2020-11-3 centos搭建hadoop完全分布式集群
centos搭建hadoop完全分布式集群
参考链接:
1.完全分布式Hadoop集群在虚拟机CentOS7上搭建https://blog.csdn.net/weixin_41627032/article/details/103328922
2.搭建Hadoop的伪分布式集群 https://www.panziye.com/bigdata/287.html
我是创建了三台虚拟机搭建的hadoop集群 可能也不是真正意义上的完全分布式集群
三台虚拟机的静态ip为(参考个人情况)
(如何设置静态ip见前面的博客)
192.168.58.140(用作master节点)
192.168.58.141(用作slave1节点)
192.168.58.142(用作slave2节点)
修改主机名称
(三台主机都修改)
通过hostnamectl set-hostname 新主机名命令修改三台主机(虚拟机)的主机名,修改后通过hostname命令查看是否修改成功
以master为例:(此张截图来源于参考链接2)
 输入vi /etc/hosts命令修改host文件(三台主机都改),加入主机的ip和主机名
输入vi /etc/hosts命令修改host文件(三台主机都改),加入主机的ip和主机名

重启三台主机 或者用xshell或者securtCRT重新链接后发现主机名称已改变

关闭防火墙
(三台都关闭虚拟机)
通过 firewall-cmd --state查看防火墙状态 running代表开启 not running代表关闭。![]()
通过systemctl stop firewalld.service命令关闭防火墙
通过systemctl disable firewalld.service命令禁止防火墙开机启动

在参考博客中有一个步骤是永久关闭selinux
![]()
将SELINUX=enforcing改成disabled wq!保存后重启虚拟机使之生效

新建HADOOP用户(三台主机都新建 而且用户和用户组都要相同)
输入adduser hadoop创建用户 passwd hadoop设置密码

查看用户信息
![]()

使用usermod -a -G hadoop hadoop把hadoop用户加入到hadoop用户组 前一个hadoop是用户组名 后一个是用户名
用cat /etc/group|grep hadoop查看结果
![]()
输入vi /etc/sudoers 将hadoop用户赋予root权限 从而可以使用sudo命令
输入hadoop ALL=(root) NOPASSWD:ALL

按esc后输入 :wq!强制保存退出
设置ssh免密登录
(三台主机)
使用hadoop用户重新登录虚拟机

此部分参考的链接1
配置免密登录基本原理就是,把自己的公钥(一串字符串)复制到别人的authorized_keys文件里,当一个主机要SSH连接另一个主机时,如果本机的authorized_keys文件存有那个主机的公钥,那么就不需要输密码,否则,就连主机SSH自己都要输密码。
需要让master节点自己对自己、自己对所有slave免密
让每一台slave节点都自己对自己、自己对master免密
对于master
进入cd ~/.ssh
执行ssh-keygen -t rsa生成密钥(连按3次回车),
对自身免密ssh-copy-id master
对所有从节点免密 ssh-copy-id slave1 ssh-copy-id slave2,
这个命令就是自动把公钥复制到指定主机的authorized_keys文件中去
对于slave1
进入cd ~/.ssh
执行ssh-keygen -t rsa生成密钥(连按3次回车),
对自身免密ssh-copy-id slave1
对master节点免密ssh-copy-id master
有需要也可以对slave2节点加密 ssh-copy-id slave2
对于slave2
进入cd ~/.ssh
执行ssh-keygen -t rsa生成密钥(连按3次回车),
对自身免密ssh-copy-id slave2
对master节点免密ssh-copy-id master
有需要也可以对slave1节点加密 ssh-copy-id slave1
如果ssh设置成功,那master与slave1、slave2之间是可以免密登录的,即不需要再输入密码

安装jdk
(三台都要)
安装 linux系统版本的jdk 我选择的是jdk11版本
若使用的secureCRT 可以通过SFTP上传![]()
从本地拖拽即可上传
上传结果
 在/usr下通过sudo mkdir java命令新建一个java文件夹
在/usr下通过sudo mkdir java命令新建一个java文件夹
![]()
将/tmp中的jdk压缩包通过sudo mv jdk-11.0.7_linux-x64_bin.tar.gz /usr/java命令将其剪切到java文件夹中
通过sudo tar zxvf jdk-11.0.7_linux-x64_bin.tar.gz 解压
![]()
设置jdk环境变量
通过sudo vi /etc/profile打开配置文件在最后输入以下内容
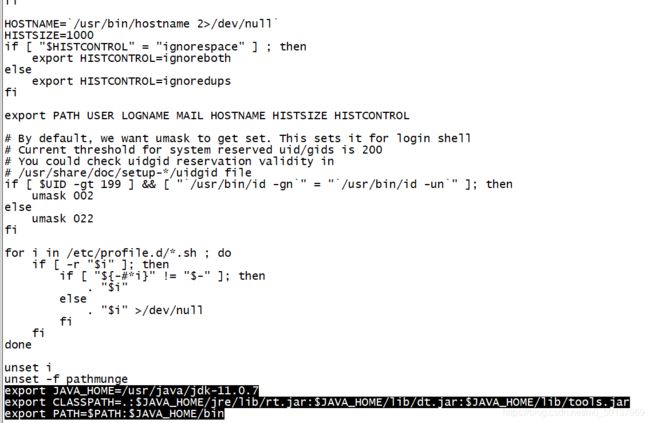
按esc后输入:wq! 强制保存退出
通过source /etc/profile更新环境变量,并通过 java -version 验证:

安装与配置HADOOP
下载的hadoop版本为:![]()
和安装jdk类似 在/usr目录下新建一个hadoop文件夹
![]()
通过secureCRT中的sftp将压缩包拖拽上传至/tmp文件夹中,并通过mv命令剪切至hadoop文件夹中并进行解压
![]()
hadoopdata在此忽略不要管
修改配置文件/etc/profile,增添以下内容

通过source /etc/profile更新环境变量
通过hadoop version验证

配置hadoop文件
(三台都要 )
主要配置以下四个文件(截图来自参考博客)

找到这几个配置文件:
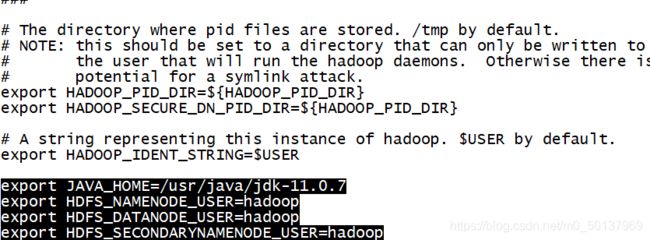
输入sudo vi hadoop-env.sh 修改hadoop-env.sh文件
添加以下内容:

输入sudo vi core-site.xml 修改core-site.xml文件
添加以下内容:
master、slave1、slave2都是 hdfs://master:9820
不用对应slave1、slave2去修改 反正我修改后 后面有点小问题
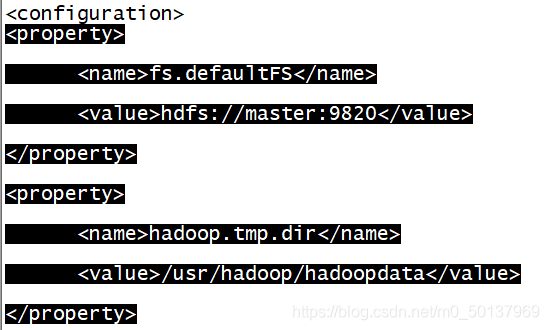
这里就出现了上面提到的hadoopdata 在后面执行集群的时候会自动创建这个文件夹 所以这个hadoopdata文件并不是解压出来的

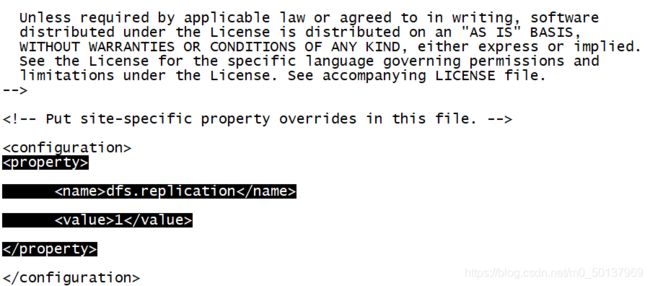
输入sudo vi hdfs-site.xml 修改hdfs-site.xml文件 ,添加以下内容:
![]()
输入sudo vi mapred-site.xml 修改mapred-site.xml文件 ,添加以下内容:
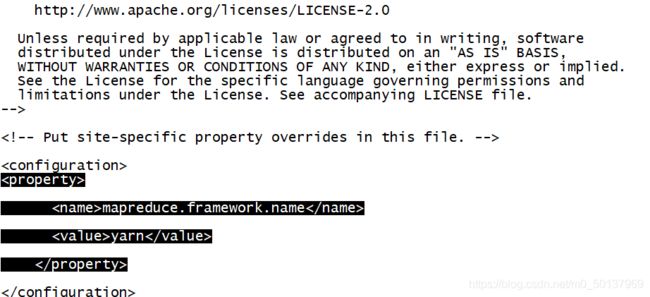

输入sudo vi yarn-site.xml 修改yarn-site.xml文件 ,添加以下内容:

输入sudo vi slaves修改slaves文件 ,添加以下内容:
(注:slaves文件只对master节点有用 ,有几个slave节点就写几个)

启动与验证环境
这时所有的节点必须开机!
输入sudo chmod -R 777/usr/hadoop 将/usr/hadoop目录赋予777权限,否则后面HDFS格式化可能出错
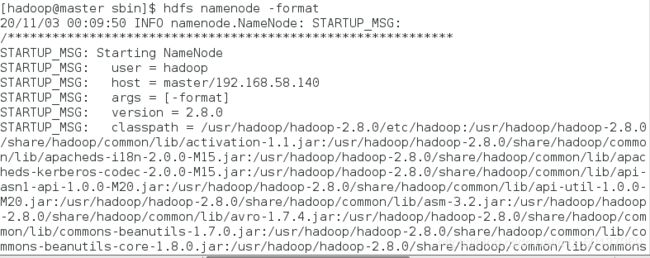
首先要在master节点上格式化hdfs系统
hdfs namenode -format
在master节点的/usr/hadoop/hadoop-2.8.0/sbin 开启hadoop集群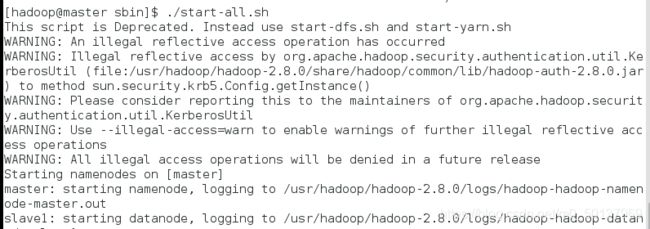
分别在所有节点执行jps命令验证是否成功
(也可以通过ssh免密登录在一台主机操作)

此时说明运行成功。
可进一步验证:
在master主机的浏览器 输入http://192.168.58.140:50070
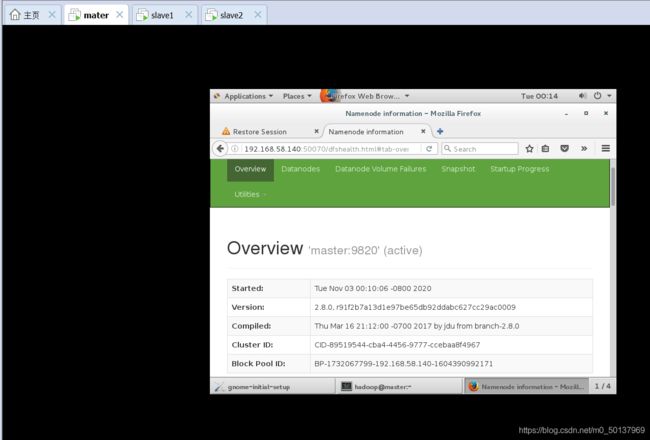
点击DATANODE:

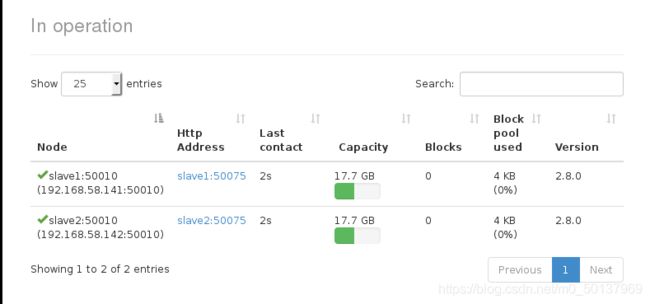
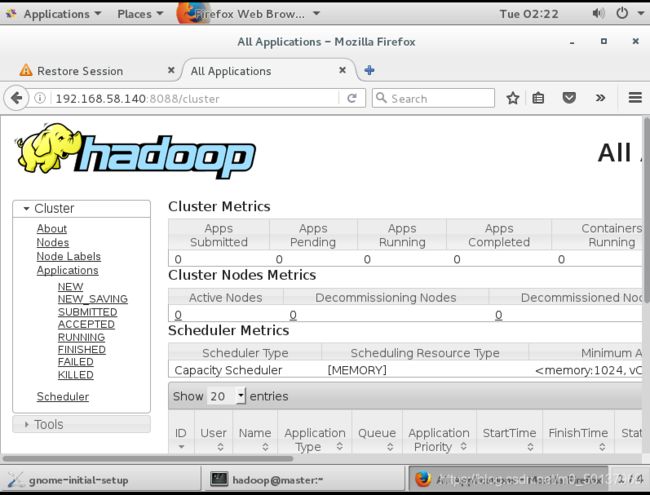
输入http://192.168.58.140:8080/cluster可看到YARN的ResourceManager界面
来自参考博客提示
如果集群启动后,jps命令给出的结果与正确的不符,比如少了一个或多了一个,那么大多就需要重新格式化,重新格式化不是再执行一遍hdfs namenode -format那么简单,需要把所有节点下的/usr/hadoop/hadoopdata目录的结构按照上面说到的方式重新建立,即把之前的都删了,重新建文件夹。(重建之前记得关闭集群) 之后再格式化、启动
关闭集群./stop-all.sh
![]()