同。虽然你可以在任何时候定义新的RDD,但Spark 只会
惰性计算这些RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。这种策略刚开始看起来可能会显得有些奇怪,不过在大数据领域是很有道理的。比如,看看例2和例3,我们以一个文本文件定义了数据,然后把其中包含spark的行筛选出来。如果Spark 在我们运行lines = sc.textFile(…) 时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反, 一旦Spark 了解了完整的转化操作链之后,它就可以只计算求结果时真正需要的数据。事实上,在行动操作first() 中,Spark 只需要扫描文件直到找到第一个匹配的行为止,而不需要读取整个文件。
二、搭建Spark伪分布式环境
- Spark单机伪分布式是在一台机器上既有Master,又有Worker进程。搭建Spark单机伪分布式环境可在Hadoop伪分布式的基础上进行搭建。
(一)搭建伪分布式Hadoop
1、利用hw_win7实例上的SecureCRT登录ied实例
- 本机远程桌面连接hw_win7实例【对外IP地址:192.168.177.180,私有IP地址:192.168.102】
- 虚拟机
ied上已经安装了Spark单机版环境,并不需要Hadoop,但是Spark伪分布式环境就需要建立在Hadoop伪分布式环境基础之上。
2、配置免密登录
(1)生成密钥对
- 执行
ssh-keygen命令后,一直敲回车,生成节点的公钥和私钥,生成的文件id_rsa会自动放在/root/.ssh目录下,然后我们可以把公钥发往远程机器或本机。
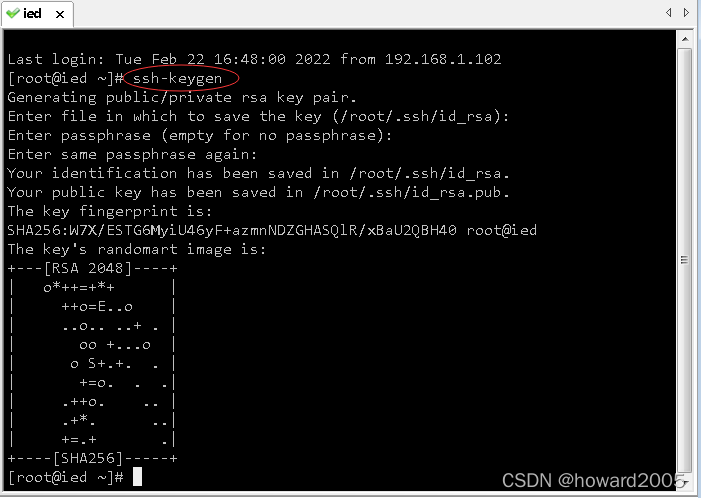
(2)将生成的公钥发送到本机(虚拟机ied)
- 执行命令:
ssh-copy-id root@ied
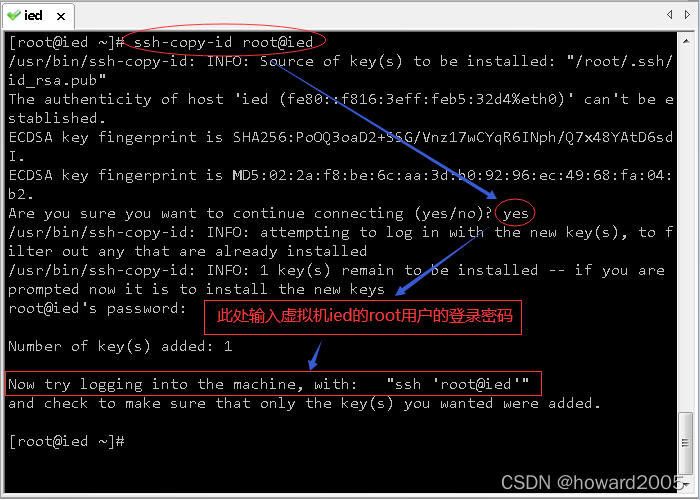
(3)验证虚拟机是否能免密登录本机
- 执行命令:
ssh ied,再执行命令:exit
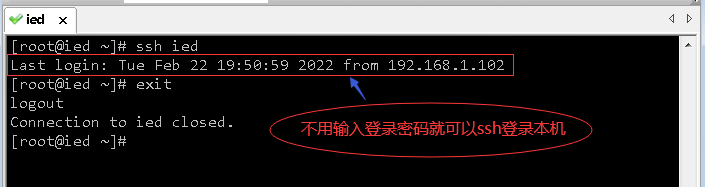
3、下载与Spark版本匹配的Hadoop安装包
- 下载链接:https://pan.baidu.com/s/1w9E9MHAah4OAM4UnR-w8vA 提取码:d3hs

4、将Hadoop安装包上传到虚拟机ied的/opt目录
- 进入/opt目录,然后利用rz命令上传文件
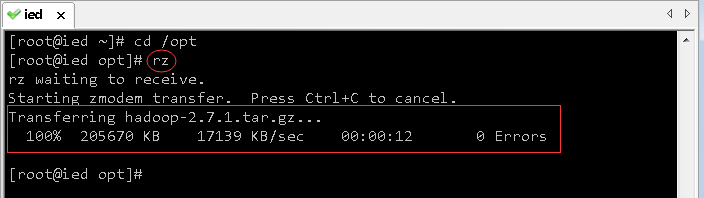
5、将Hadoop安装包解压到指定目录
- 执行命令:
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local

6、查看Hadoop的安装目录
(1)进入Hadoop安装目录查看
- 执行命令:
cd /usr/local/hadoop-2.7.1与ll
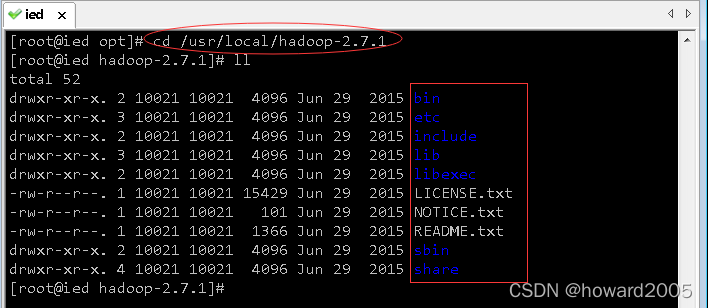
bin目录:命令脚本etc/hadoop目录:存放hadoop的配置文件lib目录:hadoop运行的依赖jar包sbin目录:存放启动和关闭hadoop等命令libexec目录:存放的也是hadoop命令,但一般不常用- 最常用的就是bin和etc目录
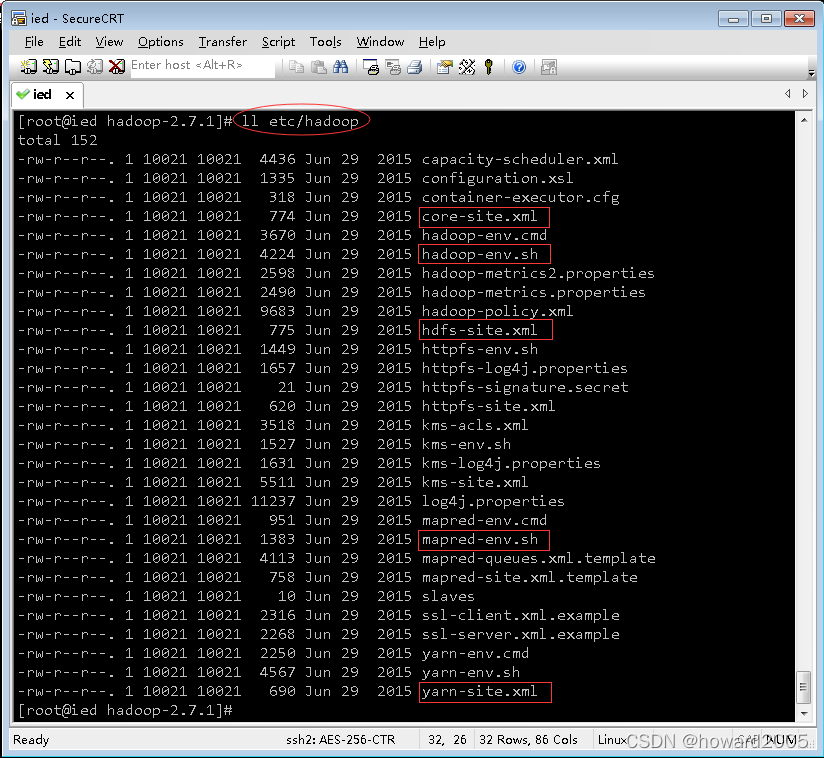
(2)查看etc/hadoop子目录
- 勾出了Hadoop比较重要的配置文件
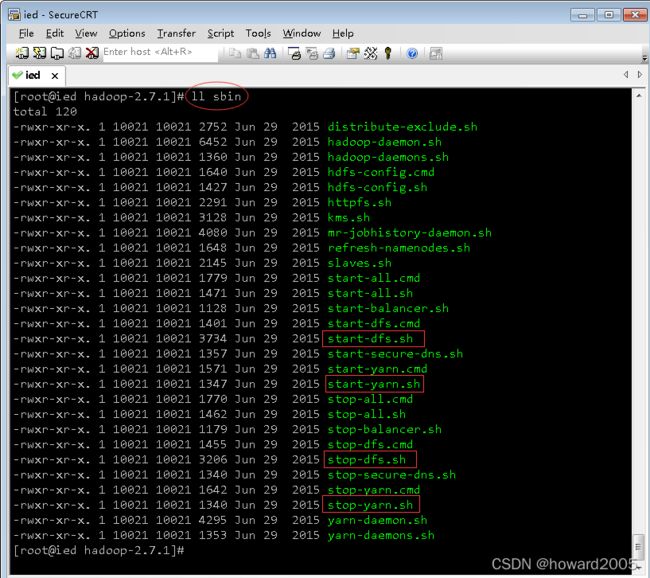
(3)查看sbin子目录
- 勾出了启动与停止dfs和yarn服务的脚本文件
7、配置Hadoop实现伪分布式
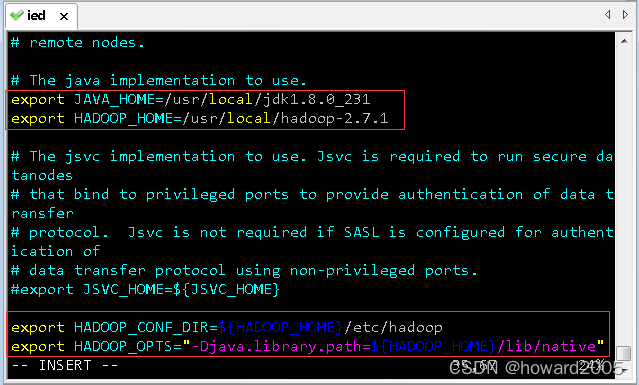
(1)修改环境配置文件 - hadoop-env.sh
- 进入hadoop配置目录,执行命令:
vim hadoop-env.sh
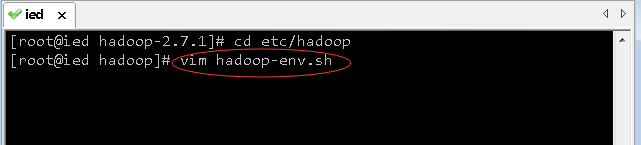
- 需要添加或修改以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_231
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
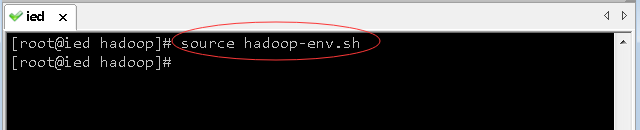
- 存盘退出,然后执行
source hadoop-env.sh,让配置立即生效
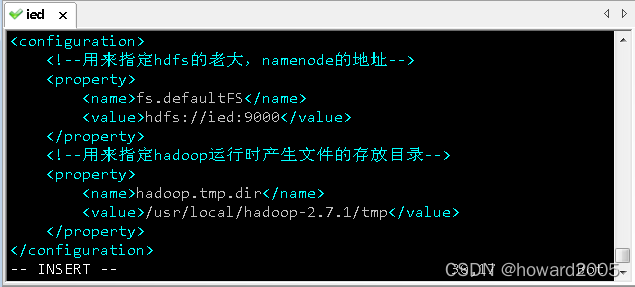
(2)修改核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml

<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://ied:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop-2.7.1/tmpvalue>
property>
configuration>
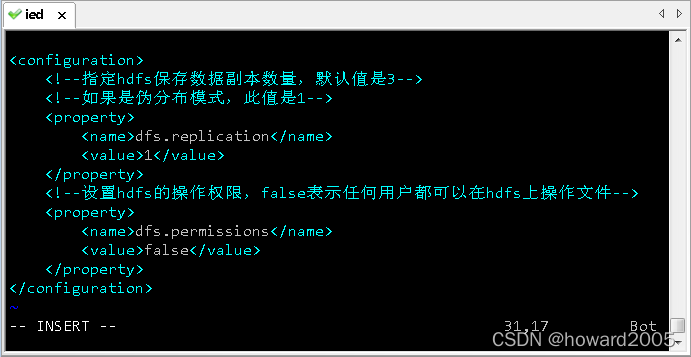
(3)修改分布式文件系统配置文件 - hdfs-site .xml
- 执行命令:
vim hdfs-site.xml

<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
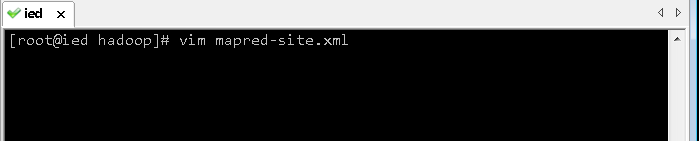
(4)修改MapReduce配置文件 - mapred-site.xml
- 执行命令:
cp mapred-site.xml.template mapred-site.xml,基于模板文件生成配置文件

- 执行命令:
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>

- 说明:yarn是资源协调工具,将MapReduce交给它来管理,效率更高。
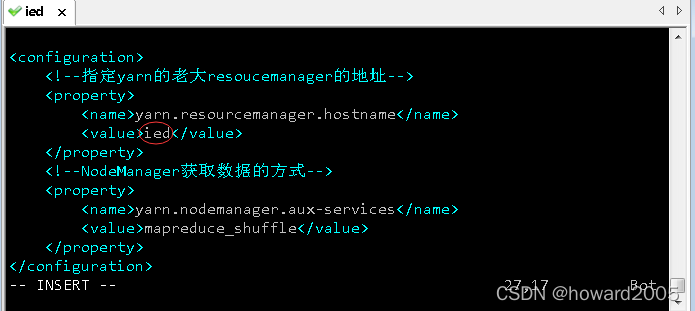
(5)修改yarn配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml

<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>iedvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
(6)配置hadoop的环境变量
- 执行命令:
vim /etc/profile

JAVA_HOME=/usr/local/jdk1.8.0_231
HADOOP_HOME=/usr/local/hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATH
export JAVA_HOME HADOOP_HOME SPARK_HOME PATH CLASSPATH

- 在配置Spark单机版时,就配置了SPARK_HOME
- 存盘退出,执行命令
source /etc/profile,让配置生效

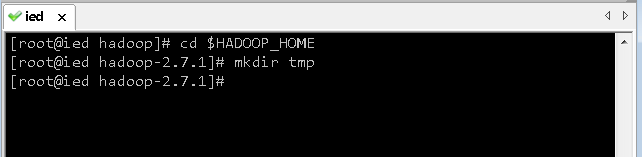
8、创建存放生成文件的临时目录
- 返回到hadoop安装目录,创建tmp子目录
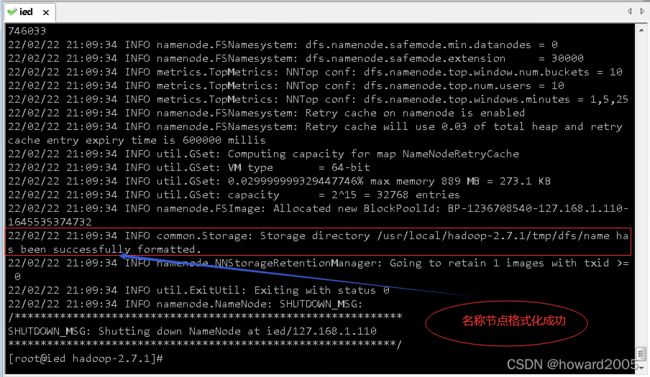
9、格式化名称节点
- 执行命令:
hdfs namenode -format,格式化名称节点,形成可用的分布式文件系统HDFS

- 名称节点格式化成功信息
- 看到
22/02/22 21:09:34 INFO common.Storage: Storage directory /usr/local/hadoop-2.7.1/tmp/dfs/name has been successfully formatted.,表明名称节点格式化节点成功
10、启动hadoop服务
- 执行命令:
start-dfs.sh,启动dfs服务 - 分布式存储

- 执行命令:
start-yarn.sh,启动yarn服务 - 分布式计算

- 执行命令:
jps,查看hadoop进程
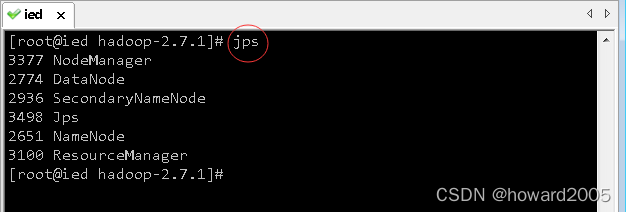
11、停止hadoop服务
- 执行命令:
stop-dfs.sh,停止dfs服务
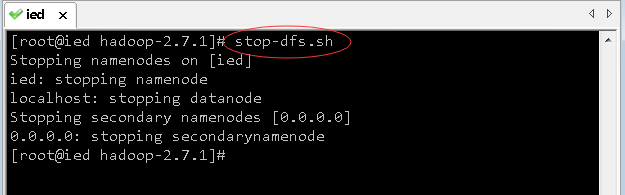
- 执行命令:
stop-yarn.sh,停止yarn服务

- 执行命令:
jps,查看进程

(二)搭建伪分布式Spark
- 我们已经在单机版Spark基础上搭建了伪分布式Hadoop,下面通过Spark环境配置文件实现伪分布式Spark
1、进入spark配置目录
- 执行命令:
cd $SPARK_HOME/conf

2、生成环境配置文件 - spark-env.sh
- 基于环境配置文件模板生成环境配置文件
- 执行命令:
cp spark-env.sh.template spark-env.sh
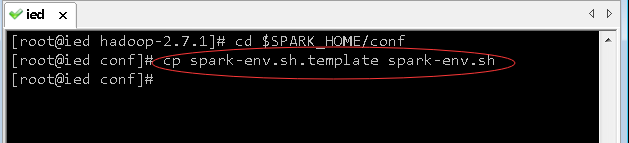
3、修改环境配置文件 - spark-env.sh
- 执行命令:
vim spark-env.sh


4、配置spark环境变量
-
由于启动spark服务的命令是在spark安装目录下的sbin里,因此要添加到环境变量配置文件里
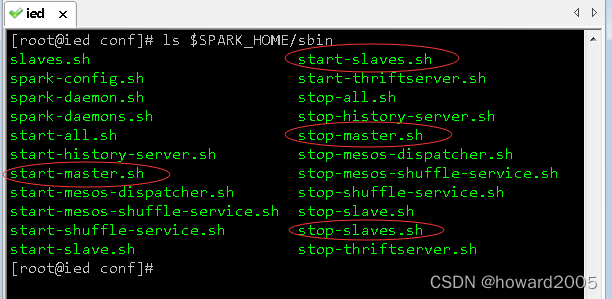
-
执行命令:
vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_231
HADOOP_HOME=/usr/local/hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export JAVA_HOME HADOOP_HOME SPARK_HOME PATH CLASSPATH

- 存盘退出,执行命令:
source /etc/profile,让环境变量配置生效
(三)启动并使用伪分布式Spark
1、启动hadoop服务
- 执行命令:
start-dfs.sh - 执行命令:
start-yarn.sh
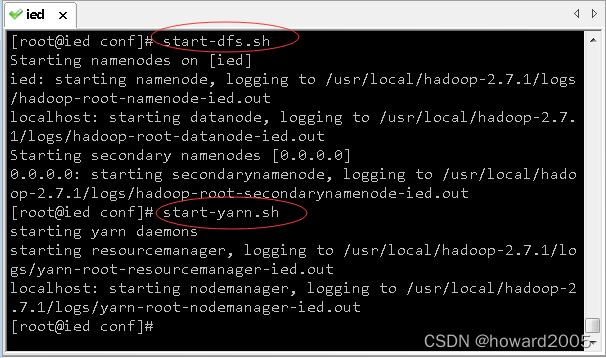
2、启动spark服务
- 执行命令:
start-master.sh,启动spark老大 - Master

- 执行命令:
start-slaves.sh,启动spark小弟 - Worker
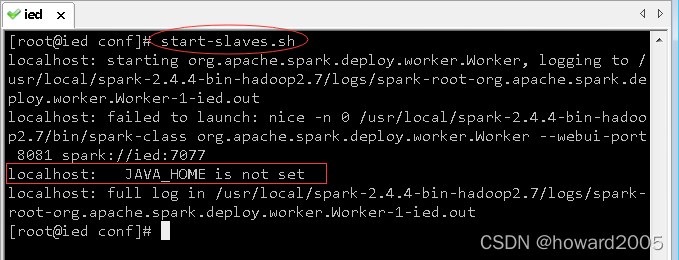
- 查看进程

- 执行命令:
vim $SPARK_HOME/sbin/spark-config.sh,添加JAVA_HOME环境变量

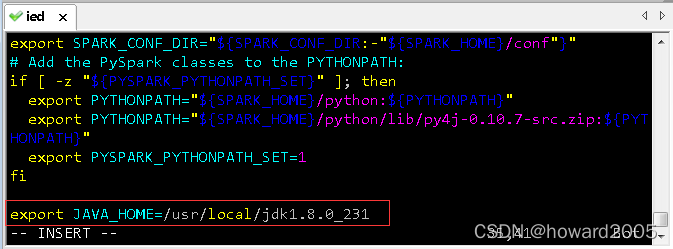
- 存盘退出,执行命令:
source $SPARK_HOME/sbin/spark-config.sh,让配置生效

- 此时,再执行命令:
start-slaves.sh,启动spark小弟 - Worker

3、进入交互式Spark Shell
(1)scala版spark shell
- 执行命令:
spark-shell --master=local
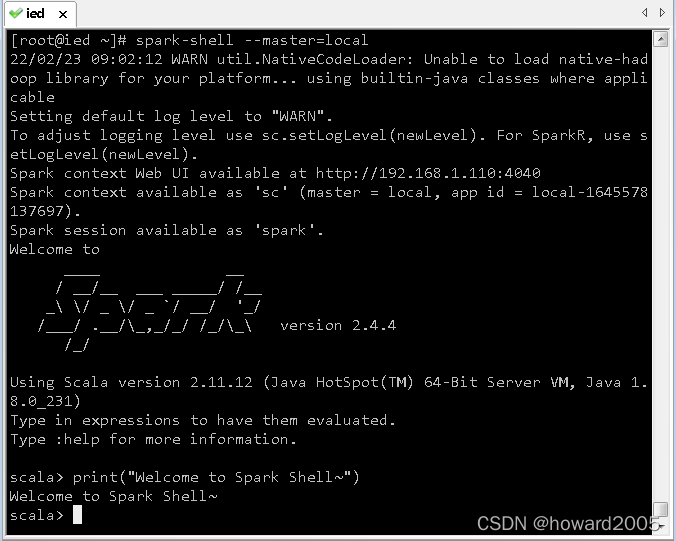
- 在
scala>提示符后面执行:quit,退出scala版spark shell

(2)python版spark shell
- 执行命令:
pyspark --master=local
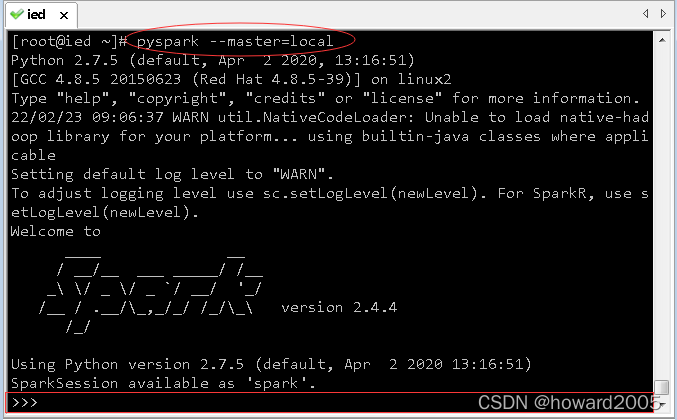
- 在
>>>提示符后执行exit()函数退出python版spark shell
4、Web界面访问spark
-
启动scala版spark shell
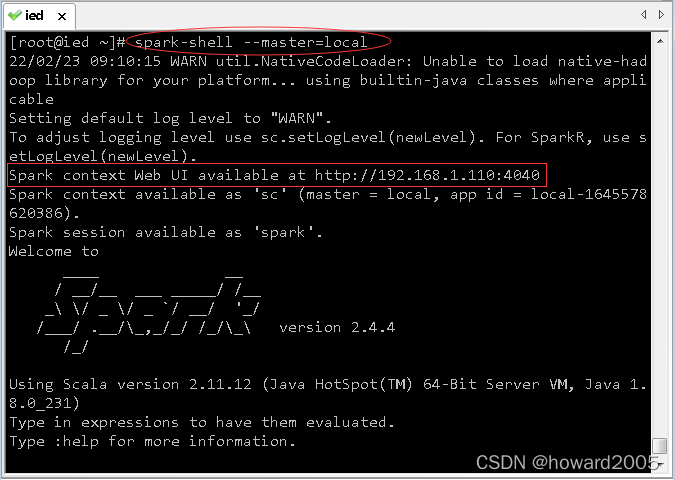
-
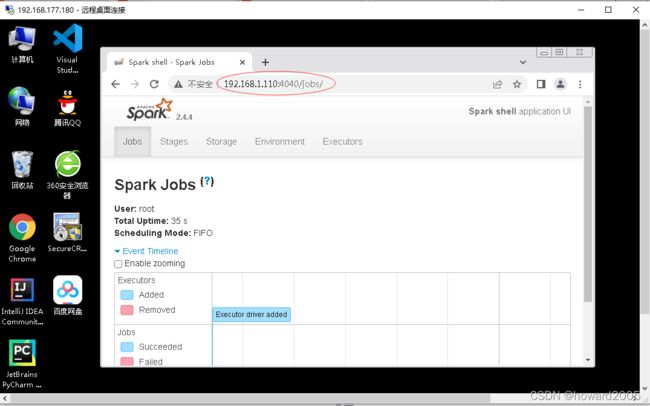
访问
http://192.168.1.110:4040- 注意端口号是4040

-
关闭与禁用虚拟机ied的防火墙
-
执行命令:
systemctl stop firewalld.service -
执行命令:
systemctl disable firewalld.service
-
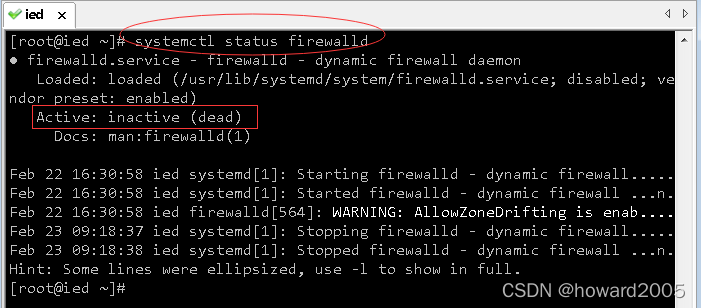
执行命令:
systemctl status firewalld,查看防火墙状态
-
关闭hw_win7防火墙
-
访问
http://192.168.1.110:4040
三、搭建Spark完全分布式环境
(一)Spark集群拓扑

(二) 搭建ZooKeeper集群
1、私有云上创建三台虚拟机
- 创建配置过程,参看本博《 在私有云上创建与配置虚拟机》
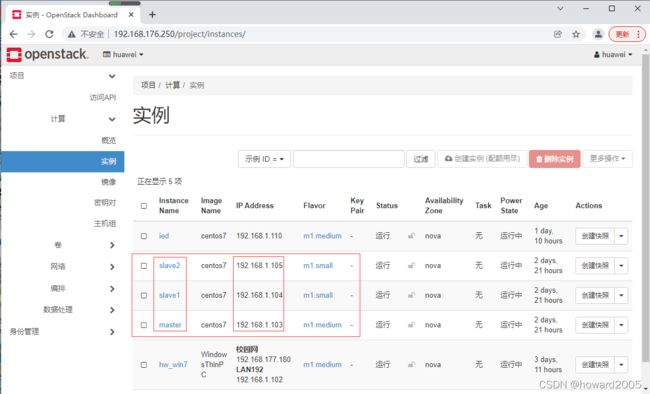
2、利用SecureCRT登录三台虚拟机
- 打开连接对话框

(1)登录master虚拟机
- 单击连接对话框里的master,登录master虚拟机
- 参看本博《在CentOS7上安装vim编辑器》,在master虚拟机上安装
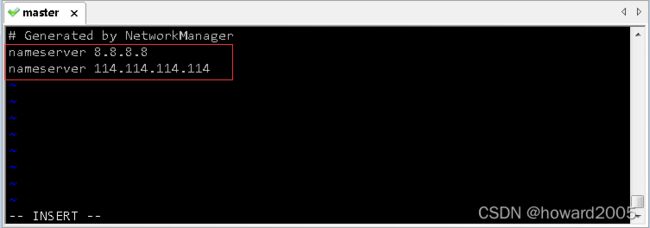
vim编辑器 - 执行命令:
vi /etc/resolv.conf,修改/etc/resolv.conf文件

- 添加两个域名服务器
- 存盘退出
- 执行命令:
yum -y install vim

- 解决在《在私有云上创建与配置虚拟机》遗留的问题
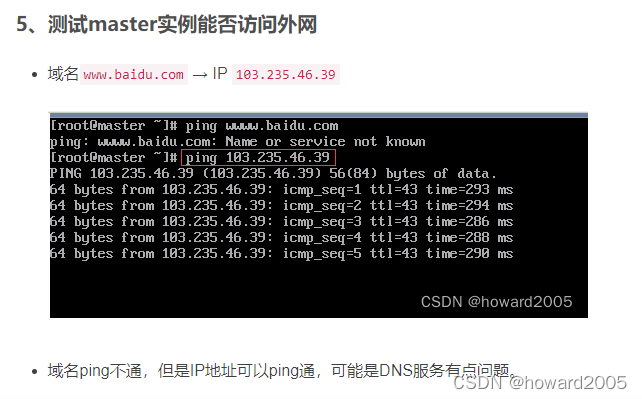
- 现在我们通过
/etc/resolv.conf文件添加了域名解析服务器,因此可以ping通域名了

(2)登录slave1虚拟机
- 单击连接对话框里的slave1,登录slave1虚拟机
- 修改选项
- 单击【OK】按钮
- 执行命令:
vi /etc/resolv.conf,添加域名解析服务器
- 存盘退出后,执行命令:
yum - install vim,安装vim编辑器
(3)登录slave2虚拟机
- 单击连接对话框里的slave2,登录slave2虚拟机
- 仿照slave1虚拟机上的做法,修改选项,效果如下所示
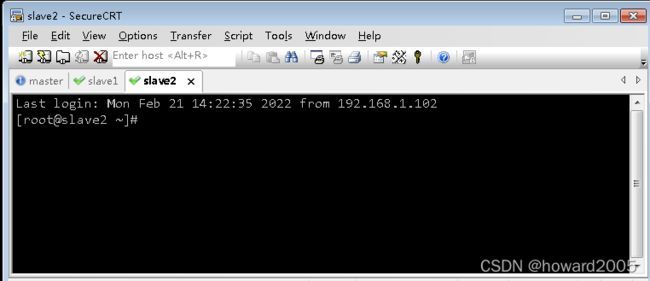
- 配置域名解析服务器之后,安装vim编辑器

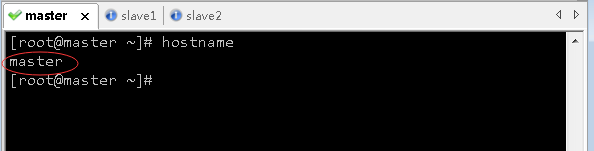
3、查看三台虚拟机主机名
- 查看master虚拟机主机名
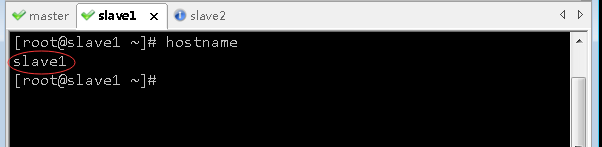
- 查看slave1虚拟机主机名
- 查看slave2虚拟机主机名

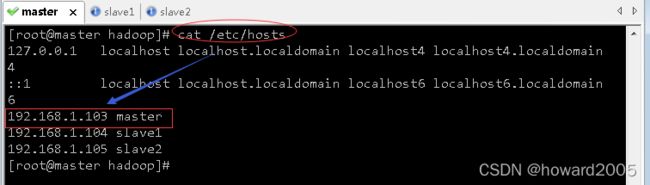
4、配置三台虚拟机IP-主机名映射
192.168.1.103 master
192.168.1.104 slave1
192.168.1.105 slave2
(1)配置master虚拟机IP-主机名映射
- 执行命令:
vim /etc/hosts
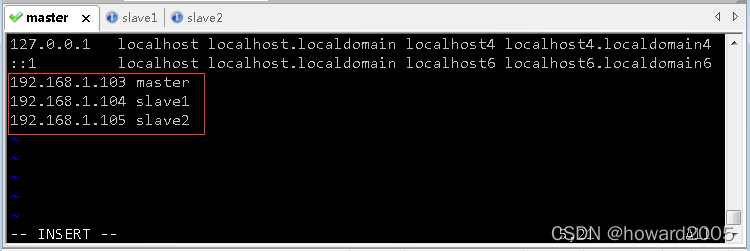
- 存盘退出
(2)配置slave1虚拟机IP-主机名映射
- 执行命令:
vim /etc/hosts

- 存盘退出
(3)配置slave2虚拟机IP-主机名映射
- 执行命令:
vim /etc/hosts
- 存盘退出
5、关闭与禁用防火墙
- 关闭与禁用防火墙
systemctl stop firewalld.service # 关闭防火墙
systemctl disable firewalld.service # 禁用防火墙
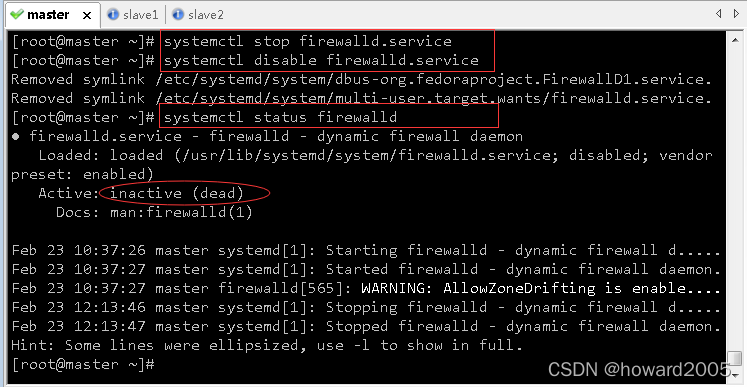
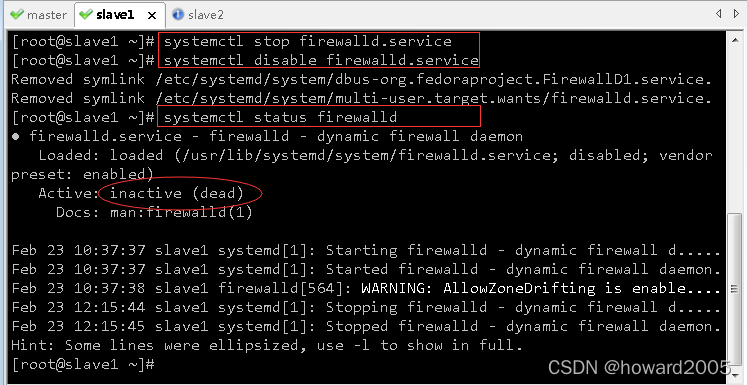
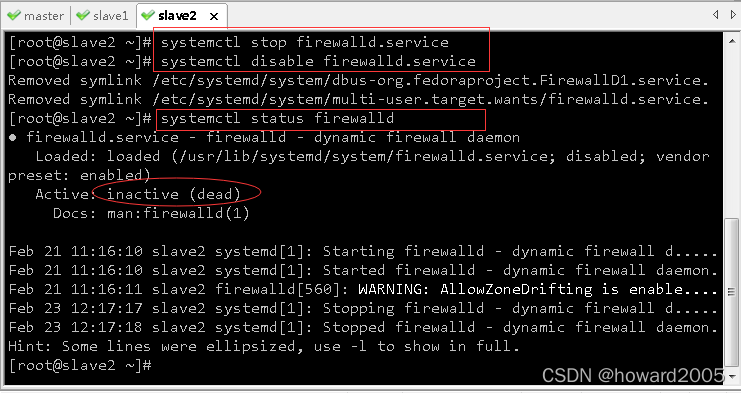
- 查看防火墙状态
systemctl status firewalld.service
(1)master虚拟机
(2)slave1虚拟机
(3)slave2虚拟机
6、关闭SeLinux安全机制
/etc/sysconfig/selinux文件里SELINUX=enforcing,将enforcing改成disable,就可以关闭SeLinux安全机制
(1)master虚拟机
- 执行命令:
vim /etc/sysconfig/selinux
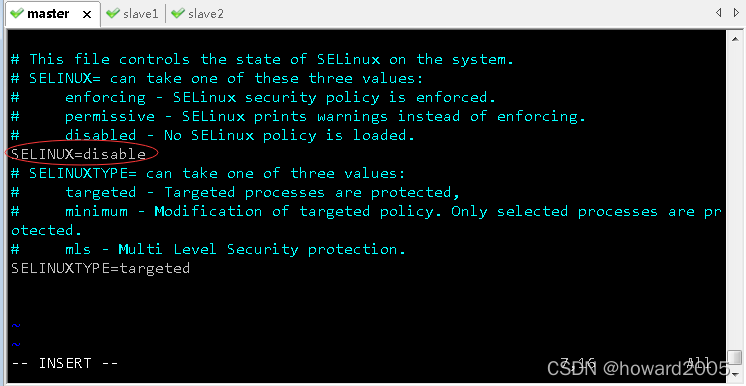
- 存盘退出
(2)slave1虚拟机
- 执行命令:
vim /etc/sysconfig/selinux
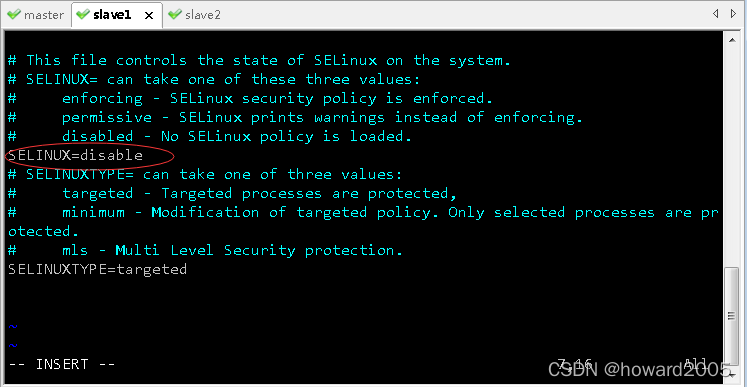
- 存盘退出
(3)slave2虚拟机
- 执行命令:
vim /etc/sysconfig/selinux

- 存盘退出
7、设置三台虚拟机相互免密登录
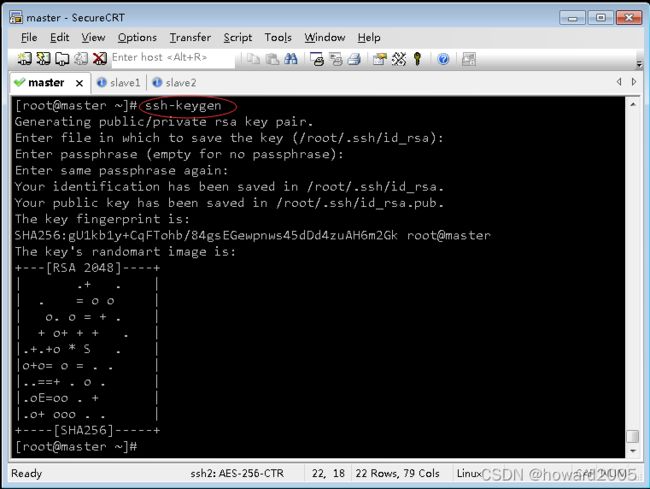
(1)master虚拟机免密登录master、slave1与slave2
- 执行命令:
ssh-keygen,生成密钥对
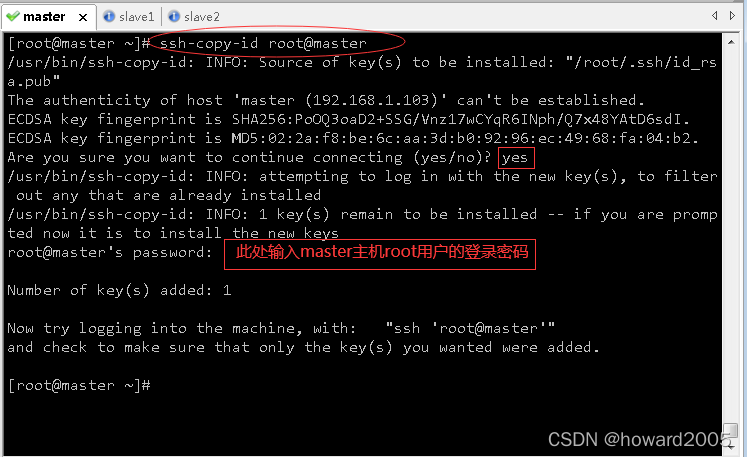
- 执行命令:
ssh-copy-id root@master,将公钥拷贝到master
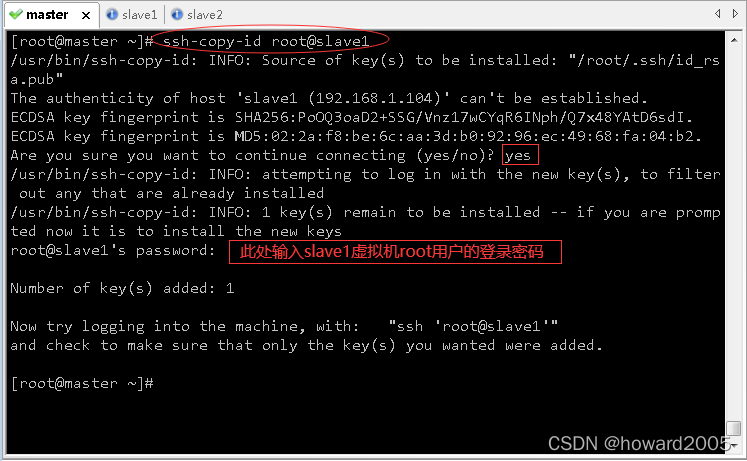
- 执行命令:
ssh-copy-id root@slave1,将公钥拷贝到slave1
- 执行命令:
ssh-copy-id root@slave2,将公钥拷贝到slave2
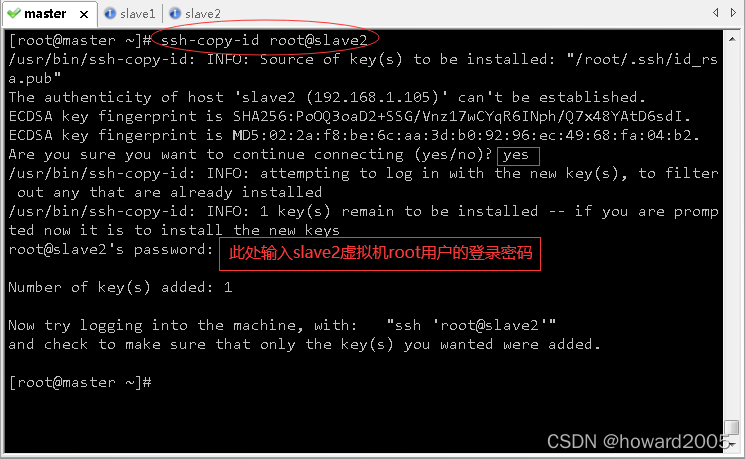
- 验证master是否可以免密登录master、slave1与slave2
(2)slave1虚拟机免密登录master、slave1与slave2
- 执行命令:
ssh-keygen,生成密钥对

- 执行命令:
ssh-copy-id root@master,将公钥拷贝到master
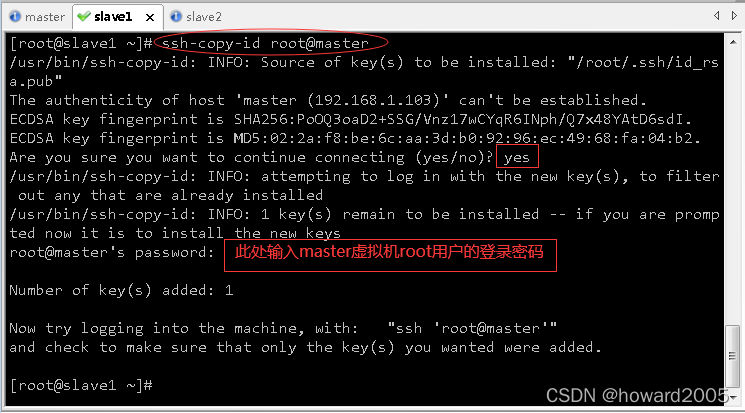
- 执行命令:
ssh-copy-id root@slave1,将公钥拷贝到slave1
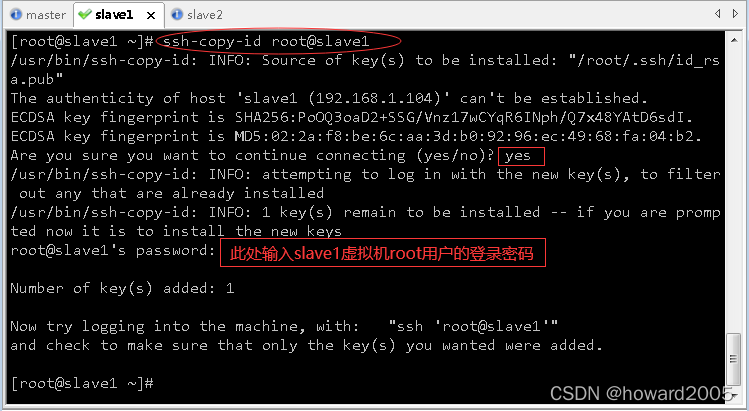
- 执行命令:
ssh-copy-id root@slave2,将公钥拷贝到slave2
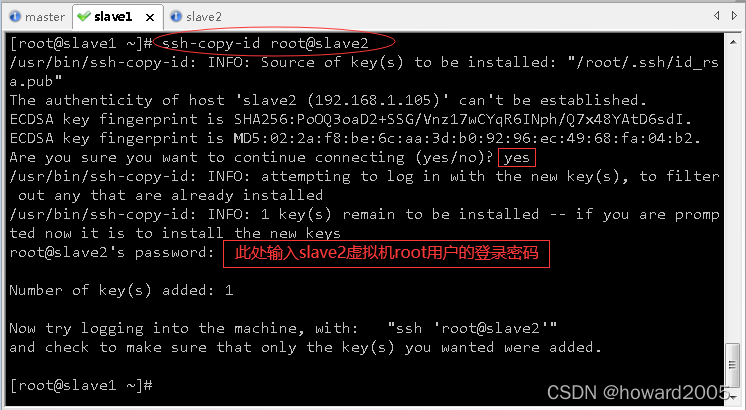
- 验证slave1是否可以免密登录master、slave1与slave2
(3)slave2虚拟机免密登录master、slave1与slave2
- 执行命令:
ssh-keygen,生成密钥对

- 执行命令:
ssh-copy-id root@master,将公钥拷贝到master

- 执行命令:
ssh-copy-id root@slave1,将公钥拷贝到slave1
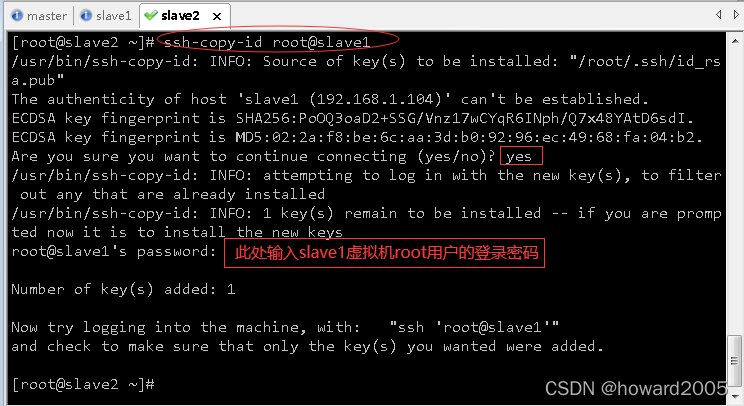
- 执行命令:
ssh-copy-id root@slave2,将公钥拷贝到slave2
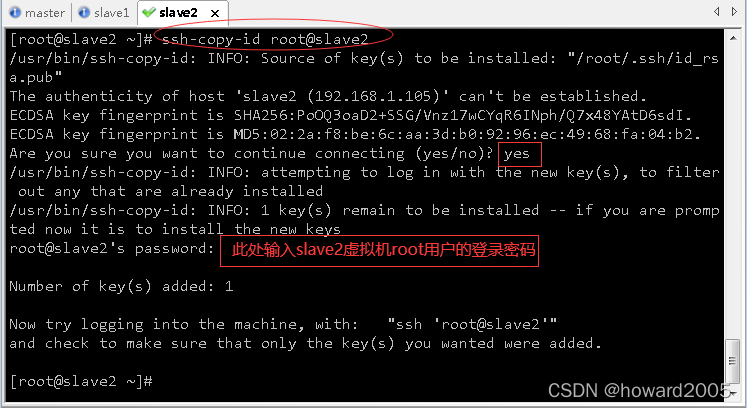
- 验证slave2是否可以免密登录master、slave1与slave2
8、在三台虚拟机上安装lrzsr
(1)在master虚拟机上安装lrzsz
- 执行命令:
yum -y install lrzsz
(2)在slave1虚拟机上安装lrzsz
- 执行命令:
yum -y install lrzsz

(3)在slave2虚拟机上安装lrzsz
- 执行命令:
yum -y install lrzsz
9、在三台虚拟机上安装配置JDK
(1)在master虚拟机上安装配置JDK
-
上传Java安装包到/opt目录

-
执行
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local,将Java安装包解压到/usr/local

-
执行命令:
vim /etc/profile,配置环境变量
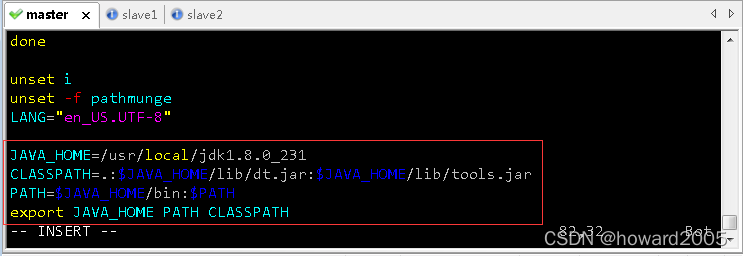
JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
- 存盘退出,执行命令:
source /etc/profile,让配置生效

- 查看JDK版本
(2)在master虚拟机上安装的JDK免密拷贝到slave1虚拟机
- 执行命令:
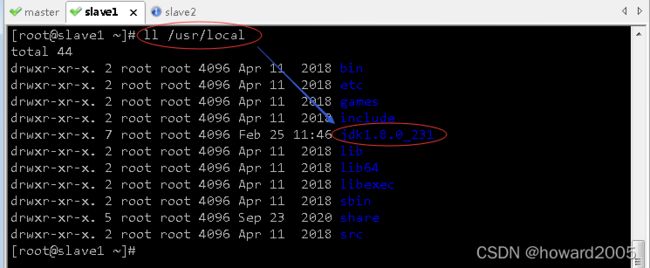
scp -r /usr/local/jdk1.8.0_231 root@slave1:/usr/local

- 在slave1虚拟机上查看Java是否拷贝成功
- 在master虚拟机上,执行命令:
scp -r /etc/profile root@slave1:/etc/profile

- 在slave1虚拟机上,查看从master虚拟机拷贝过来的配置文件profile

- 存盘退出,执行命令:
source /etc/profile,让配置生效

(3)在master虚拟机上安装的JDK免密拷贝到slave2虚拟机
-
执行命令:
scp -r /usr/local/jdk1.8.0_231 root@slave2:/usr/local

-
在slave2虚拟机上查看Java是否拷贝成功
-
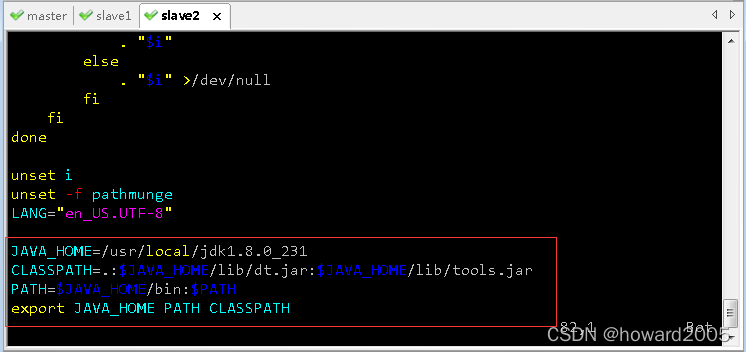
在master虚拟机上,执行命令:
scp -r /etc/profile root@slave2:/etc/profile

-
在slave2虚拟机上,查看从master虚拟机拷贝过来的配置文件profile
-
存盘退出,执行命令:
source /etc/profile,让配置生效

10、安装配置ZooKeeper(可选)
- 如果要搭建高可用Hadoop集群,那么就需要ZooKeeper集群
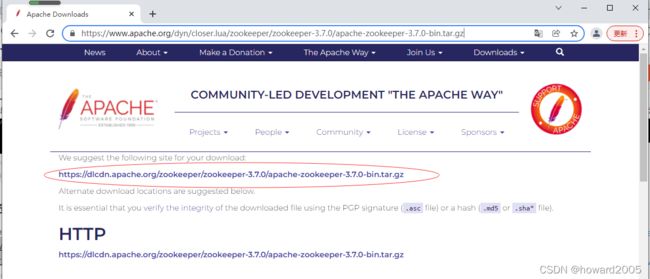
- ZooKeeper下载网址:
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
- 下载到hw_win7虚拟机上
(1)在虚拟机master上安装配置ZooKeeper
- 将zookeeper安装包上传到/opt目录
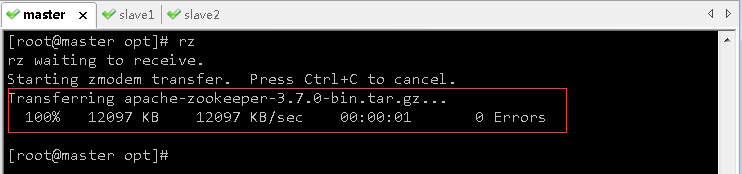
- 执行命令
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local,将zookeeper安装解压到指定目录

- 将zookeeper解压目录更名为
zookeeper-3.7.0,执行命令:mv /usr/local/apache-zookeeper-3.7.0-bin /usr/local/zookeeper-3.7.0

- 进入zookeeper安装目录,创建
ZkData子目录

- 进入zookeeper配置目录conf,复制zoo_sample.cfg到zoo.cfg

- 执行命令:
vim zoo.cfg,修改zoo.cfg文件,配置数据目录和服务器选举id
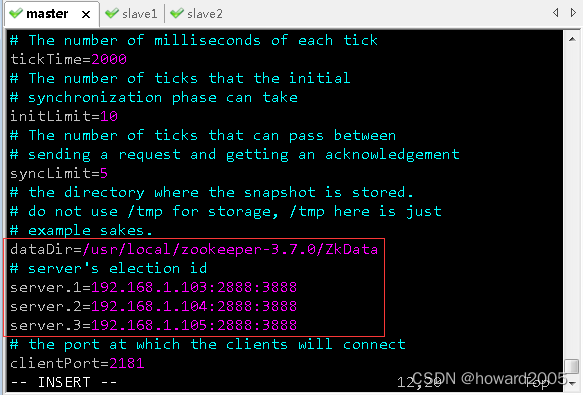
dataDir=/usr/local/zookeeper-3.7.0/ZkData
# server's election id
server.1=192.168.1.103:2888:3888
server.2=192.168.1.104:2888:3888
server.3=192.168.1.105:2888:3888
说明:server后面的数字是选举id,在选举过程中会用到
注意:数字一定要能比较出大小。
2888:原子广播端口号,可以自定义
3888:选举端口号,可以自定义
- 存盘退出,进入数据目录
ZkData,创建myid文件,内容为1

- 配置环境变量,执行命令
vim /etc/profile
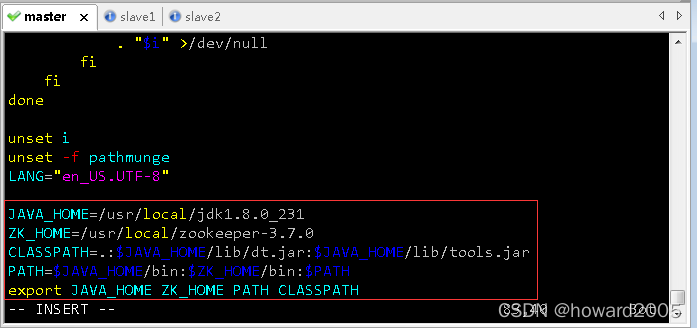
JAVA_HOME=/usr/local/jdk1.8.0_231
ZK_HOME=/usr/local/zookeeper-3.7.0
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$PATH
export JAVA_HOME ZK_HOME PATH CLASSPATH
- 存盘退出后,执行命令
source /root/.bash_profile,让配置生效

- 关闭防火墙
systemctl stop firewalld.service # 临时关闭防火墙
systemctl disable firewalld.service # 禁止开机启动防火墙
systemctl status firewalld # 查看防火墙状态
(2)在虚拟机slave1上安装配置ZooKeeper
- 将虚拟机master上的zookeeper安装目录复制到虚拟机slave1相同目录,执行命令:
scp -r /usr/local/zookeeper-3.7.0 root@slave1:/usr/local

- 将虚拟机master上的/etc/profile复制到虚拟机slave1相同位置,执行命令:
scp /etc/profile root@slave1:/etc/profile

- 切换到虚拟机slave1,执行命令
source /etc/profile,让配置生效
- 在虚拟机slave1上,进入
zookeeper-3.7.0/ZkData目录,修改myid的内容为2

(3)在虚拟机slave2上安装配置ZooKeeper
-
将虚拟机master上的zookeeper安装目录复制到虚拟机slave2相同目录,执行命令:
scp -r /usr/local/zookeeper-3.7.0 root@slave2:/usr/local

-
将虚拟机master上的/etc/profile复制到虚拟机slave2相同位置,执行命令:
scp /etc/profile root@slave2:/etc/profile

-
切换到虚拟机slave2,执行命令
source /etc/profile,让配置生效

-
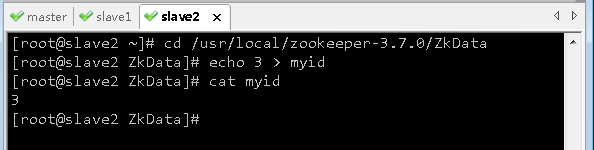
在虚拟机slave2上,进入
zookeeper-3.7.0/ZkData目录,修改myid的内容为3
11、启动与关闭集群ZooKeeper服务
(1)在虚拟机master上启动ZK服务
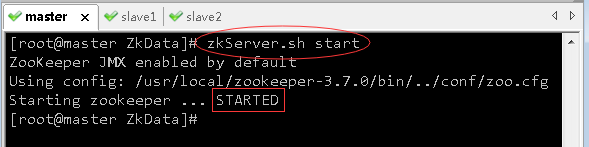
- 在master虚拟机上,执行命令:
zkServer.sh start
(2)在虚拟机slave1上启动ZK服务
- 在slave1虚拟机上,执行命令:
zkServer.sh start
(3)在虚拟机slave2上启动ZK服务
- 在slave2虚拟机上,执行命令:
zkServer.sh start
(4) 在三个虚拟机上查询ZK服务状态
- 在master虚拟机上,执行命令:
zkServer.sh status

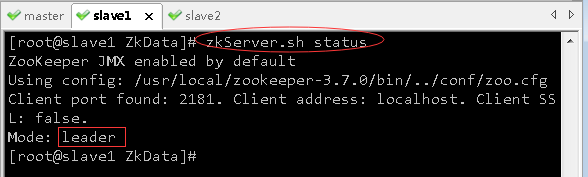
- 在slave1虚拟机上,执行命令:
zkServer.sh status
- 在slave2虚拟机上,执行命令:
zkServer.sh status

- 可以看到:虚拟机slave1是老大(leader),虚拟机master和虚拟机slave2是小弟(follower)。
(5)测试集群三个节点是否同步
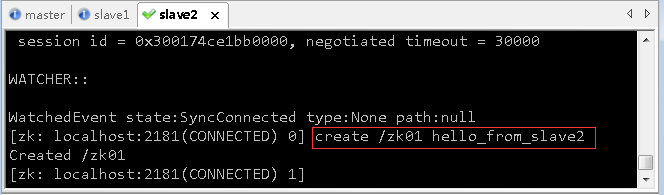
- 在虚拟机slave2上,执行命令:
zkCli.sh,启动zk客户端,创建一个节点/zk01
- 现在,去看集群另外两个节点master和slave1是否已经同步?
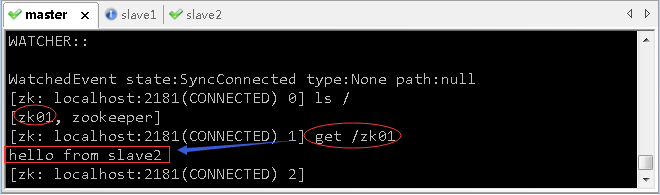
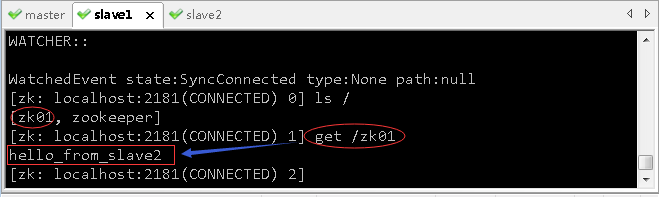
- 大家可以看到,集群三个节点的数据是同步的
- 在三个虚拟机上,执行
quit命令,退出zk客户端
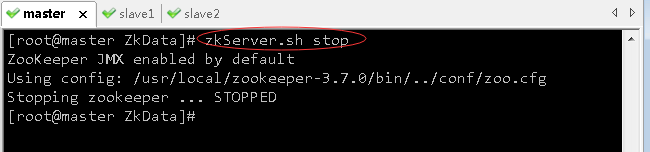
(6)关闭三台虚拟机上的ZK服务
- 关闭master虚拟机上的ZK服务
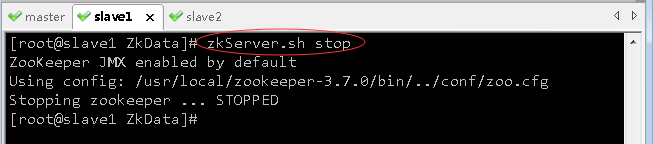
- 关闭slave1虚拟机上的ZK服务
- 关闭slave2虚拟机上的ZK服务

(三)配置完全分布式Hadoop
1、在master虚拟机上安装配置hadoop
(1)上传hadoop安装包到/opt目录
- 利用rz命令上传hadoop-2.7.1.tar.gz
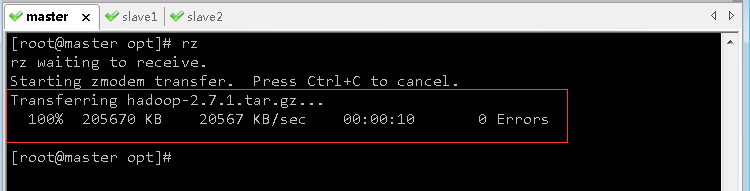
(2)将hadoop安装包解压到指定位置
- 执行命令:
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local
(3)配置hadoop环境变量
- 执行命令:
vim /etc/profile
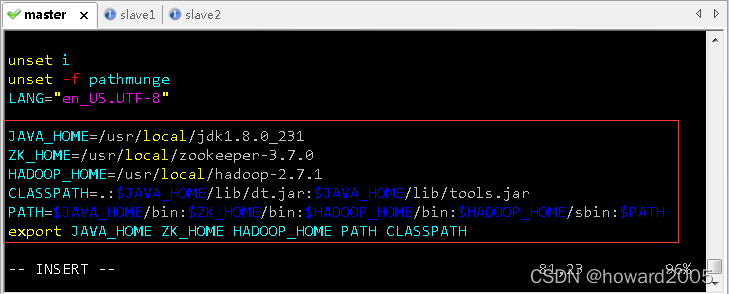
JAVA_HOME=/usr/local/jdk1.8.0_231
ZK_HOME=/usr/local/zookeeper-3.7.0
HADOOP_HOME=/usr/local//hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME ZK_HOME HADOOP_HOME PATH CLASSPATH
- 存盘退出,执行命令:
source /etc/profile,让配置生效

修改至此 - 2022-2-25
(4)编辑环境配置文件 - hadoop-env.sh
- 执行命令:
cd $HADOOP_HOME/etc/hadoop,进入hadoop配置目录

- 执行命令:
vim hadoop-env.sh
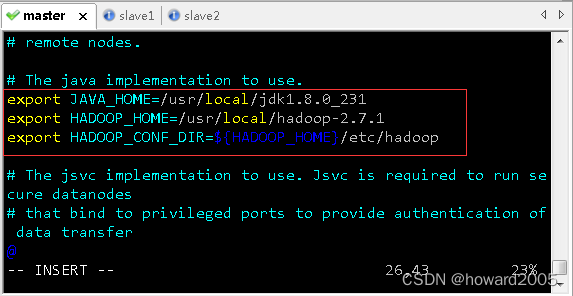
export JAVA_HOME=/usr/local/jdk1.8.0_231
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
- 存盘退出后,执行命令
source hadoop-env.sh,让配置生效

- 查看三个配置的三个环境变量
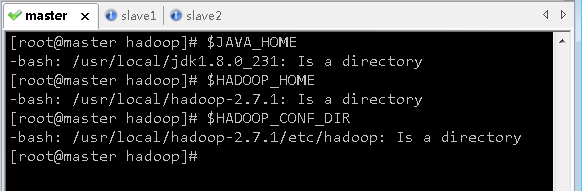
(5)编辑核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml

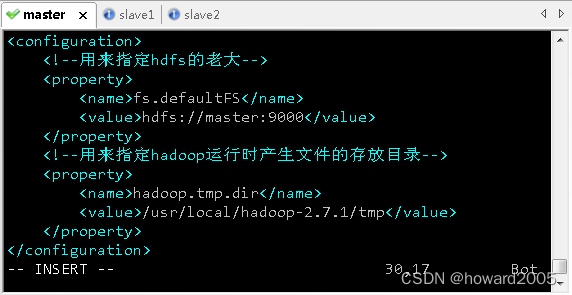
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop-2.7.1/tmpvalue>
property>
configuration>
- 存盘退出
- 由于配置了IP地址主机名映射,因此可用
hdfs://master:9000,否则必须用IP地址hdfs://192.168.1.103:9000
(6)编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml
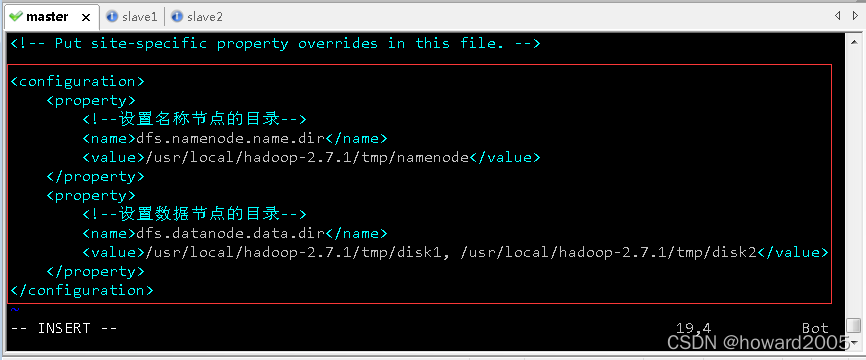
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/hadoop-2.7.1/tmp/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/hadoop-2.7.1/tmp/disk1, /usr/local/hadoo
p-2.7.1/tmp/disk2value>
property>
configuration>
- 存盘退出
(7)编辑MapReduce配置文件 - mapred-site.xml
- 基于模板生成配置文件,执行命令:
mv mapred-site.xml.template mapred-site.xml

- 执行命令:
vim mapred-site.xml
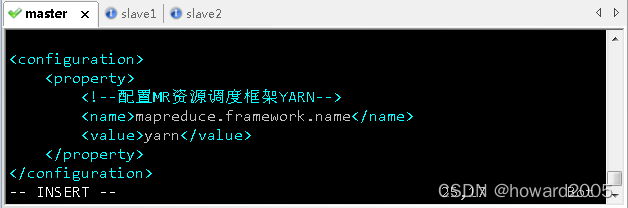
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- 存盘退出

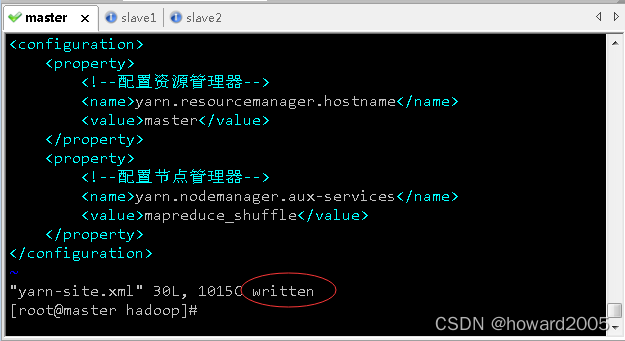
(8)编辑yarn配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml

<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
- 存盘退出
- 说明:在hadoop-3.0.0的配置中,
yarn.nodemanager.aux-services项的默认值是“mapreduce.shuffle”,但如果在hadoop-2.7 中继续使用这个值,NodeManager 会启动失败。
(9)编辑slaves文件
- 执行命令:
vim slaves - 注意:是
slaves文件,不是slave文件。
- 存盘退出
2、在slave1虚拟机上安装配置hadoop
(1)将master虚拟机上hadoop安装目录远程拷贝到slave1虚拟机
- 执行命令:
scp -r /usr/local/hadoop-2.7.1 root@slave1:/usr/local

(2)将master虚拟机上环境配置文件远程拷贝到slave1虚拟机
- 执行命令:
scp /etc/profile root@slave1:/etc/profile

(3)在slave1虚拟机上让环境配置生效
- 切换到slave1虚拟机,执行命令:
source /etc/profile
3、在slave2虚拟机上安装配置hadoop
(1)将master虚拟机上hadoop安装目录远程拷贝到slave2虚拟机
- 执行命令:
scp -r /usr/local/hadoop-2.7.1 root@slave2:/usr/local

(2)将master虚拟机上环境配置文件远程拷贝到slave2虚拟机
- 执行命令:
scp /etc/profile root@slave2:/etc/profile

(3)在slave2虚拟机上让环境配置生效
- 切换到slave2虚拟机,执行命令:
source /etc/profile

4、在master虚拟机上格式化名称节点
- 在master虚拟机上,执行命令:
hdfs namenode -format

- 看到
22/02/26 13:23:22 INFO common.Storage: Storage directory /usr/local/hadoop-2.7.1/tmp/namenode has been successfully formatted.,表明名称节点格式化成功。
5、启动与关闭集群Hadoop服务
(1)在master虚拟机上启动hadoop服务
-
执行命令:
start-dfs.sh,启动DFS服务

-
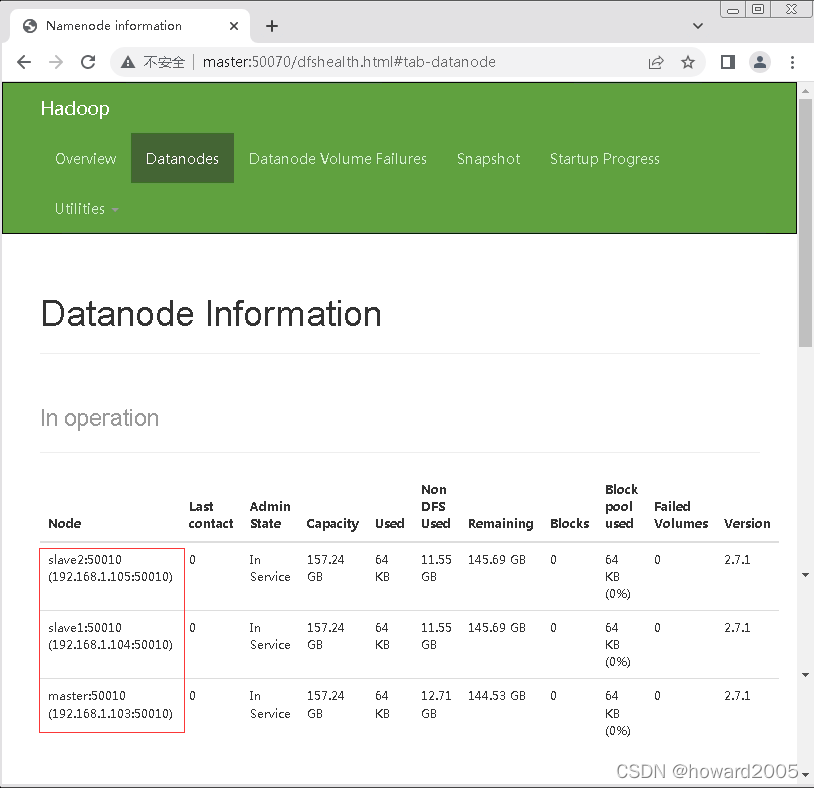
一个名称节点(namenode),在master虚拟机上;三个数据节点(datanode)在三个虚拟机上。
-
辅助名称节点(secondarynamenode)的地址是
0.0.0.0,这是默认的,当然可以修改 -
可以在hdfs-site.xml文件里配置辅助名称节点

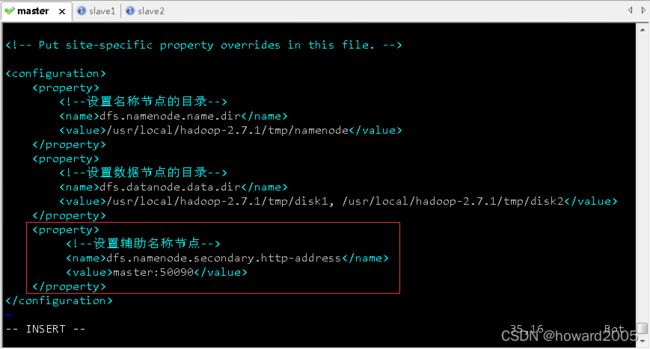
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:50090value>
property>
-
存盘退出
-
再次启动DFS服务
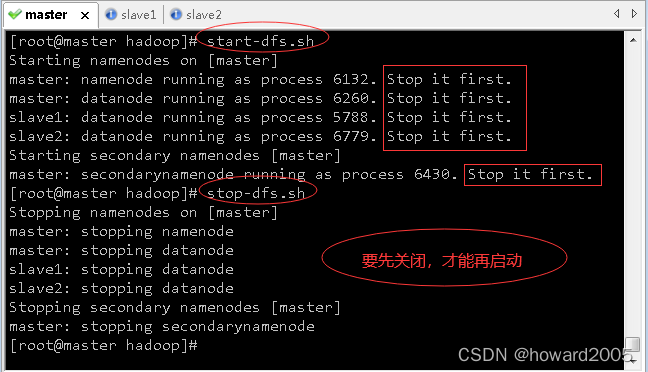
-
执行命令:
start-dfs.sh
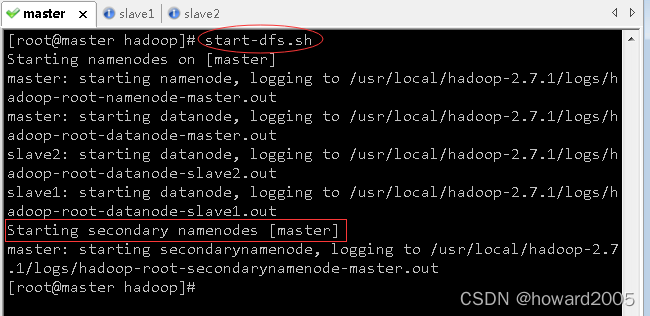
-
这样就是在master虚拟机(192.168.1.103)上启动辅助名称节点(secondarynamenode)
-
执行命令:
start-yarn.sh,启动YARN服务

-
启动了YARN守护进程;一个资源管理器(resourcemanager)在master虚拟机上,三个节点管理器(nodemanager)在三个虚拟机上
-
执行命令
jps查看master虚拟机的进程
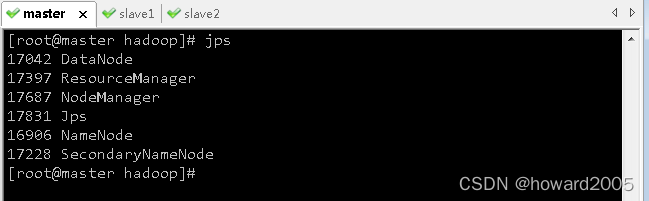
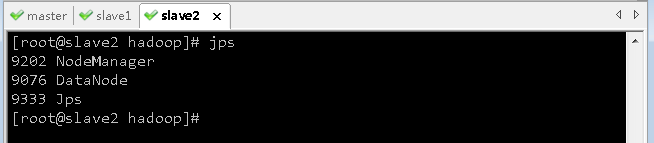
-
查看slave1和slave2上的进程,只有NodeManager和DataNode

(2)利用Web界面查看hadoop集群情况
- 在hw_win7虚拟机浏览器访问
http://master:50070
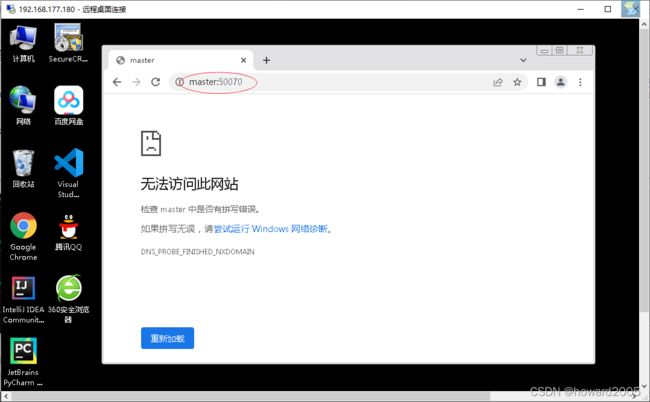
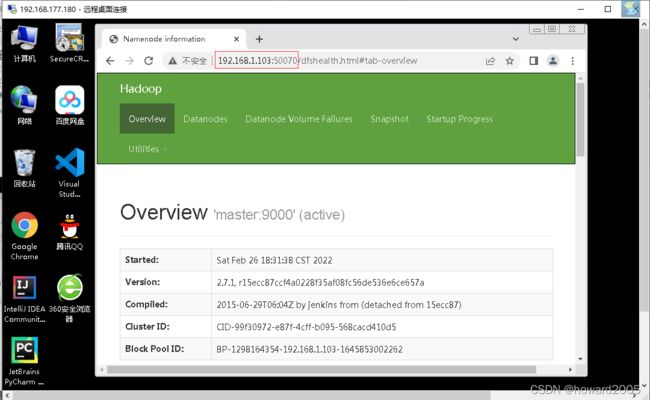
- 不能通过主机名master加端口50070的方式,原因在于没有在hosts文件里IP与主机名的映射,现在可以访问
http://192.168.1.103:50070
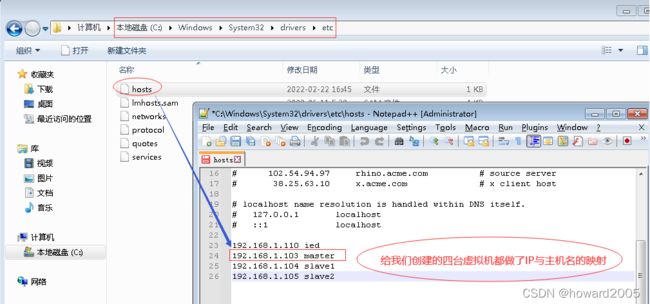
- 修改hw_win7虚拟机上的
C:\Windows\System32\drivers\etc\hosts文件
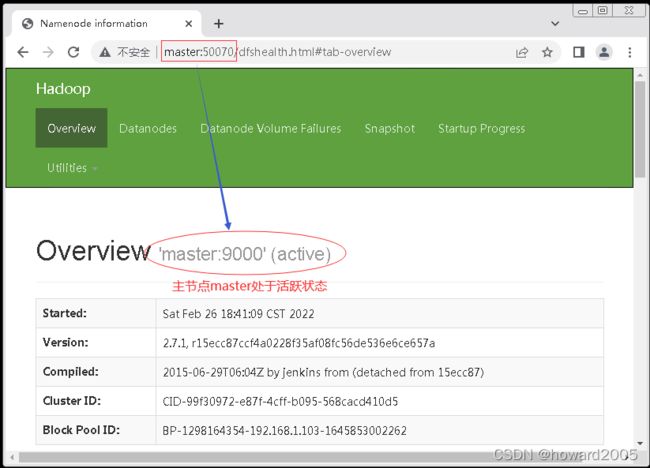
- 重启hadoop集群服务,访问
http://master:50070
- 查看数据节点信息
(3) 停止hadoop服务
- 在master虚拟机上执行命令:
stop-all.sh(相当于同时执行了stop-dfs.sh与stop-yarn.sh)

- 提示:
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh,说明stop-all.sh脚本已经被废弃掉了,让我们最好使用stop-dfs.sh与stop-yarn.sh。
(四)配置完全分布式Spark
1、在master主节点上安装配置Spark
(1)上传spark安装包到master虚拟机
- 利用rz将hw_win7虚拟机上的spark安装包上传到master虚拟机/opt目录
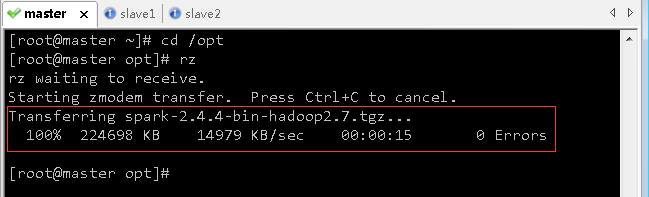
(2)将spark安装包解压到master虚拟机指定目录
- 执行命令:
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local

(3)配置spark环境变量
- 执行命令:
vim /etc/profile
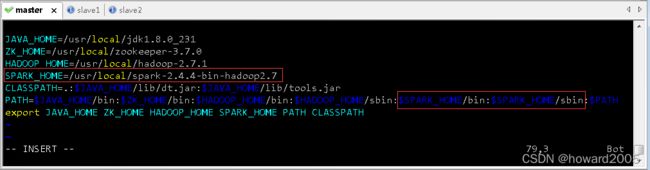
JAVA_HOME=/usr/local/jdk1.8.0_231
ZK_HOME=/usr/local/zookeeper-3.7.0
HADOOP_HOME=/usr/local/hadoop-2.7.1
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export JAVA_HOME ZK_HOME HADOOP_HOME SPARK_HOME PATH CLASSPATH
- 存盘退出后,执行命令:
source /etc/profile,让配置生效

- 查看spark安装目录

(3)编辑spark环境配置文件 - spark-env.sh
- 进入spark配置目录后,执行命令:
cp spark-env.sh.template spark-env.sh与vim spark-env.sh

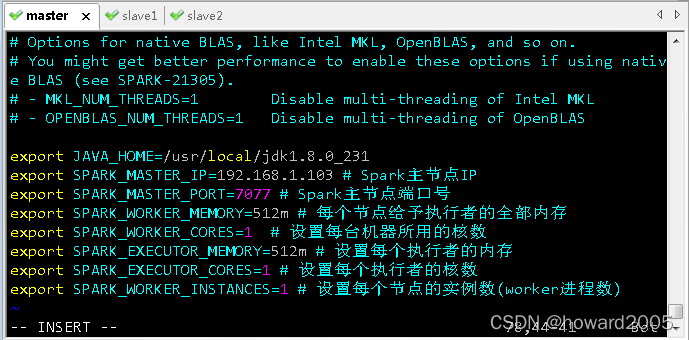
export JAVA_HOME=/usr/local/jdk1.8.0_231
export SPARK_MASTER_IP=192.168.1.103 # Spark主节点IP
export SPARK_MASTER_PORT=7077 # Spark主节点端口号
export SPARK_WORKER_MEMORY=512m # 每个节点给予执行者的全部内存
export SPARK_WORKER_CORES=1 # 设置每台机器所用的核数
export SPARK_EXECUTOR_MEMORY=512m # 设置每个执行者的内存
export SPARK_EXECUTOR_CORES=1 # 设置每个执行者的核数
export SPARK_WORKER_INSTANCES=1 # 设置每个节点的实例数(worker进程数)
- 存盘退出,执行命令:
source spark-env.sh,让配置生效

(4)创建spark缺省配置文件 - spark-defaults.conf
- 执行命令:
cp spark-defaults.conf.template spark-defaults.conf

- 执行命令:
vim spark-defaults.conf
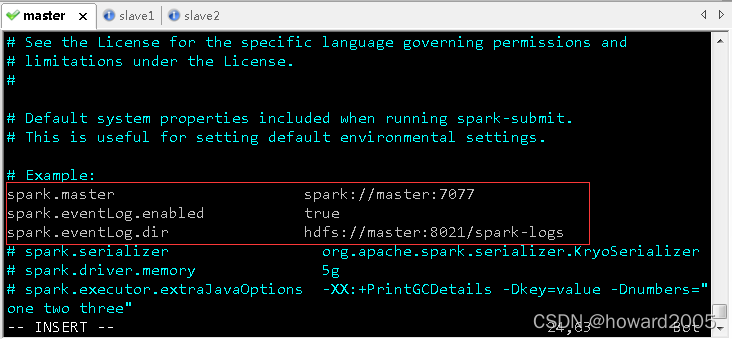
spark.master spark://master:7077 # 设置主节点
spark.eventLog.enabled true # 开启任务日志功能
spark.eventLog.dir hdfs://master:8021/spark-logs # 设置任务日志位置
(5)创建slaves文件,添加三个节点
- 执行命令:
vim slaves
- 存盘退出
2、在slave1从节点上安装配置Spark
(1)把master虚拟机上的spark安装目录远程拷贝到slave1虚拟机相同位置
- 执行命令:
scp -r $SPARK_HOME root@slave1:$SPARK_HOME

(2)将master虚拟机上环境变量配置文件分发到slave1虚拟机
- 在master虚拟机上,执行命令:
scp /etc/profile root@slave1:/etc/profile

- 在slave1虚拟机上,执行命令:
source /etc/profile

(3)在slave1虚拟机上让spark环境配置文件生效
- 执行命令:
source spark-env.sh

3、在slave2从节点上安装配置Spark
(1)把master虚拟机上的spark安装目录远程拷贝到slave2虚拟机相同位置
- 执行命令:
scp -r $SPARK_HOME root@slave2:$SPARK_HOME

(2)将master虚拟机上环境变量配置文件分发到slave2虚拟机
- 在master虚拟机上,执行命令:
scp /etc/profile root@slave2:/etc/profile

- 在slave2虚拟机上,执行命令:
source /etc/profile

(3)在slave2虚拟机上让spark环境配置文件生效
- 执行命令:
source spark-env.sh

(五)启动并使用完全分布式Spark
1、启动hadoop的dfs服务
- 在master虚拟机上执行命令:
start-dfs.sh
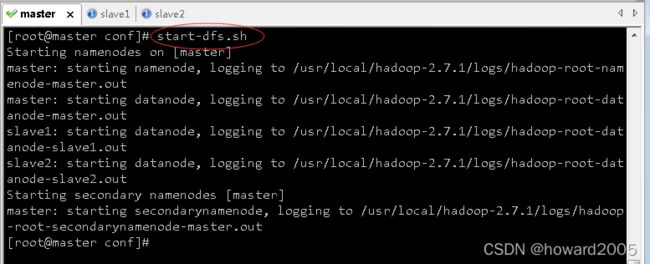
2、启动hadoop的yarn服务
- 在master虚拟机上执行命令:
start-yarn.sh
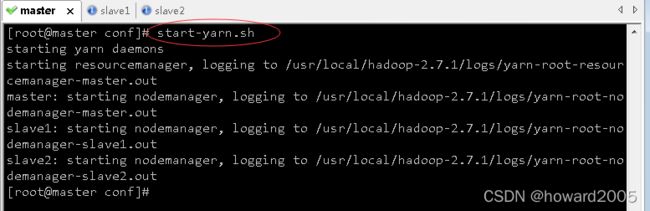
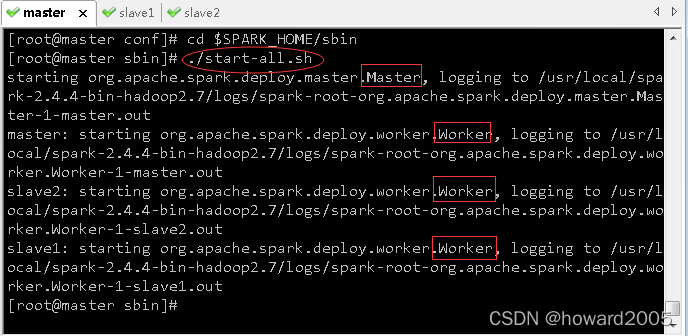
3、启动Spark服务
- 在master虚拟机上进入spark安装目录下的sbin子目录,执行命令:
./start-all.sh
- 执行命令:
./start-history-server.sh hdfs://master:8020/spark-logs,开启任务日志功能
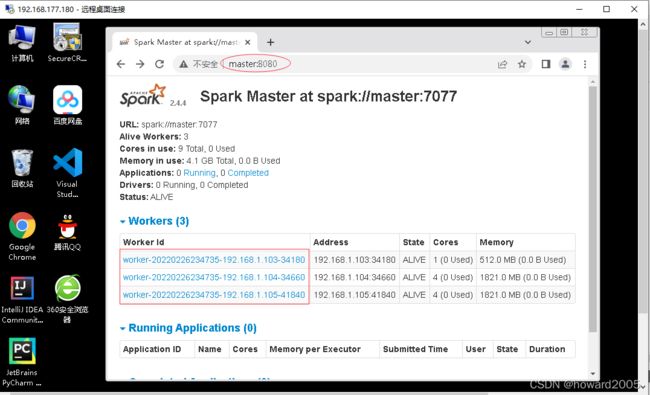
3、Spark监控 - 通过浏览器访问管理界面
-
在hw_win7虚拟机上,访问
http://master:8080
-
启动成功后,三个Worker都有
Id -
执行命令:
./start-history-server.sh hdfs://master:8021/spark-logs

-
历史服务器启动不了,因此无法访问
http://master:18080来查看任务日志
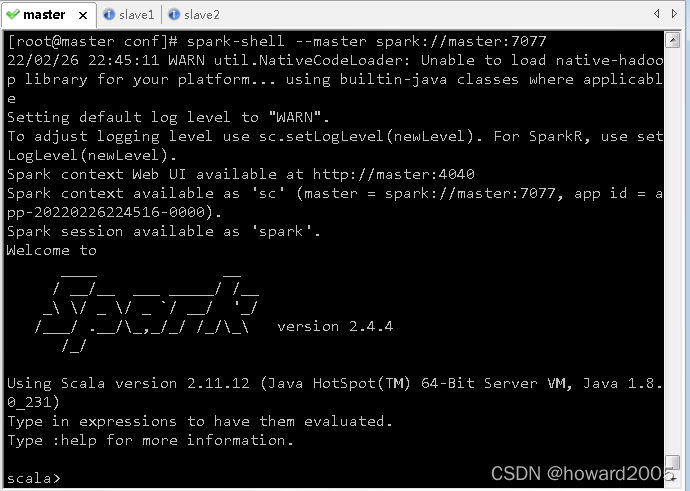
4、启动Scala版Spark Shell
- 执行命令:
spark-shell --master spark://master:7077
- 在/opt目录里执行命令:
vim test.txt

- 在HDFS上创建park目录,将test.txt上传到HDFS的/park目录

- 在其它虚拟机上也可以查看到该文件

- 读取HDFS上的文件,创建RDD
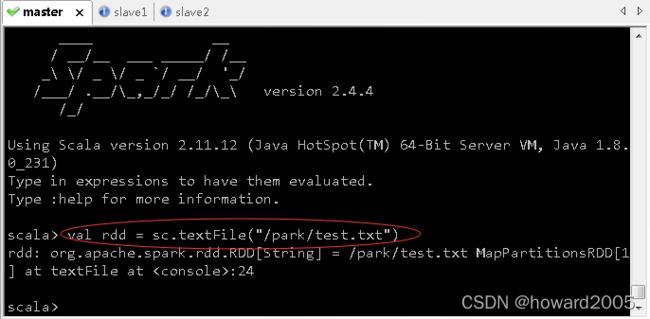
- 查看第一行内容
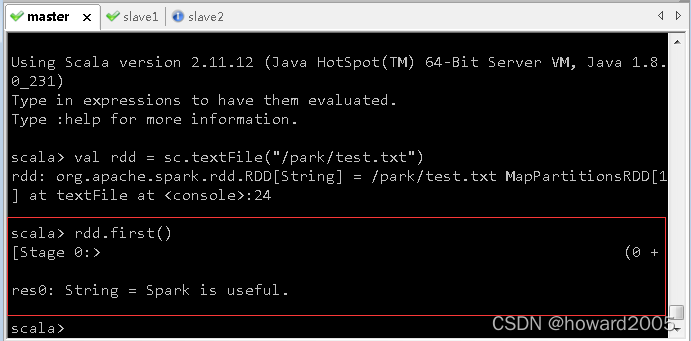
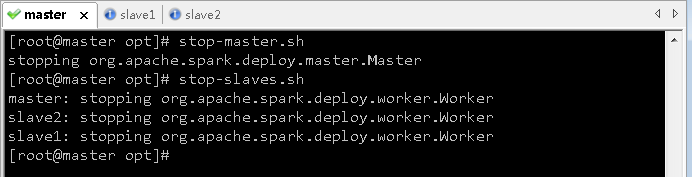
5、关闭spark服务
- 在master节点执行命令:
stop-master.sh与stop-slaves.sh