【Hive】Hive基础知识
文章目录
- 1. hive产生背景
- 2. hive是什么
- 3. hive的特点
-
- 3.1优点:
- 3.2 缺点:
- 4. Hive 和 RDBMS 的对比
- 5. hive架构
-
- 5.1 用户接口层
- 5.2 Thrift Server层
- 5.3 元数据库层
- 5.4 Driver核心驱动层
- 6. hive的数据存储(整理一)
- 7. hive的数据组织形式(整理二)
-
- 7.1 库
- 7.2 表
-
- 7.2.1 从数据的管理权限分
-
- 7.2.1.1 内部表(管理表、managed_table)
- 7.2.1.2 外部表(external_table)
- 7.2.2 从功能上分
-
- 7.2.2.1 分区表
- 7.2.2.2 分桶表
- 7.3 视图
- 7.4 数据存储
-
- 7.4.1 元数据
- 7.4.2 表数据(原始数据)
1. hive产生背景
先分析mapreduce:
mapreduce主要用于数据清洗或统计分析工作
并且绝大多数的场景都是针对的结构化数据的分析
而对于结构化的数据处理我们想到sql
但数据量非常大时,没办法使用mysql等,只能使用mapreduce
可是mapreduce的缺点是:编程不便、成本太高
hive的诞生:
如果有一个组件可以针对大数据量的结构化数据进行数据分析,但是又不用写mapreduce,直接用sql语句实现就完美了
所以hive就诞生了
直接使用 MapReduce 所面临的问题:
- 人员学习成本太高
- 项目周期要求太短
- MapReduce 实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
- 更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
- 更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
- 更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
那么hive可以完全替代mapreduce吗?
不可以,hive仅仅处理的是mapreduce中的结构化数据处理
会对xml、html解析等,比较困难
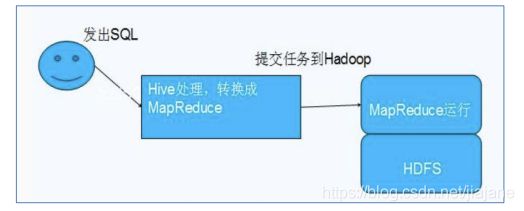
2. hive是什么
-
Hive 由 Facebook 实现并开源
-
是基于 Hadoop 的一个数据仓库工具
-
可以将结构化的数据映射为一张数据库表
-
并提供 HQL(Hive SQL)查询功能
-
底层数据是存储在 HDFS 上。
-
Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
hive的执行引擎mapreduce
hive实际上就是一个hadoop的上层应用
hive理解为hadoop的客户端 ,这个客户端支持sql编程
hive的底层中 保存很多的map reduce模板 执行一个sql语句的时候 会根据不同的sql语句的关键字(group by)将sql语句翻译为mapreduce任务进行执行 -
使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据
-
适用于离线的批量数据计算。
数据仓库之父比尔·恩门(Bill Inmon)在 1991 年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出的定义被广泛接受——数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行
所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce计算框架,对存储在 HDFS 中的数据进行分析和管理
数据库和数据仓库的区别:
- 概念上:
数据库更加善于数据的精细化的管理——>查询性能比较高
数据仓库更加善于数据的存储——>查询性能不高 ,一个hdfs的数据管理工具 将结构化数据映射为一张表进行管理 - 应用场景:
olap:Online Analytical Processing 联机分析处理 查询select
oltp:On-Line Transaction Processing 联机事物处理 insert update delete
数据库:联机事物处理 insert update delete
数据仓库:联机分析处理 select
hive中不支持delete update操作 - 事务的支持上:
数据库:mysql支持事务的
数据仓库:不支持事务 没有事务的概念的 - 读写模式:
数据库mysql:写数据的时候 进行检查 写模式
hive无严格模式
数据仓库:数据查询的时候会进行检查 读模式
3. hive的特点
3.1优点:
- 可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务
横向扩展:通过分担压力的方式扩展集群的规模
纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G - 延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
- 良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
3.2 缺点:
- Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结
果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作) - Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能
用在交互查询系统中。 - Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而
不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
4. Hive 和 RDBMS 的对比
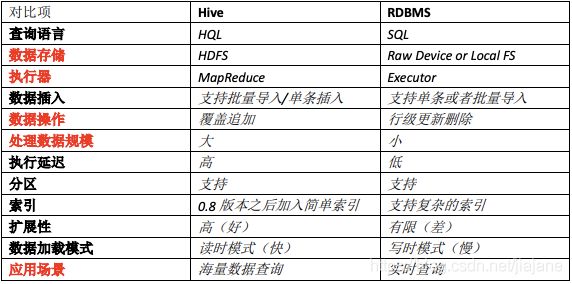
总结:Hive 具有 SQL 数据库的外表,但应用场景完全不同,Hive 只适合用来做海量离线数据统计分析,也就是数据仓库。
5. hive架构

5.1 用户接口层
hive提供3种方式连接:
- 客户端方式CLI
CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive进行交互,最常用(学习,调试,生产) - jdbc/odbc
是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过这连接至 Hive server 服务 - webUI
通过浏览器访问 Hive
没人用,配置繁琐、界面丑
5.2 Thrift Server层
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发,Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口
jdbc——>java语言去操作
5.3 元数据库层
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
- Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和外部表),表的数据所在目录
- Metastore 默认存在自带的 Derby 数据库中。
缺点就是不适合多用户操作,并且数据存储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程) - Hive 和 MySQL 之间通过 MetaStore 服务交互
5.4 Driver核心驱动层
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
- 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
- 编译器:编译器是将语法树编译为逻辑执行计划(mapreduce)
- 优化器:优化器是对逻辑执行计划进行优化
合并相同的mapreduce - 执行器:执行器是调用底层的运行框架执行逻辑执行计划
提交优化完成的mapreduce
执行流程:
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运行MetaStore 中的元数据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生一个 MapReduce 任务。
6. hive的数据存储(整理一)
- Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
- Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式(Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,\x01
Hive 的默认行分隔符:换行符 \n - Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建 - Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
- Hive 中的表分为内部表、外部表、分区表和 Bucket表
内部表和外部表的区别:
删除内部表,删除表元数据和数据
删除外部表,删除元数据,不删除数据
内部表和外部表的使用选择:
- 大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
- 使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
- 使用外部表的场景是针对一个数据集有多个不同的 Schema
- 通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
- Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的HashPartitioner 的原理类似
- 分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件,所以数据的准确性也高很多
7. hive的数据组织形式(整理二)
7.1 库
为了对数据进行模块化的管理(细化的管理)
不同的业务的数据最好存储在不同的数据库中
7.2 表
7.2.1 从数据的管理权限分
7.2.1.1 内部表(管理表、managed_table)
- hive的内部表的数据是hive自己具备管理权限的
- hive对自己的内部表具备绝对的管理权限的
- 管理权限主要指的就是表删除的权限
- hive中的内部表在进行删除的时候,元数据(表描述信息数据)和原始数据(表存储的数据)一并删除
7.2.1.2 外部表(external_table)
- hive的外部表中的数据只有使用权限没有删除权限
- hive的外部表可以理解为hdfs的数据的使用者
- 外部表在进行删除的时候
- 元数据 会被删除的
- 原始数据 不会被删除的 没有删除的权限
- 外部表的数据的管理权限hdfs决定 不是hive决定的
7.2.2 从功能上分
7.2.2.1 分区表
这里的分区不同于mapreduce的分区的
作用就是提升查询性能
当hive中的表的数据很大的时候,在进行查询的时候性能很低(进行的是全表扫描)
这个时候我们就可以对这个表以过滤的字段创建不同的分区,这个时候不同的分区的数据就会分开存储,在进行按照过滤字段查询的时候就不会全表扫描了
这里的分区指的是将原来的数据分为多个部分,分别存储在不同的目录下的,每一个目录存储的都是一个分区
如:
不创建分区表的时候
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info
所有数据全部存储在表对应的目录下
这个时候进行查询的时候都是全表扫描的
创建了分区 以过滤字段创建分区的时候(地点)
数据存储:
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/address=beijing/
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/address=dongbei/
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/address=neimeng/
这个时候进行查询 查询北京的人员信息
只会扫描hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/address=beijing/这个目录数据 不会全表扫描了
一个分区对应的就是一个存储目录
分区的标准 分区的依据字段——分区字段
查询的时候以分区字段进行查询 查询性能高
查询的时候不以分区字段进行查询 查询性能没有提升的
7.2.2.2 分桶表
同mapreduce中的分区
作用:
1)提升抽样性能
2)提升join性能
需要对数据进行抽样或join的时候,这个对表进行分桶
在分桶表中指定:
分桶字段----》mapreduce的分区字段
桶的个数---》mapreduce的reducetask的个数
默认分桶算法(mapreduce的分区算法)
分桶字段是非数值型:
分桶字段.hash%桶的个数
分桶字段是数值型的:
分桶字段%分桶个数
结果:
不同的桶的数据输出到不同的文件中
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info抽样:
3个桶 分桶字段年龄
age%3 name.hash%3
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/part-r-00000 第一个桶 余数0
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/part-r-00001 第二个桶
hdfs://hdp01:9000/user/hive/warehouse/bd1809.db/info/part-r-00002 第三个桶
样本数据抽样准则:数据足够分散
抽样---直接区一个桶 半个桶
做关联的时候 两个表的桶的个数相同或倍数关系
7.3 视图
hive中的视图只有逻辑视图没有物化视图
物化视图:将视图代表的sql执行结果
hive中的视图仅仅相当于一个sql语句的快捷键 别名
hive中的视图是为了提升hql语句的可读性
select from (
select * from (
select * from (
select ....from ..
)
)
)
select from (
select * from b_view
)
hive视图在查询视图的时候才会执行
7.4 数据存储
包含2部分信息 元数据 和 表数据(原始数据)
7.4.1 元数据
存储在mysql中
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/myhive?createDatabaseIfNotExist=true</value>
<description>元数据库mysql连接的url</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost,myhive>代表的是当前的配置的hive的在mysql中的元数据库的名字 -->
</property>
上面的参数决定的是hive的元数据库在mysql中的存储位置
myhive库就是元数据库
元数据库中的几个核心表:
-
hive的数据库的描述信息的元数据表DBS:
hdfs://hdp01:9000/user/hive/warehouse/test_bd1809.db test_bd1809 hadoop USER一条数据对应的是hive中的一个数据库
hive中创建一个数据库 这表中添加一条数据 -
hive的表的描述信息TBLS:
hive中一个表对应这里的一条数据
1(table_id) 1545036305 2(db_id) 0 hadoop 0 1 student MANAGED_TABLE(表类型) 0
这个表中的表类型字段 有3个值:
MANAGED_TABLE 管理表、内部表
EXTERNAL_TABLE 外部表
virtual_view 视图
默认的创建的表都是管理表 -
hive的字段描述信息COLUMNS_V2:
这里的一条数据对应的是hive表中的一个字段
1(表id) age int 3(字段顺序,从0开始 顺序递增的)
元数据可以修改的
hive中的表或库信息都是从元数据库读取的信息
元数据库的信息只要修改 hive的表或库的信息就会修改
但是表中的存储的数据不会变的 在hdfs存储的
7.4.2 表数据(原始数据)
存储在hdfs上的
默认的存储目录:/user/hive/warehouse
这个目录下依次建库的目录 表的目录
/user/hive/warehouse/bd1809.db 库的目录
/user/hive/warehouse/bd1809.db/student 表目录
参数:
hive.metastore.warehouse.dir
/user/hadoop/hive
hive的表的数据的hdfs存储位置配置
修改这个参数值修改的就是hive的原始数据存储的hdfs目录